python 继承与类属性的使用
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python 继承与类属性的使用相关的知识,希望对你有一定的参考价值。
看图中的注释,理解有错吗
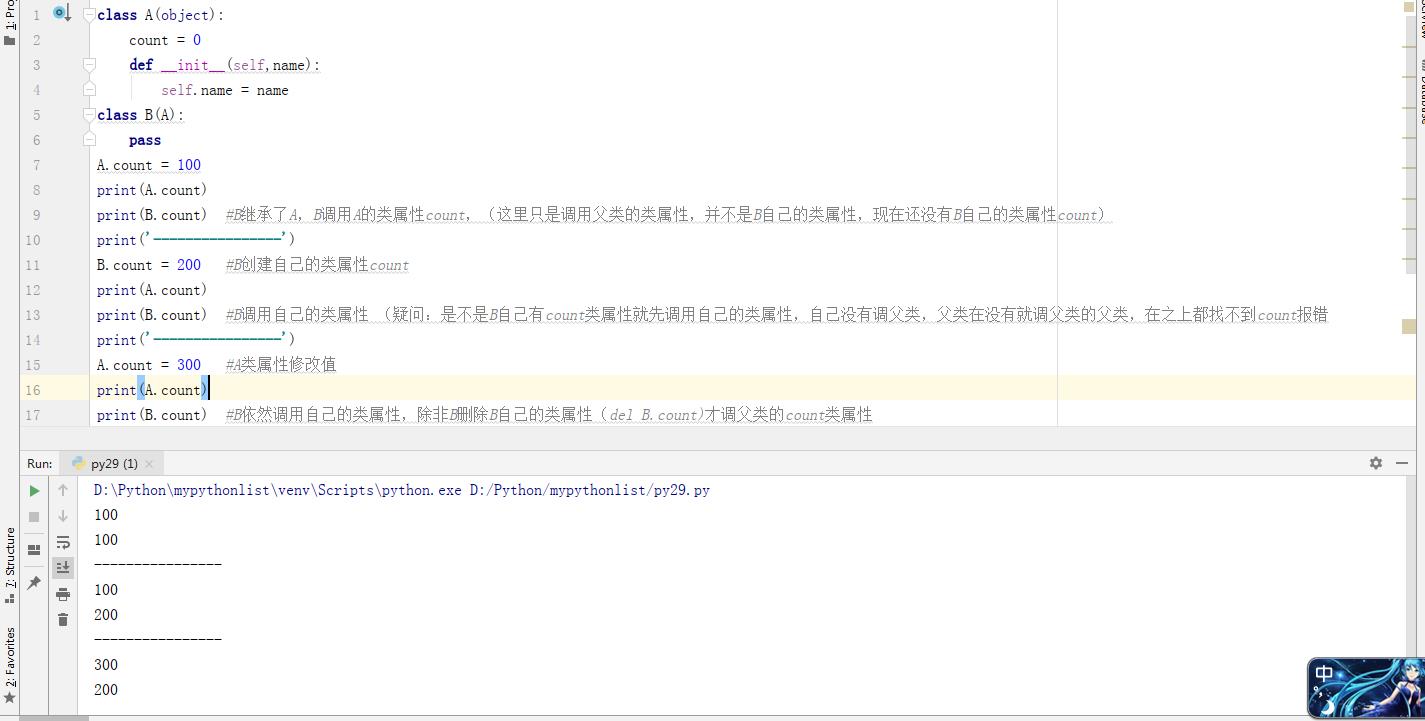
子类继承父类后,会自动继承了父类的属性。如果在子类中修改了继承得来的类属性时(即B.count=200),并不会修改父类的对应的同名类属性(A.count)。以后只要是通过子类访问该属性,访问的都是子类的属性。
通过父类修改了父类属性后,子类访问该属性时,会访问父类修改后的属性值。当然前提是子类没有对该属性重新赋值过。追问
你好,还有个疑惑,就是python类中的__dict__,这个是方法还是什么?,比如我创建个A类,里面有实例方法,实例属性,类方法和类属性
print(a.__dict__) #a是A类的实例化对象,用__dict__是只打印实例属性吗,不打印实例方法,类方法和类属性的字典
print(A.__dict__) #A是个类,用__dict__打印了实例方法,类方法,类属性的字典
以上理解对吗
__dict__是属性,不是方法。你说的两点是对的。你可以参考这个链接__dict__用法
追问谢谢
参考技术A 理解是可以的 还是需要有自己的理解 参考技术B 可以这么理解[Python]-8-对象与类(下)
引言
这篇文章介绍Python如何将函数与数据整合成类,并通过一个对象名称来访问它们。
文章目录
0×9.类的多重继承
0×10.定制类
0×11.枚举类
0×12.动态类
0×9.类的多重继承
python中的类提供了多重继承的功能,比如C类可以继承B类同时又能继承A类,C类能够使用B和A类所有属性和方法,请看下面的实例:
#!/usr/bin/env python
#coding=utf-8
########
class A(object):
def _Print_website(self):
print("www.qingsword.com")
########
class B(object):
def _Print_HelloWorld(self):
print("Hello World")
########
#多重继承只需要在子类括号中用逗号分隔需要继承的类即可
class C(A,B):
def __init__(self):
self.name="qingsword"
#因为C类同时继承了A和B类,所以它的实例可以使用A和B类所有方法和属性
x=C()
x._Print_website()
x._Print_HelloWorld()
print(x.name)
#程序输出
www.qingsword.com
Hello World
qingsword0×10.定制类
当我们实例化一个类对象后,使用print打印这个类对象,往往会打印出一个类名称和内存地址,请看下面的实例:
#!/usr/bin/env python
#coding=utf-8
########
class A:
#--------
def __init__(self,name="qingsword"):
self.name=name
x=A("www.qingsword.com")
print(x)
#程序输出
<__main__.A object at 0x7f41d6039f28>为了让打印输出更加的友好,python提供了两个函数__str__和__repr__,前者可以让print打印一个对象时,输出这个函数下定制的返回信息;后者是在调试过程中让调试程序(IDLE提示符环境等)在直接输入对象时,能够打印出我们定制的信息,这两者通常写入相同的返回信息,例如,将上面的实例更改如下:
#!/usr/bin/env python
#coding=utf-8
########
class A:
#--------
def __init__(self,name="qingsword"):
self.name=name
#--------
def __str__(self):
"""定制对象返回信息"""
return "Class A Object self.name=%s"%self.name
#直接让repr函数等于str
__repr__=__str__
x=A("www.qingsword.com")
print(x)
#程序输出
Class A Object self.name=www.qingsword.com除了定制对象的输出信息外,如果一个类要用作for循环,Python提供了一个__iter__方法,该方法返回一个迭代对象,可使用for循环迭代这个对象,for会不断调用该对象的__next__()方法拿到循环的下一个值,直到遇到StopIteration错误(或break)退出循环,可以将一个类定制成可迭代类,请看下面的实例:
#!/usr/bin/env python
#coding=utf-8
########
class Fib(object):
#--------
def __init__(self):
self.a,self.b=0,1
#实例本身就是迭代对象,所以iter函数返回自己
def __iter__(self):
return self
#如果对象中的a属性值大于20,就停止循环,否则返回每次循环中得到的a值
def __next__(self):
self.a,self.b=self.b,self.a+self.b
if self.a>20:
raise StopIteration()
return self.a
x=Fib()
for y in x:
print(y)
#这是一个斐波拉契迭代类,程序输出如下
1
1
2
3
5
8
13
#如果删除类中的self.a>20的判断,可以将for循环更改成
for y in x:
#可以手动指定一个迭代范围
if y<20:
print(y)
else:
break上面的可迭代类看起来更像是一个生成器,但现在我们还无法像列表那样使用一个索引来取得单个值,为此python提供了一个__getitem__方法,用于实现取得单个值的类,修改上面的程序如下:
#!/usr/bin/env python
#coding=utf-8
########
class Fib(object):
#根据输入的n,返回x的值
def __getitem__(self,n):
#x和y只是函数中的一个局部变量,每次调用函数,都会被重新设置成1
x,y=1,1
while n>0:
x,y=y,x+y
n-=1
return x
x=Fib()
print(x[2])
print(x[12])
#程序输出
2
233如果想要给这个类添加一个切片功能,可以修改上面的代码如下:
#!/usr/bin/env python
#coding=utf-8
########
class Fib(object):
def __getitem__(self,n):
#判断传入的是一个分片类型还是一个索引值
if isinstance(n,int):
x,y=1,1
while n>0:
x,y=y,x+y
n-=1
return x
elif isinstance(n,slice):
#获取分片的起始值
start=n.start
stop=n.stop
if start is None:
start=0
x,y=1,1
L=[]
for a in range(stop):
if a>=start:
L.append(x)
x,y=y,x+y
return L
x=Fib()
print(x[12])
print(x[:12])
print(x[6:12])
#程序输出
233
[1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144]
[13, 21, 34, 55, 89, 144]上面这个简单的分片器并没有对负数和分片步长做处理,仅仅是提供一个思路,告诉大家,通过这种定制函数,可以将一个类定制成任何数据类型,可以是列表字典元组等等。
通常情况下,我们调用一个对象的某个属性和方法时,如果这个属性和方法不存在,就会报错,如下所示:
#!/usr/bin/env python
#coding=utf-8
########
class A(object):
def __init__(self):
self._path=""
x=A()
#调用_path没有问题
print(x._path)
#但调用一个不存在的sub属性就会报错,提示sub属性不存在
print(x.sub)python提供了一个__getattr__函数,它接收一个不存在的属性或方法名称,然后返回一个我们设定的值,如果我们没有定义返回值,它将返回一个None,这比直接抛出一个错误要友好的多,请看下面的实例:
#!/usr/bin/env python
#coding=utf-8
########
class A(object):
def __init__(self):
self._path=""
def __getattr__(self,attr):
if attr=="blog":
return "www.qingsword.com"
elif attr=="doit":
return "ok"
#一个函数返回值
elif attr=="age":
return lambda :23
x=A()
print(x.blog)
print(x.doit)
print(x.age())
print(x.nothing)
#程序输出
www.qingsword.com
ok
23
None请注意__getattr__函数只有当类中没有定义这些属性值时才接收他们,并且根据我们自己的判断返回值,如果类中有这些属性或方法,则会优先使用它们,另外,如果这个函数接收到了一个没有定义返回值的名称,默认返回None,除非手动抛出一个AttributeError,比如,在if的末尾添加下面的代码,再次运行就会抛出一个异常,提示nothing不存在:
else:
raise AttributeError("错误的属性或方法名:%s"%attr) __getattr__最常见的应用就是链式调用,请看下面的实例:
#!/usr/bin/env python
#coding=utf-8
########
class A(object):
def __init__(self,path=""):
self._path=path
print(\'self._path is %s\' % self._path)
def __getattr__(self,attr):
return A("%s/%s"%(self._path,attr))
def __str__(self):
return self._path
__repr__=__str__
x=A()
print(x.www.qingsword.com)
#程序输出
#x=A()初始化时的输出
self._path is
#x.www时因为没有www属性,调用了__getattr__函数,并且传递了一个www,然后递归调用A,这一步相当于A("/www")
self._path is /www
#x.www.qingsword会再次激活__getattr__函数,因为www并没有qingsword属性,以此类推
self._path is /www/qingsword
self._path is /www/qingsword/com
/www/qingsword/com我们在实例化一个对象的时候,可以通过"对象名.属性名"来使用其中的属性,或者通过"对象名.方法名()"来调用其中的方法,除此之外,python提供了一个__call__函数,这个函数允许对象调用自身,请看下面的实例:
#!/usr/bin/env python
#coding=utf-8
########
class A(object):
def __init__(self,name="qingsword"):
self.name=name
def __call__(self):
print("My name is %s"%self.name)
x=A()
#直接调用对象自身,就相当于执行了对象内的__call__函数,就好像x本身是一个函数而不是类对象一样
x() #输出"My name is qingsword"
#我们可以通过callable()函数来判断一个对象是否可调用,这个函数返回一个布尔值,如果我们注释掉A类中的call函数,那么下面的第一句就会返回False,大家可以尝试一下
print(callable(x)) #True
print(callable(str)) #True
print(callable([1,2,3])) #False0×11.枚举类
Python3.0之后,提供了一个枚举类型,弥补了Python2没有枚举的不足,首先来看一个简单的枚举实例:
#!/usr/bin/env python
#coding=utf-8
#导入枚举模块
from enum import Enum
#定义一个枚举变量m
m = Enum(\'Month\', (\'Jan\', \'Feb\', \'Mar\', \'Apr\', \'May\', \'Jun\', \'Jul\', \'Aug\', \'Sep\', \'Oct\', \'Nov\', \'Dec\'))
#使用不同的方法获取枚举中的名称和值,和列表不同,枚举的索引是从1开始的
print(m(1)) #Month.Jan
print(m.Mar) #Month.Mar
print(m["Oct"]) #Month.Oct
print(m.Mar.value) #3
#打印出枚举中所有的名称
x=len(m.__members__) #获得枚举个数
for i in range(1,x+1):
print(m(i))
#程序输出
Month.Jan
Month.Feb
Month.Mar
Month.Apr
Month.May
Month.Jun
Month.Jul
Month.Aug
Month.Sep
Month.Oct
Month.Nov
Month.Dec
#获取枚举成员名称和全名,m.__members__.items()会将枚举分割成一个列表,每个元素都为一个元组,每个元组中又包含一个字符串和一个字典类型,分割后的列表大概是这个样子[("Jan",<Month.Jan:1>),("Feb",<Month.Feb:2>)....],然后使用name接收第一个参数(Jan),member接收第二个参数(<Month.Jan:1>),member可以访问键,用member.value可以访问值
for name, member in m.__members__.items():
print(name,\'=>\',member,\',\',member.value)
#程序输出
Jan => Month.Jan , 1
Feb => Month.Feb , 2
Mar => Month.Mar , 3
Apr => Month.Apr , 4
May => Month.May , 5
Jun => Month.Jun , 6
Jul => Month.Jul , 7
Aug => Month.Aug , 8
Sep => Month.Sep , 9
Oct => Month.Oct , 10
Nov => Month.Nov , 11
Dec => Month.Dec , 12了解了枚举的创建和访问方法后,再来看看枚举类的创建方法:
#!/usr/bin/env python
#coding=utf-8
from enum import Enum,unique
@unique #unique装饰器可以确保枚举中没有重复值
class Week(Enum):
"""继承枚举类,可以指定每个名称的值"""
Sun=0 #将起始索引设定成0
Mon=1
Tue=2
Wed=3
Thu=4
Fri=5
Sat=6
#访问方法同枚举
print(Week(0))
print(Week.Sat.value)
print(Week["Thu"])
#程序输出
Week.Sun
6
Week.Thu在Python3中,枚举类经常用于定义常量,因为枚举中每个名称对应的值是不可变的,例如:
#!/usr/bin/env python
#coding=utf-8
from enum import Enum,unique
@unique
class const(Enum):
"""常量枚举类"""
website="www.qingsword.com"
author="qingsword"
pi=3.1415
print(const.website.value)
print(const("qingsword"))
print(const["pi"].value)
#程序输出
www.qingsword.com
const.author
3.14150×12.动态类
动态语言和静态语言在创建类的时候也有所不同,动态语言类的创建是在程序执行后才依次执行类中的语句,动态化创建一个类,而静态语言是在编译时就已经创建了这些类;我们在使用type判断一个类的类型时,往往看到类的类型是type,这又与动态类的创建有什么关系呢?请看下面的实例:
#!/usr/bin/env python
#coding=utf-8
########
class A(object):
def Website(self):
print("www.qingsword.com")
x=A()
print(type(A))
print(type(x))
#程序输出,从输出中可以看到,x是A类的一个实例,但A类本身却是一个class type
<class \'type\'>
<class \'__main__.A\'>实际上type方法不仅可以判断对象的类型,python还可以使用它来动态创建类,而使用type动态创建的类与直接使用class创建的类效果是一样的,这就是为什么上面type判断A类的类型是class type的原因,实际上两者可以看做同一种类型,下面的实例演示了如何通过type动态创建一个类:
#!/usr/bin/env python
#coding=utf-8
def Website(self):
print("www.qingsword.com")
def SayHello(self,name="qingsword"):
print("Hello %s"%name)
#B指向一个Type动态创建的类,所以B就代表这个类(A)本身
#type的语法:
#type("类名",(继承类列表,...),dict(类方法名=绑定的方法名,...))
#使用这种方法我们就可以动态的将外部的方法绑定到一个类中,从而在运行时创建一个类
B=type("A",(object,),dict(web=Website,hello=SayHello))
x=B()
print(x)
print(type(B))
x.web()
x.hello("xxx")
#程序输出
<__main__.A object at 0x7f7d70821048>
<class \'type\'>
www.qingsword.com
Hello xxx以上是关于python 继承与类属性的使用的主要内容,如果未能解决你的问题,请参考以下文章