江湖救急:请问谁有Depthmap软件,或者知道哪里有下载的,请告知~~
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了江湖救急:请问谁有Depthmap软件,或者知道哪里有下载的,请告知~~相关的知识,希望对你有一定的参考价值。
参考技术A http://www.spacesyntax.net/software/在这个网站,右边register先注册,organization/institution我就写的是一个中国大学里的建筑学院(当然是英文),注册好立刻就可以下载了。
这个链接是ucl官网介绍depthmap时给的。 参考技术B 看到淘宝上有卖,不过要5元~ 参考技术C 同求啊 657096722@qq.com 万分感谢啊 参考技术D 我也想要!!! 第5个回答 2012-07-29 我也想要啊。。。。。要是有谁知道麻烦也告之一下吧,谢谢了!
江湖救急笔记——NOSQL
声明:
·以功利的角度记笔记,有些太难/自己觉得考不到/太累的懒得记的点会记得比较简单!
·能力有限,并不能100%保证正确。如果有不同的看法和认识一定要自己思考!
·这门课没有明确的考点,所以很多东西是我觉得重要就写上了……似乎这门课会有很多半开放的设计类题目(瞟到过几眼往年)
·word文档粘贴的,估计会有一些奇奇怪怪的地方……
目录
第一章——NOSQL概述
一、4V理论
·规模Volume
数据量大,从TB到PB到EB
·速率Velocity
对实时处理要求高
·多样Variety
除了结构化数据,还有大量非结构化数据(文本、音视频)
·价值Value
价值密度低,但经过提纯后总价值高
二、大数据思维
·全样而非抽样
·效率而非精确
·相关而非因果(有争议)
三、关系数据库VS NOSQL
1.两种数据库对比
| 关系型数据库 | 非关系型数据库 | |
| 数据规模 | 以MB或GB为单位 | 直接上GB、TB甚至PB(SQL你就是个弟弟) |
| 数据类型 | 类型单一,数据结构化 | 种类繁多,数据经常是半结构化、非结构化 |
| 模式与数据 | 先有模式后有数据 | 模式在数据出现之后才能确定,甚至是不断变化的 |
| 如何看待数据 | 仅作为被处理的对象 | 数据要辅助解决诸多问题 |
| 处理工具 | 几种工具就可以应对 | 很难有适应多数场景的工具 |
2.关系数据库的优势
·通用性
·优秀的数据一致性
·最小冗余
·可以进行复杂查询(如连接)
·成熟的技术
3.关系数据库的劣势
·难以在分布式环境中扩展:为了保持强一致性,写操作需要集中在主服务器上,但是这就造成了巨大的负担,而且分布式系统下的连接操作更是极度头疼
·对一个大表,建立索引、更改属性花的时间很长,在这期间表会长时间上锁
·字段不固定时会关系数据库就很难应对,改变字段会耗时,预留字段又容易混淆且白白占用空间
·进行简单的查询仍需要解析SQL语句,虽然不代表会很慢,但是这额外的开销是不必要的
4.NoSQL数据库特点
·易于分散和扩展(因为本来就没有join操作……)
四、去IOE
去掉IBM的小型机(X86)、Oracle数据库(开源数据库)、EMC存储设备(云端)
五、数据模型发展
·结构化模型
层次模型、网状模型、关系模型、E-R模型、面向对象模型
·半结构化模型
XML、JSON、图模型
·OLAP分析模型
ROLAP、MOLAP
·大数据模型
NOSQL、NewSQL

第二章——NOSQL理论基础
在分布式系统下,为了保证数据的安全,我们需要进行“冗余存储”——即在各个独立的物理节点上存储多个副本,这就需要维持分布式系统上的数据一致性
一、ACID
ACID代表了四个单词,它是关系型数据库的事务特性
1.原子性Atomicity
事务中的操作要么全都做,要么全都不做
·由恢复系统实现
2.一致性Consistency
事务完成前后要保持一致性,某些状态不应改变(典型就是转账前后的总金额)
·由并发控制系统实现
3.隔离性Isolation
各个并发的事务之间不能互相影响,各个事务之间应该就好像彼此不存在一样
·由并发控制系统实现
4.持久性Durability
一旦事务提交,对数据库的影响必须是永久的
·由恢复系统实现
二、CAP
·CAP定理:在一个分布式系统中,强一致性Consistency、可用性Availability、分区容错性Partition Tolerance三者不可兼得。
1.强一致性Consistency
指分布式系统中,所有的数据备份在同一时刻有相同的值
一旦系统对某一个写操作返回成功,那么后续的所有读操作都应该读到这个值;返回失败则所有读操作都不会读到它
2.可用性Availability
每个请求都可以在一定时间内得到响应。这个响应可以是成功,也可以是失败,也不需要确保返回最新的信息
3.分区容错性Partition Tolerance
分布式系统常常划分在多个子网下,每个子网是一个区。这些区在网络故障等情况下会无法彼此交换信息。
分区容错性指在网络中断、消息丢失,部分分区因此挂掉的情况下,系统整体对外也能提供保持强一致性或可用性的服务
4.不同原则的取舍结果
·CA——放弃分区容错性
这代表着需要将所有数据放到同一台机器上(以确保不需要检查分布式系统的其它副本),这是当下关系数据库的选择,扩展性不强
·CP——放弃可用性
一旦遇到网络中断等情况,就让受影响的服务不对外服务了,等待数据恢复一致
·AP——放弃一致性
在网络故障时,让各个受影响的分区继续使用本地数据来保证高可用性,但使得系统不一致。
当然,放弃C并不代表不再具有一致性,而是降格为“最终一致性”
·实际情况
由于实际的分布式系统几乎无法避免网络硬件引起的网络连接问题,所以P必须被保证。通常要在C和A中放弃一个。
对于很多互联网服务,我们要保证用户能快速实时地进行操作,可以选择放弃C
对于金融(钱)的领域,C和A都非常需要保证,这时就不得不放弃P,故障时不对外服务
也就是说:
CA:传统关系数据库思维
CP:MongoDB、Redis、Hbase
AP:互联网应用
三、BASE
BASE模型不同于ACID,它放弃强一致性,换来可用性
它是在CAP理论上,对C和A进行权衡的结果,因为我们可以看到可用性也是“基本可用”。它选择放弃强一致性,并根据业务特征尝试完成最终一致性。
1.基本可用Basic Available
允许损失一些可用性,但是系统仍需要可用。毕竟可用性是“一定时间”内返回,还是可以有操作空间的
比如:可以延长响应时间,或者在高峰期将用户从部分功能引导到等待页面。
2.软状态/柔性事务Soft-state
我们允许系统中不同节点的数据存在不一致的“中间状态”,即同步过程允许存在延时
3.最终一致性Eventual Consitency
所有数据副本在经过一定时间同步后可以达到一致,但不需要保证实时的强一致性
4.与ACID的对比
| ACID | BASE |
| 强一致性 | 弱一致性 |
| 隔离性 | 注重可用性 |
| 采用悲观方法 | 采用乐观的策略 |
| 不易变通 | 简单、快速、易变通 |
5.eBay模式
BASE的一种实现,eBay模式会借助一个消息日志来异步地完成分布式任务
使用一个更新记录表来保证被操做过的更新不被重复执行
·现在某一个本地数据库完成本地需要做的操作并产生一条消息日志
·然后读取消息队列,通过读取更新记录来判断这个操作是否被执行过。如果没有执行过就执行,执行成功后更新更新记录表,同时从消息队列中删除这个消息。
四、数据一致性实现技术
1.Paxos协议
一种不追求值的正确性、权威性、及时性,只追求一致性的分布式一致性算法
·值:这里的“值”可能指某个数值,也可能指某个命令等等含义
·Paxos协议的角色
- 提议者Proposer:
处理客户端请求,并将请求发送到集群里,相当于发起一个提议,决定这个值是否被批准
- 批准者acceptor:
处理接收到的提议,回复自己的决定,会存储一些状态来决定是否批准提议中的值
- 学习者learner:
学习那些被批准的值,但不能学习任何未被批准的值
·一个节点可以担当多个角色
·两个原则
安全原则——保证不做错事,某个实例的表决不会出现第二个值覆盖第一个值的情况,也不会出现学习未批准的值的情况
存活原则——只要有多数服务器存活并且彼此间可以通信最终都要做到:1.最终批准某个被提议的值;2.一个值被批准,那么其他节点都会学习这个值
·批准提议的规则
R:当提议被大多数批准者批准,则该提议被批准
P1:一个批准者必须接受它所收到的第一个提议
**不同的接收者可能会收到不同的值,且各种值数目相当,没有多数派
*所以规定半数以上的接收者接受就可以认为提议被批准,每个接收者都可以接受多个提议,每个提议都有全局层面的一个不重复id
P1a:一个Acceptor只要尚未承诺过任何编号大于n的Prepare请求,就接受这个编号为n的提议。
P2:如果一项值为v的提议被批准,那么后续只批准值为v的提议 (即允许有多个提议被批准,但是这些提议必须拥有相同的值)
*P2a:如果一项值为v的提议被批准,那么acceptor后续只接受值为v的提议(在P2之上更进一步,在批注阶段之前的接受阶段截住)
**如果有提议者提出了于已批准的提议值不同的提议,那就会导致P1和P2a的冲突
*P2b:如果某个提议被批准,那么之后任何提议者都只能提出具有相同值的提议(解决P1与P2a的冲突)
P2c:对于任意的n和v,如果[n, v]被提出,那么肯定存在一个由半数以上(majority)的接收者组织的集合S,满足下面两个条件之一:
(a) S中不存在任何接受过编号小于n的提议的接收者;
(b) S中所有接收者接受的编号小于n的提议中编号最大的提议的value为v。
·Paxos协议算法主体
引入“承诺”:承诺了一个编号为n的提议,代表后续不会再接收编号小于等于n的提议
·阶段1
Proposer选择一个编号n,向半数以上的acceptor发送编号为n的prepare请求
Acceptor接受到的prepare(n),如果n大于已经承诺过的所有prepare请求的编号,就将已经接受过的编号最大的提议作为承诺返回给proposer,同时这个acceptor也会承诺不再接受小于n的提议(或prepare)
·阶段2
如果proposer收到了半数以上的acceptor对n返回的承诺,就会发送一个[n,v]的接受请求给半数以上acceptor(v为返回的所有承诺中,编号最大的提案的v;如果全为null则自选)
如果acceptor收到了一个编号为n的accept请求,只要它没有对编号大于n的prepare请求做出过承诺,就接受它,并返回自己接收了请求的信息
在这之后,如果proposer能接收到超过半数的接受请求的信息,就结束了,将信息发给learner
如果未超过半数,就需要重新发送n值不同的prepare了
·持久存储
为保证宕机恢复后,节点仍能正常参与Paxos,必须存储:
·proposer存储发送过的最大的prepare编号,最大的accept编号
·acceptor存储承诺过的最大编号,已接受的编号最大的提议的编号和value
·learner存储自己学习过的提议和编号
·Paxos活锁
两个proposer A和B,它们交替进行:
A发动accept,由于有节点在之前接受了来自B的编号更大的prepare而失败,紧接着A发动了编号更大的prepare
B又赶在A发动下一次accept之前,先发动了accept,这也由于有些节点接受了更大的prepare失败(来自A),然后紧接着发动了更大的prepare
就此死循环
·解法1:要求proposer在一段随机时间后才能再次发动accept或随机改变编号增长幅度
·解法2:选取主proposer,只有它们才能发送proposer

五、NOSQL数据库水平扩展
1.水平扩展基础
·随数据量增加,垂直扩展(指提升服务器性能)会变得既难又贵,所以我们要水平扩展——将数据库运行在更多机器的集群上
这么做可以处理更大的数据请求,故障时获得更高的可用性(崩了一部分还能用嘛),但是系统会更复杂
2.分片与复制
·分片
将数据划分,不同的节点存不同的数
这是基于这样的考虑:数据库访问量虽大,但不同的应用程序其实很可能访问不同的数据。
我们分片时应当让经常一起访问的数据分在一起
·分片和分区
关系数据库提供的分区是对单个服务器上的单个数据库进行操作,与分片有本质不同
|
| 分片(Sharding) | 分区(Partition) |
| 存储依赖 | 可以跨越数据库 | 可以跨越表空间 |
| 数据划分 | 基于时间、范围、面向服务等 | 基于范围、Hash、列表等 |
| 存储方式 | 分布式 | 集中式 |
| 扩展性 | Scale Out | Scale Up |
| 可用性 | 无单点问题 | 存在单点问题 |
| 价格 | 低廉 | 昂贵 |
| 应用场景 | 互联网应用,Web2.0等 | 管理系统 |
·复制
一份数据复制到多个节点上
·主从复制:一个主节点负责处理更新,从节点都只负责读操作。这可能会遇到一致性问题,且主节点宕机需要重选一个主节点。
·对等复制:不分主从,谁都可以负责更新或读。这种情况的一致性问题更大
·分片与复制同用
进行分片,每个分片会对应一个主节点,并且还要按照复制系数复制出多个片。节点故障的话还需要将丢失的片转移到其他节点上
3.分片的数据划分方式——一致性哈希
一致性哈希的本质是一个负载均衡算法
普通hash在添加节点时的更改会很大,一致性哈希改进了这一点
·算法核心需求
节点和数据都进行哈希,通过比较节点和数据的哈希来分配数据
同时,我们要保证加入或移除存储节点时移动的数据应当最少,这点要求有一个衡量指标——单调性
单调性:当有新的节点加入时,必须要让有数据能映射到新节点,但又不会让数据被重新映射到其他旧的节点上
·算法思路
·step1:
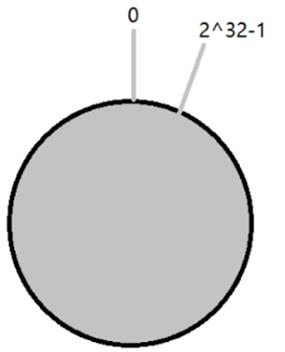
创造一个环形hash空间,通常是32位的数值空间(也就是0~2^32-1)
·step2:
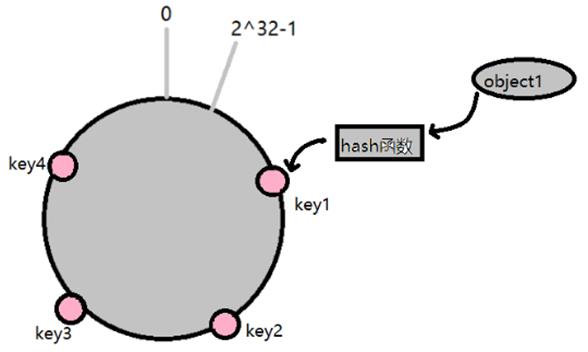
将全部数据使用hash函数映射到环上
·step3:
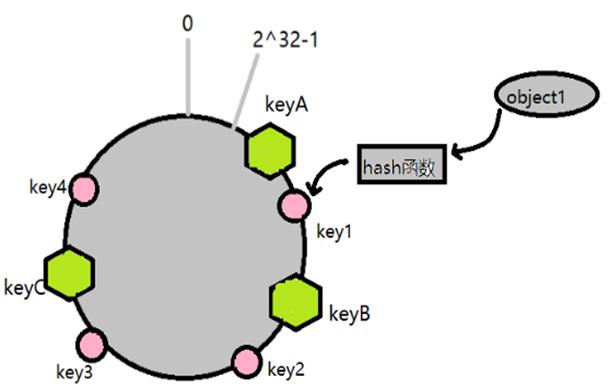
把所有存储映射到环上,我们可以选择使用IP地址输入hash函数
·step4:
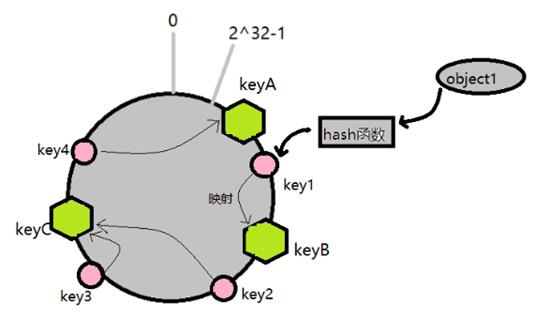
将数据顺时针旋转(也就是不断循环增大啦),直到遇到一个存储器为止
·step extra 新增:
添加一个存储器时,我们对它hash。
这个时候,我们需要重新映射的数据是:从新的存储器,到逆时针寻找到的第一个存储器之间。只有它们需要重新映射到新服务器上。
·step extra 移除:
移除一个存储器时,只有它本来存储的数据需要重新映射(也就是从这个存储器,到逆时针寻找到的第一个存储器之间)
·虚拟节点
哈希算法本身并不能保证绝对的平衡,尤其是存储少时。我们可以引入虚拟节点机制来尝试解决这个问题
我们可以让一个存储对应多个哈希值,这样一个存储设备在哈希环上就有了两个点,滑到这两个点的数据都归它存储。更多的哈希值就代表更有偏向于存储平衡
存储的虚拟哈希可以通过在IP中添加后缀来产生
第三章——文档数据库
以一个类似于对象的“文档”作为存储单元
其典型MongoDB是最接近关系型数据库的NoSql数据库
一、MongoDB数据组织模型
1.逻辑结构
由数据库、集合、文档逐层构成
| 关系型数据库 | 文档数据库MongoDB |
| 数据库database | 数据库database |
| 表table | 集合collection |
| 行/元组 row/tuple | 文档document |
| 列/属性 column/attribute | 域field |
| 索引index | 索引index |
| 连接join | 不支持连接 |
| 主码primary key | 主码 _id:object_id |
2.MongoDB的数据类型
除了常有的数据类型,还有传统关系数据库中没有的数据类型
·Arrays:列表
·Object:对象,即文档内嵌
·Object_ID:专门用于创建文档ID的对象ID类型
·Binary Data:二进制数据
·Code:代码类型,用于存储JavaScript代码
3.MongoDB的存储
·预分配
MongoDB始终保持额外的空间和空余的数据文件,预分配的文件用0填充。这个机制可以有效缓解数据暴涨引起的问题
·加倍的数据文件
数据文件每新分配一次数据文件,下一个数据文件就会是上一个大小的两倍,但不超过20G。这样可以保证小的数据库不会占用过多空间,大的数据库也可以通过加倍的机制获得足够的预留空间
·命名空间
每个集合和索引都有命名空间,命名空间的元数据存在.ns文件中
4.MongoDB的优劣
·优势
·模式自由,增删属性的代价更低,不需要关系模式与应用程序间的一致问题
·易扩展:面向文档的数据模型易扩展,开发者可以专注业务逻辑
·高性能:支持索引,内存管理工作直接交给OS,动态查询优化器会记住最高效的查询方式
·管理便捷:主服务器宕机系统自动选择备份服务器升格为主服务器,且启动服务器后不需要额外的管理
·不足
·不支持join
·对事务支持差
·数据更新并非实时写入磁盘,可能丢失数据
·预留空间会随存储数据增多而不断增大,也是负担
5.适用场景
·大宗低价值数据
·来自网站的数据(网站数据往往非结构性)
·缓存(因为性能好)
·高伸缩度的,对分布式存储需求大的场景(MongoDB内置对MapReduce的支持)
·JSON或对象类数据的存储
二、MongoDB模式设计
MongoDB不是没有模式设计的
在关系数据库中需要拆表的操作,在MongoDB中可以通过不同程度的内嵌/信用文档来实现。
内嵌文档是直接将全部内容写成一个文档,引用则是将object_id存入以代替存储大量实际内容,数据存入另一个集合
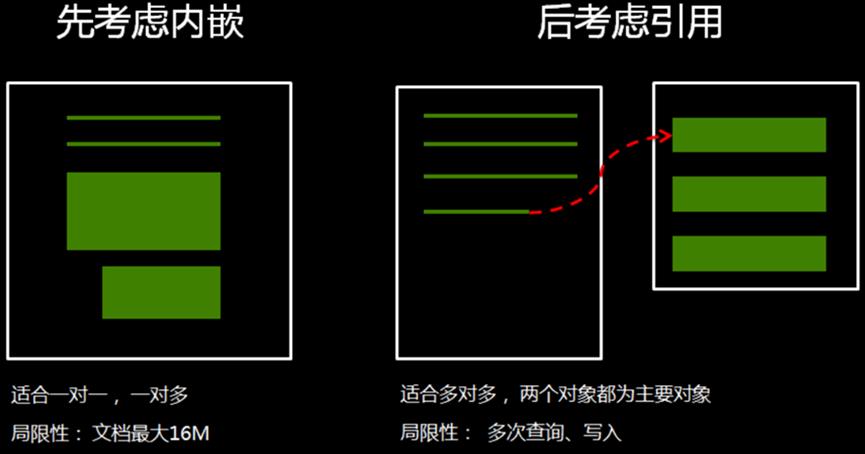
越偏向完全内嵌,查询性能就越好(只需要在一个集合内查询),但更新性能就越差(需要遍历这个大集合而不是一个只存储了需要更新的信息类别的小集合)
越偏向完全引用,更新性能就越好(只需要遍历一个小的集合),但查询性能就越差(需要查询多个集合)
也可以结合两者,在引用的基础上将经常需要查询的字段内嵌
第四章——Key-Value数据库
Key-Value数据库以键值对为存储的基本单位。对于文档数据库来说,一个文档才是一条有意义的数据,单个键值对没有意义。但是对于Key-Value数据库来说,一个键值对就是有意义的。
Redis选择将数据存储内存中,同时也支持持久化,定期将数据转到磁盘上
一、Redis数据组织模型
1.Redis数据模型
Key使用非二进制安全的字符串
Values十分单一,以二进制安全的字符串string作为主力类型,并且支持LIST,SETS,HASH,ZSET等集合类型
这里的字符串并不是纯的字符串,它不仅是Redis设计的二进制安全字符串,同时也可以存储数字
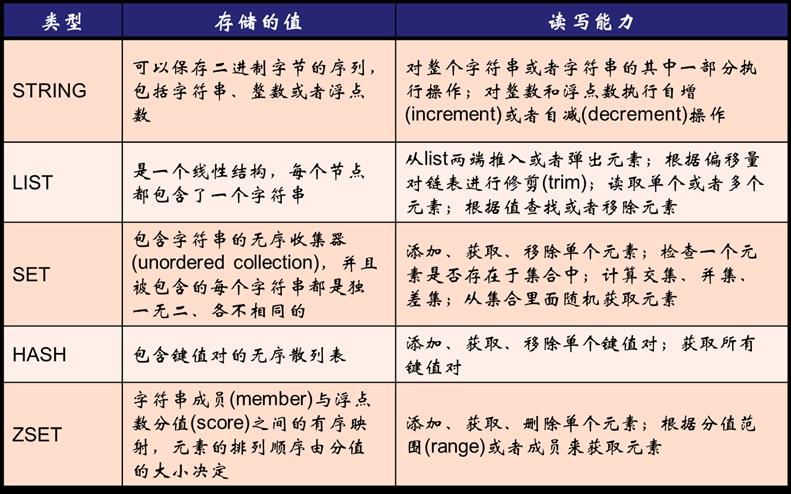
2.简单动态字符串SDS
普通的C字符串以空字符串\\0为结尾,而Redis的SDS有一个SDSHDR表头,存放了空闲空间free,已用空间len和缓冲区buf属性。借助这些属性,SDS不需要用任何特殊字符表示字符串的结尾
·优点
·获取字符串长度更快(直接读取属性而不是像C读取整个字符串)
·杜绝缓冲区溢出(记录free空间,在拼接字符串前可以检查)
·减少内存分配(有预分配空间的机制)
·二进制安全(不依赖文件特殊字符进行分割,字符串不需要顾忌\\0的问题)
3.Key与Value
·key
是C的原生字符串,不能使用换行、空格等符号
可以预先约定格式,比如冒号分割之类的
Key长度应适中,太长影响性能,太短不能达意
二、Redis持久化
1.快照
默认开启,隔一段时间就将内存中的所有数据保存一份到硬盘里
(可以配置为若m秒内有n个key被修改就存一次)
缺点是仍有可能丢失数据,且数据量大时不太合适
2.aof(append-only file)
Redis将每一个写操作都通过write函数追加到文件里,Redis重启时通过这个文件重构数据库
这样不容易丢失数据,但aof文件可能会很大,且重构是会因为文件过大而很慢
3.主从复制
Redis采用主从复制,主节点负责写操作,从节点负责读操作,主节点定期为所有节点更新。主从复制允许从节点间彼此连接。
Redis主从初连接时进行全量复制,之后尽量进行增量复制。从节点可以随时发起全量复制
三、事务
·事务
只保证一个client的一个事务的命令可以连续执行,其他client的命令无法插入
事务中的命令出现语法错误,整个事务就会被拒绝;
事务运行时出现了只有运行中才能被发现的错误,其余命令还会正常执行。
·乐观锁
依赖版本号实现。读数据同时读取版本号,操作完成写回数据时再比较一次版本号,要是没变就成功,变了就失败,不再写入。
四、Redis使用场景
·Redis速度顶尖,适合高并发、海量、高扩展需求这样对性能需求高的数据存储
·但是Redis对事务的支持很薄弱,也没有复杂的结构支持。对事务要求高的,对结构和复杂查询有要求的数据就不适合
第五章——图数据库
关系数据库需要连接才能处理联系,但是关系数据库的多重连接性能极差。更不要说其他的NoSQL数据库也不天生存在联系的概念了
图数据库的理念天生善于处理联系,他的数据模型本身就是基于数据和数据联系的
Neo4j是最流行的图数据库
一、Neo4j的数据组织模型
1.基本存储概念
Neo4j的基本存储概念为节点和边。节点和边都有属性的概念。
节点表示实体,边代表实体间的联系。不同节点被边联系起来,形成一个复杂的图。
由于数据的构成是图,所以顺理成章地支持了BFS和DFS。
2.存储内容
·属性:Neo4j以键值对象征属性
·标签:(不是一个键值对)可以用于表征节点性质的一个内容,同时也便于查询
一个节点可以有若干个标签和若干属性
一个联系有方向、名字、开始节点、结束节点、名字、属性
3.事务
Neo4j的事务是ACID级别的,这也是Neo4j的重要竞争力
有锁有日志,所有事务被表示为内存对象
4.可用性
使用主从集群,写操作会频繁地从主节点复制到从节点,任何时刻主节点和一些从节点都会有最新的副本
5.可扩展性
Neo4j和关系型数据库一样有延迟问题,索引帮助找到前几个对象,后续要遍历查找
二、Neo4j的模型设计
1.易理解
一个好的Neo4j数据库设计应该易于理解,从某个起始点开始阅读应当能组成一个完整的语义
2.可查询
应当满足用户的查询需求
三、Neo4j应用场景
图数据库是一种对联系特化的数据库,在知识图谱领域有很大作用
第六章——列族数据库
列式存储(column-based storage)是相对于传统关系数据库的行式存储(Row-based storage)说的
行式存储是一整行的内存存在一起,而列式存储是将整列的数据存在一起
行存储擅长更新数据,但在读取数据时经常会读到不必要数据;列存储擅长读取某一个属性的数据,但不擅长更新元组
一、列族数据库的数据压缩
行存储不像列族存储这样这么容易出现重复值以供压缩
1.行程长度编码算法
将有序序列中的若干个连续且相同的值压缩为一个三元组:
(值,首次出现位置,出现次数)
2.位向量编码
将一个列中的所有值相等的数据转化为一个二元组:
(值,指明出现位置的位向量)
比如(1,01001)代表值1在第二行和第五行出现了
3.字典编码
维护一个键值与字符串的字典,从而将字符串转化为一个短编码
二、HBase存储模型
1.HBase的基础特征
·HBase的更新
实质是通过插入一个列对应的新版本来达到更新的功能,旧版并不会被删除
·HBase的列族
每个列族由几个文件保存,不同列族必定由不同文件保存
2.存储模型
让我们来看看这个图,并依次解释各个名词
主键Row key:HBase表的主键,表中的记录按照行键排序,行键用来检索记录的主键
时间戳TimeStamp:代表这条的更新时间,是一种版本号概念
列族Column family:一个列族可以由多个列构成,且无需事先定义类型和数量。创建表时是必须要指明列族的
概念层就可以看出:一个列族中存储了许多列-值的对应
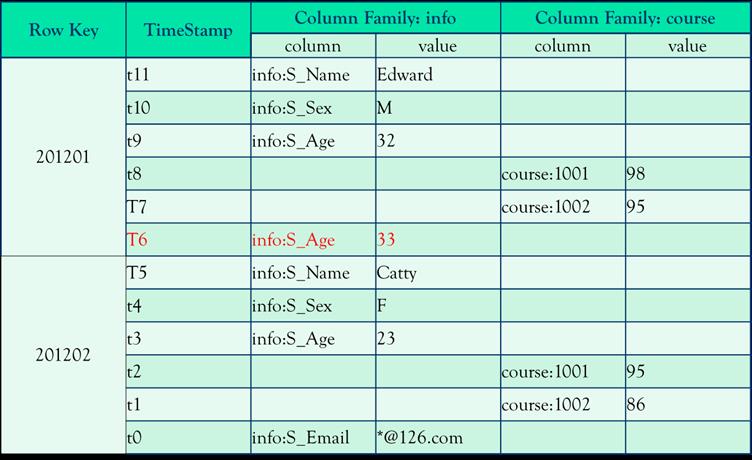
虽然看上去有许多的空值,但是不知道还记不记得之前说过:不同的列族是存在不同文件中的,物理层的存储长这个样子
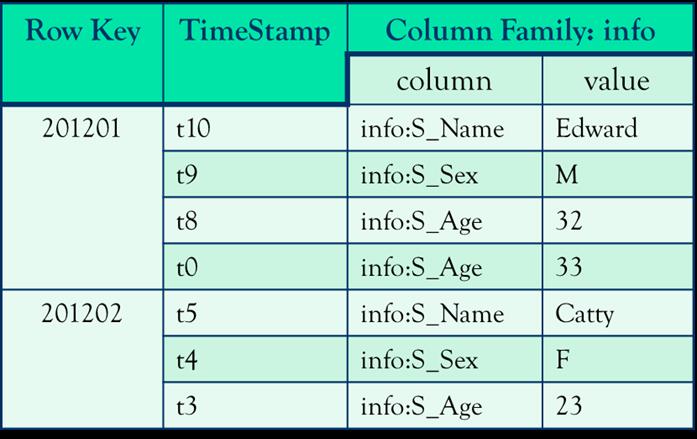
只能通过row key访问表,默认返回最新的记录
3.物理实现
·HRegion
将表按row key取值分割,存储为多个HRegion
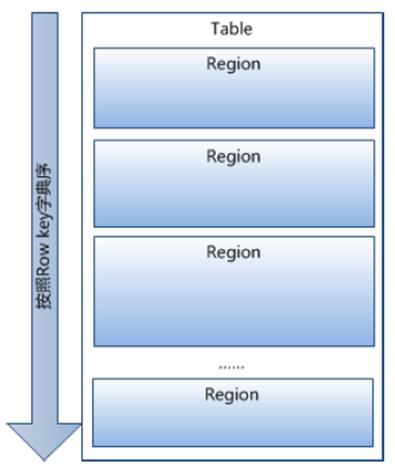
HRegion会根据大小分割,每个表初始只有一个HRegion,增大到阈值(默认为256MB)后就分割
HRegion是分布式系统中存储的最小单元,不同节点的存储单位都是HRegion
·HStore
HRegion不是底层存储的最小单位,HRegion由多个HStore组成,每个HStore存一个列族(也就是说有几个列族存几个HStore)
每个HStore又由
以上是关于江湖救急:请问谁有Depthmap软件,或者知道哪里有下载的,请告知~~的主要内容,如果未能解决你的问题,请参考以下文章
为啥java.exe进程总是占用很高的CPU?~~江湖救急啊!
AutoCAD卸载不干净,auto Uninstaller需要密钥,请问谁有auto Uninstaller注册机或者免密的软件