Codeforces 798D Mike and distribution - 贪心
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Codeforces 798D Mike and distribution - 贪心相关的知识,希望对你有一定的参考价值。
Mike has always been thinking about the harshness of social inequality. He‘s so obsessed with it that sometimes it even affects him while solving problems. At the moment, Mike has two sequences of positive integers A = [a1, a2, ..., an] and B = [b1, b2, ..., bn] of length n each which he uses to ask people some quite peculiar questions.
To test you on how good are you at spotting inequality in life, he wants you to find an "unfair" subset of the original sequence. To be more precise, he wants you to select k numbers P = [p1, p2, ..., pk] such that 1 ≤ pi ≤ n for 1 ≤ i ≤ k and elements in P are distinct. Sequence P will represent indices of elements that you‘ll select from both sequences. He calls such a subset P "unfair" if and only if the following conditions are satisfied: 2·(ap1 + ... + apk) is greater than the sum of all elements from sequence A, and 2·(bp1 + ... + bpk) is greater than the sum of all elements from the sequence B. Also, k should be smaller or equal to 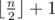 because it will be to easy to find sequence P if he allowed you to select too many elements!
because it will be to easy to find sequence P if he allowed you to select too many elements!
Mike guarantees you that a solution will always exist given the conditions described above, so please help him satisfy his curiosity!
The first line contains integer n (1 ≤ n ≤ 105) — the number of elements in the sequences.
On the second line there are n space-separated integers a1, ..., an (1 ≤ ai ≤ 109) — elements of sequence A.
On the third line there are also n space-separated integers b1, ..., bn (1 ≤ bi ≤ 109) — elements of sequence B.
On the first line output an integer k which represents the size of the found subset. k should be less or equal to 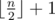 .
.
On the next line print k integers p1, p2, ..., pk (1 ≤ pi ≤ n) — the elements of sequence P. You can print the numbers in any order you want. Elements in sequence P should be distinct.
5
8 7 4 8 3
4 2 5 3 7
3 1 4 5
题目大意 给定两个长度为n的数列,选出不多于个互不相同的下标,使得每个数组对应下标的数的和的两倍超过它的和。
显然贪心,我有很多稀奇古怪的想法,然后全都完美Wrong Answer。突然觉得自己可能一直用的都是假贪心,给这道题跪了。下面说正解吧。
这个可以看成二维贪心,对于高维问题我们通常想到的是降维,再根据常用套路,降维通常用的两种方法:排序和枚举一维。
因为这里是贪心,所以显然排序。
题目要求还可以转化成,选择一些下标,在每个数组中,被选择数之和比剩下的数的和大。
首先选择A[1],然后之后每两个分为一组,每组中哪个对应的B大就选哪个。如果n为偶数,再把最后一个选上。
显然在B数组中是满足题目要求的(每组中都选了最大的,还多选了1个或2个),对于A数组,每个选择了A[i]一定大于等于下一组内选择的A[j],而且会多选1个或2个,所以A数组也满足。
Code
1 /** 2 * Codeforces 3 * Problem#798D 4 * Accepted 5 * Time: 62ms 6 * Memory: 4500k 7 */ 8 #include <bits/stdc++.h> 9 using namespace std; 10 typedef bool boolean; 11 12 typedef class Data { 13 public: 14 int id; 15 int x; 16 int y; 17 }Data; 18 19 int n; 20 int *A, *B; 21 Data *ds; 22 23 boolean cmp(const Data &a, const Data& b) { return a.x > b.x; } 24 25 inline void init() { 26 scanf("%d", &n); 27 A = new int[(n + 1)]; 28 B = new int[(n + 1)]; 29 ds = new Data[(n + 1)]; 30 for(int i = 1; i <= n; i++) 31 scanf("%d", A + i), ds[i].x = A[i], ds[i].id = i; 32 for(int i = 1; i <= n; i++) 33 scanf("%d", B + i), ds[i].y = B[i]; 34 } 35 36 vector<int> buf; 37 inline void solve() { 38 sort(ds + 1, ds + n + 1, cmp); 39 buf.push_back(ds[1].id); 40 for(int i = 2; i < n; i += 2) 41 buf.push_back((ds[i].y > ds[i + 1].y) ? (ds[i].id) : (ds[i + 1].id)); 42 if((n & 1) == 0) 43 buf.push_back(ds[n].id); 44 printf("%d\n", (signed)buf.size()); 45 for(int i = 0; i < (signed)buf.size(); i++) 46 printf("%d ", buf[i]); 47 } 48 49 int main() { 50 init(); 51 solve(); 52 return 0; 53 }
以上是关于Codeforces 798D Mike and distribution - 贪心的主要内容,如果未能解决你的问题,请参考以下文章