人机大战之AlphaGo的硬件配置和算法研究
Posted powertoolsteam
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了人机大战之AlphaGo的硬件配置和算法研究相关的知识,希望对你有一定的参考价值。
AlphaGo的硬件配置
最近AlphaGo与李世石的比赛如火如荼,关于第四盘李世石神之一手不在我们的讨论范围之内。我们重点讨论下AlphaGo的硬件配置:
AlphaGo有多个版本,其中最强的是分布式版本的AlphaGo。根据DeepMind员工发表在2016年1月Nature期刊的论文,分布式版本(AlphaGo Distributed)使用了1202个CPU和176个GPU,同时可以有40个搜素线程。
维基百科上有各种版本的AlphaGo硬件配置 :
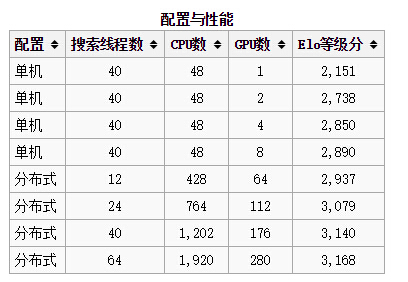
最后一列是等级分,代表了论文送审时(2015年11月)的水平。
下面是2016年3月14日GoRatings 发布的全球等级分列表,AlphaGo也被列在其中,排在第四位,可以看见各个版本AlphaGo的实力。

硬件配置Google官方没有给出明确说明,根据各方报道跟李世石对战的应该是最强的两个分布式“阿法狗”之一:
-(1920 CPUs + 280 GPUs,同时有64个搜索线程)
-(1202 CPUs + 176 GPUs,同时有40个搜索线程)
有Twitter网友作图:

从这个角度来看韩国人抗议比赛时间对于李世石不公平,也是可以理解的。
AlphaGo的算法结构
本文尝试用最简单的方法来讲述AlphaGo的算法,了解AlphaGo是如何下棋的。
AlphaGo的技术总体架构如果一句话总结的话就是:深度CNN神经网络架构结合蒙特卡洛搜索树(Monte Carlo Tree Search)。
深度学习神经网络训练出两个落子策略和一个局面评估模型,这三个策略的神经网络架构基本相同,这是参数不同而已。
两个落子策略:SL(supervised-learning policy network),RL(Reinforcement learning policy network)。
落子策略SL是通过学习人类对弈棋局,来模拟给定当前棋局局面,人如何落子的思路,这是纯粹的学习人类下棋经验,它的学习目标是:给定某个棋局形式,人会怎么落子?那么AlphaGo通过人类对弈棋局来学习这些落子策略,也就是说SL策略学习到的是像人一样来下下一步棋。

(数字表示人类棋手会下在该地方的可能性)
落子策略RL是通过AlphaGo自己和自己下棋来学习的,是在SL落子策略基础上的改进模型,RL策略的初始参数就是SL落子策略学习到的参数,就是它是以SL落子策略作为学习起点的,然后通过自己和自己下棋,要进化出更好的自己,它的学习目标是:不像SL落子策略那样只是学习下一步怎么走,而是要两个AlphaGo不断落子,直到决出某盘棋局的胜负,然后根据胜负情况调整RL策略的参数,使得RL学习到如何能够找到赢棋的一系列前后联系的当前棋局及对应落子,就是它的学习目标是赢得整盘棋,而不是像SL策略那样仅仅预测下一个落子。
局面评估网络(Position Evaluator Value Network)采用类似的深度学习网络结构,只不过它不是学习怎么落子,而是给定某个棋局盘面,学习从这个盘面出发,最后能够赢棋的胜率有多高,所以它的输入是某个棋局盘面,通过学习输出一个分值,这个分值越高代表从这个棋盘出发,那么赢棋的可能性有多大。

(局面评估是怎么看这个棋盘的。深蓝色表示下一步有利于赢棋的位置)
有了上面的三个深度学习策略,AlphaGo把这三个策略引入到蒙特卡洛搜索树中,所以它的总体架构还是蒙特卡洛搜索树,只是在应用蒙特卡洛搜索树的时候在几个步骤集成了深度学习学到的落子策略及盘面评估。
在AlphaGo与李世石的第四局中,李下出78手神之一手的时候,Google DeepMind 的 Hassabis 是这样说的:
@demishassabis 26m26 minutes ago
Lee Sedol is playing brilliantly! #AlphaGo thought it was doing well, but got confused on move 87. We are in trouble now...
@demishassabis 7m7 minutes ago
Mistake was on move 79, but #AlphaGo only came to that realisation on around move 87

简单来说就是狗没有及时认知到78的威胁,直到到87手才发现胜率下跌。这个说明狗在好几步后都不知道自己已经不妙了,计算结果里没有后来的发展。
这不是狗的bug,是标准的多算胜少算,这应该不算是bug而是value network和policy network还有待完善。
参考文献:
https://www.dcine.com/2016/01/28/alphago/
http://www.afenxi.com/post/8713
http://geek.csdn.net/news/detail/59308
http://blog.csdn.net/malefactor/article/details/50631180
http://www.leiphone.com/news/201603/Q1cWFZjnGl1wc4m1.html
以上是关于人机大战之AlphaGo的硬件配置和算法研究的主要内容,如果未能解决你的问题,请参考以下文章