引擎设计跟踪 ShadowMap 细节和分析
Posted 游戏人生
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了引擎设计跟踪 ShadowMap 细节和分析相关的知识,希望对你有一定的参考价值。
之前在工作总汇总了shadowmap的各种问题 [工作积累] shadow map问题汇总
最*有点时间再仔细研究了shadowmap的一些算法。主要修复了LiSPSM(上面链接里后面有更新),实现了TSM和CSM阴影。
总的来说,CSM只是结构上的不同,多了拆分和几个pass,实现起来相对比较简单。比较花时间的是LiSPSM和TSM的调试。至于为什么要研究LiSPSM和TSM,主要是在不能使用CSM的时候(比如低配,mobile之类),可以有更好的效果。另外,CSM和LiSPSM、TSM并不冲突,每个pass可以选择不同的方式。
LiSPSM和TSM都是透视算法,改变阴影的分布,因为透视的视点点离场景相机比较*,所以离场景相机*的物体,投影的面积大,分辨率高,远处分辨率低,但因为远,所以并没有效果损失,相反,如果不用透视,反而有点浪费。LiSPSM比较tricky,比如光空间包围盒的计算,和**面的选择。TSM从原理和实现上都比较简单,效果也比LiSPSM好,唯一的缺点是需要在fragment shader里写入深度,而且需要另外一个矩阵计算深度,与标准shadow map (standard shadow map, SSM)和LiSPSM的shader编写/维护的兼容性不好,需要用一堆宏来整合和嵌入到不同的shader里面。
渲染流程
通常为了提高阴影质量,不管哪种阴影技术,会用最小包围盒来计算投影矩阵,这依赖于场景的包围盒。对于大的场景,可以根据地形等大件物体预估一个包围盒,因为实时更新精确的包围盒不划算,也没太大必要。
另外一种方式与场景包围盒解耦,但是要分多个步骤 (渲染所有类型的shadow map都适用):
1.使用足够长/远的视锥(view/projection)剔除场景 (渲染shadow map总是要剔除的,所以先用足够远的视锥,保证所有可见阴影的shadow caster都在)
2.根据剔除后的包围盒,代替场景包围盒,做凸包体相交
3.重新计算并设置渲染用的view/projection
也就是说scene culling和rendering用的view/projection是不一样的,后者基于前者的culling结果重新计算。
以下图为例,求红色的光源视锥,可以不需要场景包围盒,而是把这个额光源视锥拉长到足够远,使用对场景剔除得到的包围盒与足够远的光源视锥相交。
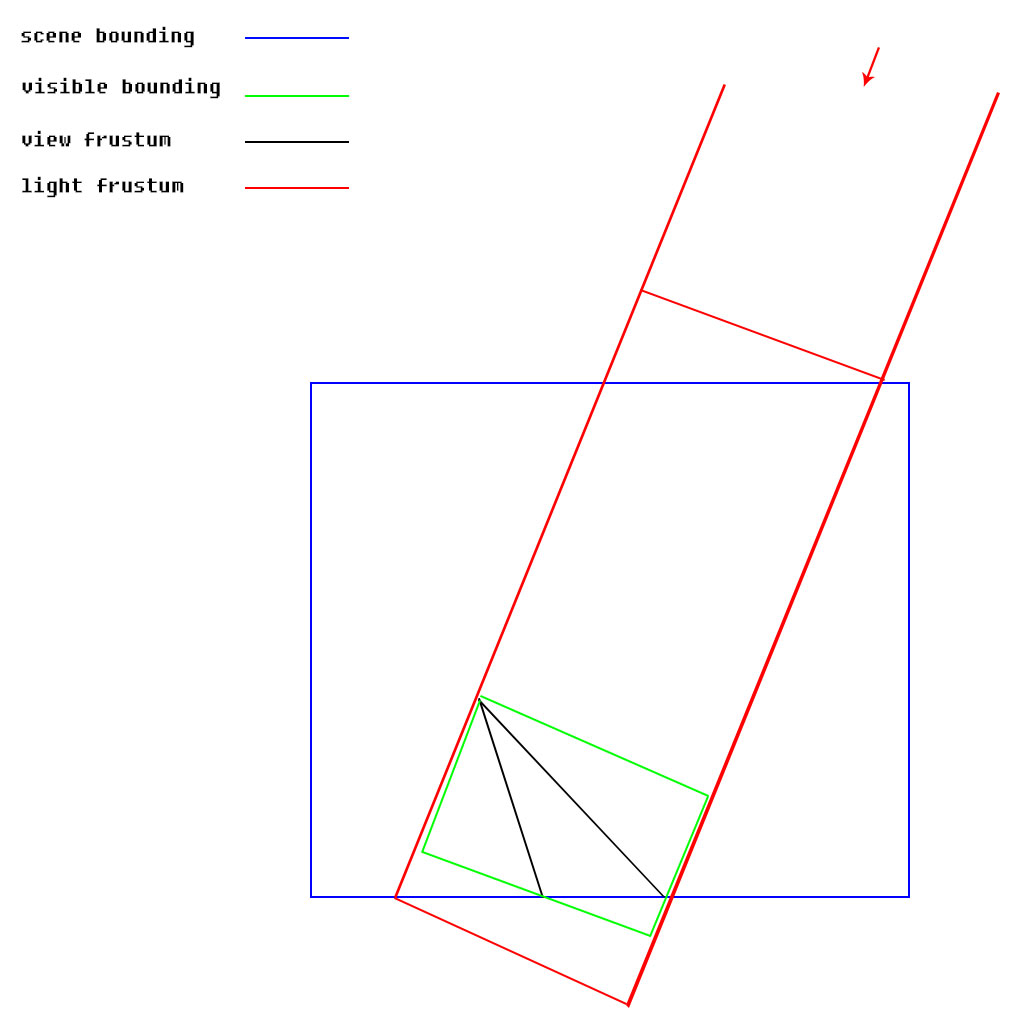
Depth clip / Depth clamp
这个方法在M$的 CSM demo里叫pancake。
如果不想计算最小包围盒,直接用可见物体包围盒的凸包体(上图中的绿色视锥部分)来计算投影矩阵,看起来也可以,问题是场景不可见的物体,投影可能可见。比如天上有一只鸟,虽然相机没看到,但是地上的影子要看到。如果用场景的可见包围盒来计算投影,阴影投影的**面在这只鸟前面,所以鸟被clip掉了(位于绿色视锥之外,红色视锥之内)。D3D10+和OGL提供了方法可以关闭clip。设置D3D11_RASTERIZER_DESC.DepthClipEnable = FALSE, glEnable(GL_DEPTH_CLAMP) 就可以关闭depth clip,或者启用depth clamp (depth clamp 到[-1,1]所以不会被clip掉)。
这种方式同时会减少projection的Z range,只能提高shadow depth的精度范围(绿色的视锥明显比红色短很多),但是并不能提高分辨率。
D3D9 在vertex shader里面clamp z 也是可以的:
float NDCZ = clipPos.z / clipPos.w; NDCZ = clamp(NDCZ, 0, 1); clipPos.z = NDCZ * clipPos.w;
这种方式对于正交和透视都有效。
坑:
depth clip 乍一看没什么问题,但问题还是有的:
+ B / / Z- / ^ / | / | / +--------------------+ +B\' | / | | / | | A / | | + | | | | | | | | | +--------------------+
上图中的box是NDC空间,AB是三角形的两个顶点,A在NDC cube内,B在NDC cube外, depth clamp以后B的位置在B‘。因为在vertexshader里面做clamp,整个三角形的几何都变了,线性插值以后深度会沿着AB’,
这条线的深度比以前的AB相比,整个深度都变大了,会导致有的阴影消失。 同样,如果B在z=1的下方,Bz>1,那么会导致这条线深度变小,会导致没有阴影的地方出现阴影。
我不知道D3D11的关闭depth clip怎么实现的,但是很有可能也是在vertex stage做的处理,会出现同样的问题。
解决的方法是手动输出fragment depth,在pixel shader里面clamp。。或者放弃这种方法。我目前的选择是放弃这种方法。因为本身它不是特别必要,又不适用于perspective shadow(shader可以实现,但是由于透视的原因问题更多),而且输出fragment depth会使Hi-Z和early Z失效,虽然shadow depth pass没输出颜色,但是这样的话,绘制深度就要做per-fragment depth test了。当然这点效率可以忽略,最大的问题是目前对于shadow depth pass的集成变得很不方便,需要加宏放到vsoutput里输出depth。因为有很多shader的depth pass是直接写到每个shader里面的,而不是统一的一个shader, 统一的一个shader对于普通静态模型倒是可以,直接用mvp矩阵,但是对于顶点有改变的情况(比如skinned mesh或者LOD morphing的地形)都还需要单独写,所以没太大意义。
TSM
LiSPSM的原理在前面已经简单做备忘了,下面笔记记录TSM的原理
TSM是Trapezoid shadow map (梯形shadow map),所谓的梯形,是场景相机视锥,在光空间横截面上的投影,大部分情况下都是梯形。通过一系列变换,把这个梯形填满整个截面。因为变换中包含了透视变换,实际上TSM是原理上非常类似LiSPSM的一种透视方法,只不过实现思路不一样。
TSM也是需要在垂直于光的方向做透视投影,因为只有垂直于光的方向的透视投影,才不会因为透视而改变光照方向,前面的问题汇总里面已经记录。 假设在做梯形变换之前,用一个垂直于光方向的正交投影(想象这里有一个正交视锥的box)渲染阴影深度,那么在梯形变换以后,这个正交投影会随着梯形变成box的过程中,变成透视投影(box变成了透视frustum)。
具体的变换步骤不复制了,在这里: http://www.comp.nus.edu.sg/~tants/tsm/TSM_recipe.html 需要记录的一点是,如果选取的视点和方向好的话,前两步变换是可以跳过的。
如果只用上面的变换,实现出的结果会很有问题,另一个关键是80%rule
80% rule
TSM的特色在于用80%rule来调节阴影质量,详细的分析在 http://www.comp.nus.edu.sg/~tants/tsm.html 里面的ppt链接里 (ppt:http://www.comp.nus.edu.sg/~tants/tsm/EGSR_TSM_presentation.ppt)
为什么要用80%rule?不使用80% rule,照着前面的体型变换做完,会发现透视得非常厉害,稍微远点阴影就非常模糊。因为这个时候渲染shadow map的透视投影的透视强度和场景相机的相关度是1:1,假如场景相机的水*FOV是90,远处分辨率太低了。
使用了80%rule以后就好了很多,本来我以为80%rule是为了提高*处的阴影分辨率,事实上是为了提高远处的分辨率。
80%rule 是指定某一个距离F,将其投影到shadow map上的80%处(保证质量), 来反算**面距离/视点,因为**面的宽度是固定的,这也就相当于调整了透视强度(fov),从而调整了分辨率分布。
根据80%rule 计算视点距离,方法上面的ppt里有,是用透视投影矩阵,和投影后的位置,反算**面距离zn.
NDCz = -1 + 2 * 0.8f; perspective projection along Z+: to [-1, 1] |F+zn,1| * |(zn+zf)/(zn-zf) -1| = | -NDCz*(F+zn), -(F+zn)| |-2*zn*zf/(zn-zf) 0| zn = zn, zf= zn+lambda (F+zn,1) * projection = (-NDCz*(F+zn), -(F+zn)) (F+zn)*(zn*2+lambda)/(-lambda) - 2*zn*(zn+lambda)/(-lambda) = -(F+zn)*z
其中lambda (λ)是视锥的深度(maxZ-minZ), 矩阵展开后上面最后一个等式,可以求出zn (η)。乍一看是二次方程,展开消元以后是一次方程。
TSM Fragment Depth
因为TSM的透视性,相机*处的Z range比较小,远处的Z range比较大,导致深度的范围分布不是固定的,所以depth bias和slope scaled bias都没办法工作。
depht bias的问题,可以在shadow/shading pass用bais matrix,并且在shadow 的view space做 bias(固定值,跟深度范围无关),但是slope scaled bias好像没办法解决,因为深度的坡度是基于屏幕空间变化率ddx/ddy来计算的。
解决方法是在pxiel shader里输出custom depth,这个depth用的是standard shadow map的depth,是均匀分布的,所以没有问题,但是缺点也有,一是要另外一个shadow depth matrix来计算深度,另外更重要的是前面提到过的,集成不太方便,要加一堆宏。
其实LiSPSM也是透视的,理论上也有一样的问题。但是LiSPSM透视强度没有TSM那么“激进”,所以没有出现类似的问题,这同时也是LiSPSM的质量没有TSM高的原因。
CSM
不管是TSM还是LiSPSM,在场景相机和光照方向*行的时候:TSM在光空间横截面上投影的梯形会变成box,没办法做透视;而LiSPSM的透视方向跟场景相机视方向垂直,投影出的“*处”高分辨率离相机视点并不*。所以两种方式的阴影质量还是很低。
这种情况叫做dueling frusta(视锥决斗)(场景相机的视锥和光源视锥*行正对着,很形象),很多阴影技术都无能为力,这个时候,CSM (Cascade Shadow maps)能改进。
使用CSM将视锥分割,这样*处分割的视锥,光空间方向的xy会变小,投影以后的分辨率就会变大。
原理和实现都很简单,但是结果很关键。
如果使用(2048x2048)x(2x2)的CSM,如果使用32位depth stencil,显存占用为64M,开销还是很大的,所以选择16位的depth(比如d3d9的D3DFMT_D16),显存占用降到32M。
CSM for forward shading
CSM在screen space的deferred shadow实现比较方便,但如果是legacy的forward,比如SM 2_a,没有readable depth stencil来defer,又不想渲染浮点颜色精度的深度话,就没有screen space shadow了。
这个时候要集成到每个forward shader里,由于pixel shader profile 2_a 的constant register 只有32个, 又加上local light也是一个pass, 4个光源(blade 不支持更多pass foward shading),这个时候常量寄存器就会不够用,爆掉。
如果关闭所有local lights的支持,或者使用多pass lighting,或者加上非 depth_stencil的depth pass (R32F)来做deferred shadow, 都可以解决问题。 我目前对于forwad shading,暂时关闭CSM,这个直接在配置文件里面,不需要改代码。唯一要改的是shader的宏,如果像Unity那样可以动态开关shader feature,shader也不需要改了
forward shading的优化: 可以在vertex shader里面计算cascade index 和shadow uv/depth,跟SSM的方式一样, 不过需要SM40,因为SM30及其以前的index在插值的时候,会有插值,并没有Interpolation Modifiers ,导致到了pxiel shader stage,前两张shadowmap衔接处的index值介于0~1之间,DX10+可以关闭线性插值。但如果是DX10+的话,不如直接用screen space deferred shadow了,所以这个优化没多大意义。
CSM 的多相机处理
CSM有多个相机渲染,那么更新的策略可能需要微调。 场景相机的可见集,和阴影相机的可见集,有交集,但不完全重合。
比如地形的批次合并,需要支持多个相机;
地形的LOD更新,如果是可见才更新,那么不管哪个相机在计算可见性,更新的源相机都要使用场景主相机,否则阴影深度相机的位置可能和场景相机差别很大,导致阴影的LOD divergence,或者影响场景LOD;
同时,如果是可见才更新,那么多个相机时,可能会有多次可见的事件(多次回调或者更新函数),为了避免冗余的计算,可以使用mask 标记,更新过的就不更新。或者使用FrameID,同一帧只更新一次。
同样模型的更新,比如骨骼动画等,如果是可见才更新骨骼动画,也用类似的方法处理。
不光是CSM,比如planar reflection的相机,总之只要处理好 有多个相机的情况,并尽量保证最优化。具体更新时用哪个相机,是具体模块的逻辑,和渲染框架无关,最好把当前相机和场景主相机都作为参数,这样模块可以决定自己的更新逻辑。
CSM with persepective shadow map
CSM可以和LiSPM/TSM结合使用,
但是有一个严重的问题,而且在高度差比较大的场景(比如飞行游戏/位于高山)中很常见。比如CSM和LiSPSM结合的时候,由于透视的原因,第一级shadowmap和第二级shadowmap的接缝处,第一级的质量反而比第二级的低。

因为第一级的最远处,透视的结果是分辨率更低, 而第二级的最*处,因为透视的原因,分辨率更高。 标准shadow map往往是第一级比第二级更清晰。
所以如果要结合的话,建议方案如下:
方案1
第一级使用TSM,并使用80%rule调整远处阴影分辨率,可以和第二级较好的衔接;
第二级和后面的所有shadow map,都使用standard shadow map,不用透视,或使用TSM调整。
这样可以最大化的提高*处阴影的质量,特别是自阴影,又不会使衔接效果变差。
方案2
每一级都使用LiSPSM/TSM,并且使用最激进的策略将CSM的精度放在*处(如果使用了分割指数,把它调大),比如四级CSM,距离分别为1.86, 17.32, 161.18,1500.00,这样做有两个好处:
第一*处的分辨率非常高,第二*处的分割距离短,透视造成的每级末端的模糊(上图)非常小。虽然最后一级范围很大,但是因为比较远,而且是透视的所以效果不会很差。
这种方案即便是2048的shadow map(1024x4),效果也是可以接受的。如果使用TSM,可以使用1024(512x4)效果应该也可以接受,可能运行在mobile上(纯推测,没有做实际效果测试)。
以上是关于引擎设计跟踪 ShadowMap 细节和分析的主要内容,如果未能解决你的问题,请参考以下文章