常用包
Posted speak out now.
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了常用包相关的知识,希望对你有一定的参考价值。
util
.concurrent.atomic
atomic指原子的:
atomic包下的类有:
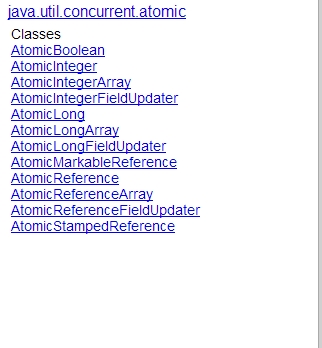
AtomicBoolean:
unsafe.objectFieldOffset(属性名):获取某属性相对于对象空间中起始地址的偏移量。
compareAndSet(current,next):我认为内存中V的值应该/预期为A,如果是将V更新为B。否则不更新,并告诉内存中V的实际值为多少。current需要先调用get()方法取得内存中被volatile修饰的值。
CAS无锁算法:
要实现无锁的非阻塞方法有多种,CAS是一种有名的无锁算法。
CAS语义:我认为内存中V的值应该/预期为A,如果是将V更新为B。否则不更新,并告诉内存中V的实际值为多少。
JDK1.后,在运行CAS的平台上,运行时把它们编译为相应的机器指令,如果处理器/CPU不支持,那么JVM将使用自旋锁。
流
流(流数据):流最初是通信领域使用的概念,表示\'传输中的数据信息的数字编码信号序列\'。之后有人将流定义为\'只能以事先规定好的顺序被读取一次的数据的一个序列\'。说白了流就是一堆没有载体的数据。
IO流:用来进行输入输出操作的流。换句话说IO流就是以流的方式进行输入输出。
字符流/字节流:根据对流数据的处理单位不同将数据流分为字符流和字节流。
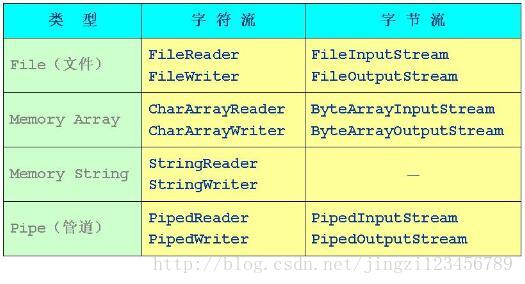
节点流/处理流:按照数据流是否直接来源于/去向物理数据源。将数据流分为节点流和处理流。比如FileInputStream数据流直接来源于文件,FileOutputStream直接去向文件。
java数据流结构图
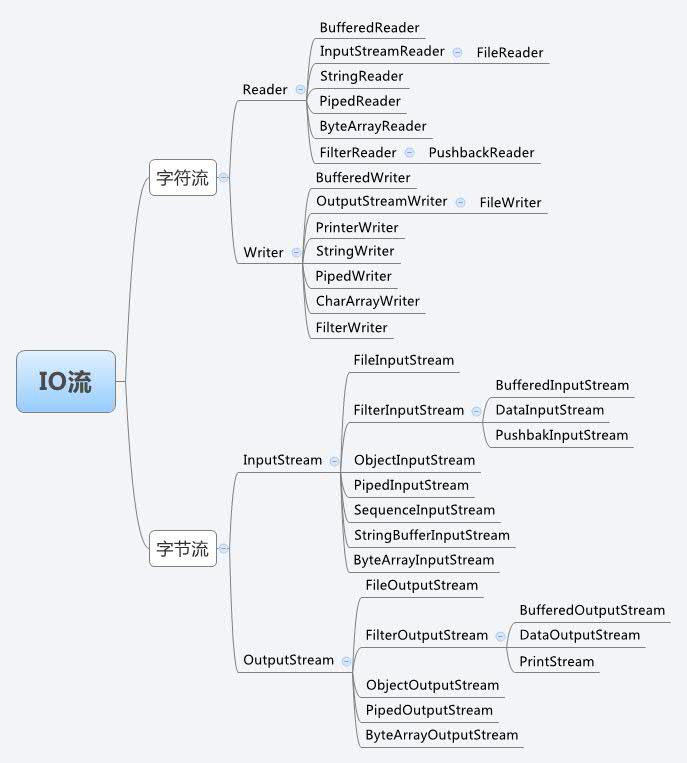

如果在创建数据流的时候参数中是数据源,该流为节点流,参数是流,则该流是处理/包装流。
从本质上讲,wirter/reader和inputstream/outputstream的最大区别在于encode和decode.
inputstream/outputstream 直接对byte[]进行操作,不会更改任何信息,原原本本的反应数据内容。
writer/reader在操作时会进行decode/encode. 它会根据你的系统属性file.encoding来decode数据。比如你从文件中读取一行,用reader.readLine()返回的string是经过decode的数据。如果你的文件的encoding不等于你的file.encoding的值,就会产生编码错误。
中文一个汉字占两个字节,当然用字符流Reader/Writer操作简单。如果使用字节流的话字符串和字节数组可以通过String.getBytes()和new String(byte[],"编码格式")来转换。
不同的流可能有的需要刷新,有的不需要刷新,但所有流在存取完成后必须关闭,否则会浪费JVM内存资源。
FileWriter,BufferedWriter,PrintWriter的区别?
如果说FileWriter每次都写操作,被bufferedWriter包装后可以缓冲满了再写入,为什么FileWriter还要刷新才能看见写入的数据?这是因为对write方法的误解,write方法
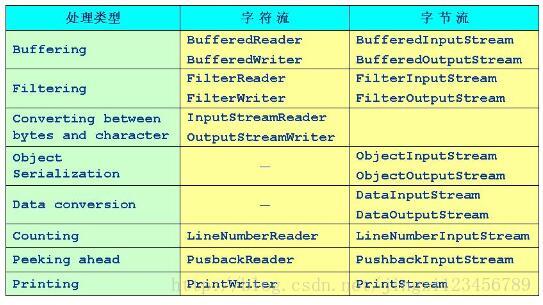
FileWriter和BufferedWriter执行write方法只会把数据写入缓冲区,别的什么也不管,如果缓冲区写满将停止写入。(FileOutputStream执行write方法会直接写入目的地而非缓冲。)
flush或close方法将缓冲区数据写入目的地,如果缓冲区是满的会检查是否还有数据未写入缓冲区,如果是则将满的缓冲区写入目的地后继续让write中剩余的数据写入缓冲区。然后继续将缓冲区数据写入目的地,如此循环。。。
PrintWriter可以处理字节流和字符流,可以处理任何类型数据。BufferedWriter只能处理字符流,只能处理字符相关数据如字符,字符串,字符数组。PrintWriter有自动刷新功能,BufferedWriter必须执行flush方法去刷新。
目前工作系统使用TelnetInputStream和FileOutputStream来实现下载对账文件。
目前socket中的流都是最原始的流InputStream和OutputStream,然后再对其进行封装操作。比如用BufferedInputStream和BufferedOutputStream封装提供带缓冲的读写,提高了读写的效率,类似于BufferedWriter的效果。还可以用DataInputStream和DataOutputStream
来封装,提供java中的基本数据类型的功能。
socket的getInputStream()/getOnputStream()
方法源码:
localInputStream = (InputStream)AccessController.doPrivileged(new PrivilegedExceptionAction()
{
public Object run()
throws IOException
{
return Socket.this.impl.getInputStream();//返回InputStream类型的流
}
}
数据流不仅仅是socket编程中用的,几乎所有通信都用了数据流,包括servlet,你可以通过request对象调用getInputStream()来获取继承自InputStream的ServletInputStream流。
NIO(Non-blocking无阻塞 I/O)
http://www.cnblogs.com/tengpan-cn/p/5809273.html
NIO的本质是什么样的呢?它是怎样与事件模型结合来解放线程、提高系统吞吐的呢?
本文会从传统的阻塞I/O和线程池模型面临的问题讲起,然后对比几种常见I/O模型,一步步分析NIO怎么利用事件模型处理I/O,解决线程池瓶颈处理海量连接,包括利用面向事件的方式编写服务端/客户端程序。最后延展到一些高级主题,如Reactor与Proactor模型的对比、Selector的唤醒、Buffer的选择等。
一个连接一个线程的经典模型中,之所以使用多线程,主要原因在于socket.accept()、socket.read()、socket.write()三个主要函数都是同步阻塞的,当一个连接在处理I/O的时候,系统是阻塞的,如果是单线程的话必然就挂死在那里;但CPU是被释放出来的,开启多线程,就可以让CPU去处理更多的事情。其实这也是所有使用多线程的本质。包括servlet也是如此,一个连接被servlet容器分配一个线程去处理。(servlet多线程单实例依旧能保证线程安全的原因是servlet是无状态的,没有属性/实例变量的。)
现在的多线程一般都使用线程池,可以让线程的创建和回收成本相对较低。在活动连接数不是特别高(小于单机1000)的情况下,这种模型是比较不错的,可以让每一个连接专注于自己的I/O并且编程模型简单,不过,这个模型最本质的问题在于,严重依赖于线程。但线程是很"贵"的资源。当面对十万甚至百万级连接的时候,传统的BIO模型是无能为力的。随着移动端应用的兴起和各种网络游戏的盛行,百万级长连接日趋普遍,此时,必然需要一种更高效的I/O处理模型。
https://zhuanlan.zhihu.com/p/23488863
常见I/O模型对比:
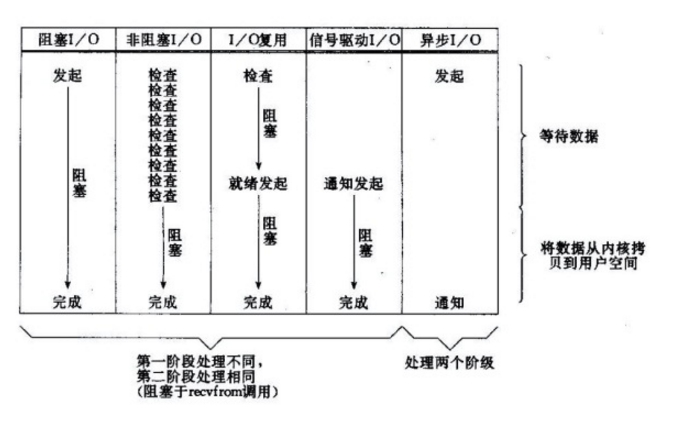
所有的系统I/O分为两个阶段,等待就绪(等待可读/可写),操作(读/写)。读函数,分为等待系统可读和真正的读;同理,写函数分为等待网卡可以写和真正的写。
等待就绪的阻塞是不使用CPU的,是在“空等”;而真正的读写操作的阻塞是使用CPU的,真正在"干活",而且这个过程非常快,属于memory copy,基本不耗时。
1.传统的BIO里面socket.read(),如果TCP RecvBuffer里没有数据,函数会一直阻塞,直到收到数据,返回读到的数据。(当前事情必须有结果才能处理别的事情,且当前事情不一定有结果)
2.对于NIO,如果TCP RecvBuffer有数据,就把数据从网卡读到内存,并且返回给用户;反之则直接返回0,永远不会阻塞。(当前事情必须有结果才能处理别的事情,且当前事情一定有结果比如返回0)
3.最新的AIO(Async I/O)里面会更进一步:不但等待就绪是非阻塞的,就连数据从网卡到内存的过程也是异步的(当前事情没有结果也能处理别的事情)
回忆BIO模型,之所以需要多线程,是因为在进行I/O操作的时候,一是没有办法知道到底能不能写、能不能读,只能"傻等",即使通过各种估算,算出来操作系统没有能力进行读写,也没法在socket.read()和socket.write()函数中返回,这两个函数无法进行有效的中断。所以除了多开线程另起炉灶,没有好的办法利用CPU。
NIO的读写函数可以立刻返回,这就给了我们不开线程利用CPU的最好机会:如果一个连接不能读写(socket.read()返回0或者socket.write()返回0),我们可以把这件事记下来,记录的方式通常是在Selector上注册标记位,然后切换到其它就绪的连接(channel)继续进行读写。
NIO的主要事件有:读就绪,写就绪,新连接到来。我们首先需要注册这几个事件到来时对应的处理器,然后在合适的时机告诉事件选择器所感兴趣的事件。对于读就绪,就是系统完成连接并且系统已经读满无法承载新读入的数据的时刻,对于写就绪,就是已经写满写不出去的时刻。。其次用一个死循环选择就绪的事件。新事件到来的时候会在selector上注册标记位,标示可读,可写,或新事件到来。
也就是说理论上NIO实现的逻辑是当前事情没有结果/不能做的时候转而选择别的事情,而java实现的逻辑是所有事情中哪些事情可做就去做哪些事情。事件的就绪状态应该是随时间随机变化的,人为不可控,应该可以直接调用判断函数。这样的话应该有两个循环,先对当前信道对应的缓冲循环判断可读和可写事件和新连接到来事件,可读时去读,可写时去写。
流的解析
1:直接用字符流处理
2:使用字节流时可以如下
byte[] data = new byte[10000];
this.bis.read(data);
return new String(data, "GBK").trim();
Xstream的作用到底是?还有Xpath
以上是关于常用包的主要内容,如果未能解决你的问题,请参考以下文章