LCA算法解析-Tarjan&倍增
Posted tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了LCA算法解析-Tarjan&倍增相关的知识,希望对你有一定的参考价值。
原文链接http://www.cnblogs.com/zhouzhendong/p/7256007.html
UPD(2018-5-13) : 细节修改以及使用了Markdown代码,公式更加美观。改的过程中发现许多叙述上的问题,已经修改。并补写了一个在线 $O(1)$ 查询的 $RMQ$ 算法。
问题模型
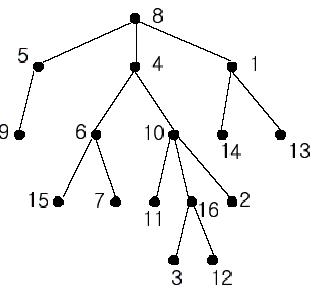
对于一棵树,求两个节点的最近公共祖先(LCA)。
如下图:(以下数字代表对应编号的节点)
$1$ 和 $6$ 的 LCA 是 $8$ 。
$11$ 和 $1$ 的 LCA 是 $8$ 。
$11$ 和 $15$ 的 LCA 是 $4$ 。
$14$ 和 $13$ 的 LCA 是 $1 $ 。
LCA_Tarjan
Tarjan 算法求 LCA 的时间复杂度为 $O((n+q)\\alpha(n))$ ,是一种离线算法,要用到并查集。
Tarjan 算法基于 dfs ,在 dfs 的过程中,对于每个节点位置的询问做出相应的回答。
dfs 的过程中,当一棵子树被搜索完成之后,就把他和他的父亲合并成同一集合;在搜索当前子树节点的询问时,如果该询问的另一个节点已经被访问过,那么该编号的询问是被标记了的,于是直接输出当前状态下,另一个节点所在的并查集的祖先;如果另一个节点还没有被访问过,那么就做下标记,继续 dfs 。
当然,暂时还没那么容易弄懂,所以建议结合下面的例子和标算来看看。
(下面的集合合并都用并查集实现)
比如:$8-1-14-13$ ,此时已经完成了对子树 $1$ 的子树 $14$ 的 $dfs$ 与合并( $14$ 子树的集合与 $1$ 所代表的集合合并),如果存在询问 $(13,14)$ ,则其 LCA 即 $getfather(14)$ ,即 $1$ ;如果还存在由节点 $13$ 与 已经完成搜索的子树中的 节点的询问,那么处理完。然后合并子树 $13$ 的集合与其父亲 $1$ 当前的集合,回溯到子树 $1$ ,并深搜完所有 $1$ 的其他未被搜索过的儿子,并完成子树 $1$ 中所有节点的合并,再往上回溯,对节点 $1$ 进行类似的操作即可。
#include <cstring> #include <cstdio> #include <algorithm> #include <cstdlib> #include <cmath> using namespace std; const int N=40000+5; struct Edge{ int cnt,x[N],y[N],z[N],nxt[N],fst[N]; void set(){ cnt=0; memset(x,0,sizeof x); memset(y,0,sizeof y); memset(z,0,sizeof z); memset(nxt,0,sizeof nxt); memset(fst,0,sizeof fst); } void add(int a,int b,int c){ x[++cnt]=a; y[cnt]=b; z[cnt]=c; nxt[cnt]=fst[a]; fst[a]=cnt; } }e,q; int T,n,m,from,to,dist,in[N],rt,dis[N],fa[N],ans[N]; bool vis[N]; void dfs(int rt){ for (int i=e.fst[rt];i;i=e.nxt[i]){ dis[e.y[i]]=dis[rt]+e.z[i]; dfs(e.y[i]); } } int getf(int k){ return fa[k]==k?k:fa[k]=getf(fa[k]); } void LCA(int rt){ for (int i=e.fst[rt];i;i=e.nxt[i]){ LCA(e.y[i]); fa[getf(e.y[i])]=rt; } vis[rt]=1; for (int i=q.fst[rt];i;i=q.nxt[i]) if (vis[q.y[i]]&&!ans[q.z[i]]) ans[q.z[i]]=dis[q.y[i]]+dis[rt]-2*dis[getf(q.y[i])]; } int main(){ scanf("%d",&T); while (T--){ q.set(),e.set(); memset(in,0,sizeof in); memset(vis,0,sizeof vis); memset(ans,0,sizeof ans); scanf("%d%d",&n,&m); for (int i=1;i<n;i++) scanf("%d%d%d",&from,&to,&dist),e.add(from,to,dist),in[to]++; for (int i=1;i<=m;i++) scanf("%d%d",&from,&to),q.add(from,to,i),q.add(to,from,i); rt=0; for (int i=1;i<=n&&rt==0;i++) if (in[i]==0) rt=i; dis[rt]=0; dfs(rt); for (int i=1;i<=n;i++) fa[i]=i; LCA(rt); for (int i=1;i<=m;i++) printf("%d\\n",ans[i]); } return 0; }
倍增
我们可以用倍增来在线求 LCA ,时间和空间复杂度分别是 $O((n+q)\\log n)$ 和 $O(n \\log n)$ 。
对于这个算法,我们从最暴力的算法开始:
①如果 $a$ 和 $b$ 深度不同,先把较深点的深度调浅,使他变得和浅的那个一样
②现在已经保证了 $a$ 和 $b$ 的深度一样,所以我们只要把两个一起一步一步往上移动,直到他们到达同一个节点,也就是他们的最近公共祖先了。
#include <cstring> #include <cstdio> #include <cstdlib> #include <algorithm> #include <cmath> #include <vector> using namespace std; const int N=10000+5; vector <int> son[N]; int T,n,depth[N],fa[N],in[N],a,b; void dfs(int prev,int rt){ depth[rt]=depth[prev]+1; fa[rt]=prev; for (int i=0;i<son[rt].size();i++) dfs(rt,son[rt][i]); } int LCA(int a,int b){ if (depth[a]>depth[b]) swap(a,b); while (depth[b]>depth[a]) b=fa[b]; while (a!=b) a=fa[a],b=fa[b]; return a; } int main(){ scanf("%d",&T); while (T--){ scanf("%d",&n); for (int i=1;i<=n;i++) son[i].clear(); memset(in,0,sizeof in); for (int i=1;i<n;i++){ scanf("%d%d",&a,&b); son[a].push_back(b); in[b]++; } depth[0]=-1; int rt=0; for (int i=1;i<=n&&rt==0;i++) if (in[i]==0) rt=i; dfs(0,rt); scanf("%d%d",&a,&b); printf("%d\\n",LCA(a,b)); } return 0; }
而实际上,一步一步往上移动太慢,我们可以做一个预处理:
$fa_{i,j}$ 表示节点 $i$ 往上走 $2^j$ 次所到达的祖先,那么不难写出转移式:
$fa_{i,0}=father_i,fa_{i,j}=fa_{fa_{i,j-1},j-1}$
然后在求 LCA 的时候,有这样一个性质:(假设 $a$ 和 $b$ 深度一样)
设 $anst_{x,y}$ 为节点 $x$ 向上走 $y$ 步到达的祖先,对于一个 $k$ ,如果 $anst_{a,k}=anst_{b,k}$ ,那么对于所有 $k^\\prime(k^\\prime>k)$ ,一定有 $anst_{a,k^\\prime}=anst_{b,k^\\prime}$ ;对于一个 $k$ ,如果 $anst_{a,k}\\neq anst_{b,k}$ ,那么对于所有 $k^\\prime(k^\\prime<k)$ ,一定有 $anst_{a,k^\\prime}\\neq anst_{b,k^\\prime}$ ,而且 $LCA(a,b)=LCA(anst_{a,k},anst_{b,k})$ 。
于是我们可以得出以下做法:
(UPD(2018-08-31): 这部分叙述修改了)
1. 把 $a$ 和 $b$ 移到同一深度(设 $depth_x$ 为节点 $x$ 的深度),假设 $depth_a\\leq depth_b$ ,这个时候,之前预处理的 $fa$ 数组就派上用场了。从大到小枚举 $k$ ,如果 $b$ 向上跳 $2^k$ 得到的节点的深度 $\\geq depth_a$ ,那么 $b$ 就往上跳。
2.如果 $a=b$ ,那么显然 LCA 就是 $a$。否则执行第 3 步。
3.这一步的主要目的是 :分别找到最浅的 $a^\\prime$ 和 $b^\\prime$ ,并且 $a^\\prime \\neq b^\\prime $ 。
利用之前的那个性质,再利用倍增,从大到小枚举 $k$ ,如果对于当前的 $k$ , $a$ 和 $b$ 的第 $2^k$ 个祖先不同,那么 $a$ 和 $b$ 都跳到其 $2^k$ 祖先的位置。LCA 就是 $fa_{a^\\prime,0}$ 或者 $fa_{b^\\prime,0}$ 。
UPD(2018-07-12): LCA 倍增关键部分模板更新
#include <cstring>
#include <cstdio>
#include <cstdlib>
#include <algorithm>
#include <cmath>
#include <vector>
using namespace std;
const int N=10000+5;
vector <int> son[N];
int T,n,depth[N],fa[N][20],in[N],a,b;
void dfs(int prev,int rt){
depth[rt]=depth[prev]+1;
fa[rt][0]=prev;
for (int i=1;i<20;i++)
fa[rt][i]=fa[fa[rt][i-1]][i-1];
for (int i=0;i<son[rt].size();i++)
dfs(rt,son[rt][i]);
}
int LCA(int x,int y){
if (depth[x]<depth[y])
swap(x,y);
for (int i=19;i>=0;i--)
if (depth[x]-(1<<i)>=depth[y])
x=fa[x][i];
if (x==y)
return x;
for (int i=19;i>=0;i--)
if (fa[x][i]!=fa[y][i])
x=fa[x][i],y=fa[y][i];
return fa[x][0];
}
int main(){
scanf("%d",&T);
while (T--){
scanf("%d",&n);
for (int i=1;i<=n;i++)
son[i].clear();
memset(in,0,sizeof in);
for (int i=1;i<n;i++){
scanf("%d%d",&a,&b);
son[a].push_back(b);
in[b]++;
}
depth[0]=-1;
int rt=0;
for (int i=1;i<=n&&rt==0;i++)
if (in[i]==0)
rt=i;
dfs(0,rt);
scanf("%d%d",&a,&b);
printf("%d\\n",LCA(a,b));
}
return 0;
}
RMQ
现在来介绍一种 $O(n\\log n)$ 预处理,$O(1)$ 在线查询的算法。
RMQ 的意思大概是“区间最值查询”。顾名思义,用 RMQ 来求 LCA 是通过 RMQ 来实现的。
首先,您可以了解一下 dfs 序。链接:http://www.cnblogs.com/zhouzhendong/p/7264132.html
在 dfs 的过程中,退出一个子树之后就不会再进入了。这是个很好的性质。
所以很显然,一个子树中深度最浅的节点必定是该子树的树根。
显然,两个节点的 LCA 不仅是两个节点的最近公共祖先,而且是囊括这两个节点的最小子树的根,即囊括这两个节点的最小子树中的深度最小的节点。
我们来想一想如何得到这个节点。
现在,我们稍微修改一下 dfs 序,搞一个欧拉序。
欧拉序,就是每次从 $father(x)$ 进入节点 $x$ 或者从子节点回溯到 $x$ 都要把 $x$ 这个编号扔到一个数组的最后。
这样最终会得到一个长度约为 $2n$ 的数列。(考虑每一个节点贡献为 $2$ ,分别是从其父亲进入该节点,和从该节点回到其父亲)
例如,上图这棵树的一个欧拉序为 $8,5,9,5,8,4,6,15,6,7,6,4,10,11,10,16,3,16,12,16,10,2,10,4,8,1,14,1,13,1,8$ 。
建议跟着我给出的欧拉序走一遍,再次理解欧拉序的含义。
再注意到,一对点的 LCA 不仅是囊括这两个节点的最小子树中的深度最小的节点,还是连接这对点的简单路径上深度最小的点。
而且从离开 $a$ 到进入 $b$ 的这段欧拉序必然包括所有这对点之间的简单路径上的所有点,所以我们考虑求得这段欧拉序中所包含的节点中的 深度最小的点即其 LCA 。
从 $a$ 到 $b$ 的这段欧拉序会包含这棵子树中的其他节点,但是不会影响这个最浅点的求得,因为“一对点的 LCA 是囊括这两个节点的最小子树中的深度最小的节点”。
显然, $a$ 到 $b$ 这段欧拉序是个连续区间。
你可以用线段树维护,但是线段树太慢了。
现在我们考虑通过预处理来 $O(1)$ 获得这个最浅点。
于是我们要学习一个叫做 ST表 的东西来搞定这个。(和之前倍增中处理的 $fa$ 数组差不多)
我再放一篇大佬博客来介绍 RMQ 与 ST表 : https://blog.csdn.net/qq_31759205/article/details/75008659
接下来当然是轻松愉快的放代码时间啦。
//CodeVS2370
#include <bits/stdc++.h>
#define time _____time
using namespace std;
const int N=50005;
struct Gragh{
int cnt,y[N*2],z[N*2],nxt[N*2],fst[N];
void clear(){
cnt=0;
memset(fst,0,sizeof fst);
}
void add(int a,int b,int c){
y[++cnt]=b,z[cnt]=c,nxt[cnt]=fst[a],fst[a]=cnt;
}
}g;
int n,m,depth[N],in[N],out[N],time;
int ST[N*2][20];
void dfs(int x,int pre){
in[x]=++time;
ST[time][0]=x;
for (int i=g.fst[x];i;i=g.nxt[i])
if (g.y[i]!=pre){
depth[g.y[i]]=depth[x]+g.z[i];
dfs(g.y[i],x);
ST[++time][0]=x;
}
out[x]=time;
}
void Get_ST(int n){
for (int i=1;i<=n;i++)
for (int j=1;j<20;j++){
ST[i][j]=ST[i][j-1];
int v=i-(1<<(j-1));
if (v>0&&depth[ST[v][j-1]]<depth[ST[i][j]])
ST[i][j]=ST[v][j-1];
}
}
int RMQ(int L,int R){
int val=floor(log(R-L+1)/log(2));
int x=ST[L+(1<<val)-1][val],y=ST[R][val];
if (depth[x]<depth[y])
return x;
else
return y;
}
int main(){
scanf("%d",&n);
for (int i=1,a,b,c;i<n;i++){
scanf("%d%d%d",&a,&b,&c);
a++,b++;
g.add(a,b,c);
g.add(b,a,c);
}
time=0;
dfs(1,0);
depth[0]=1000000;
Get_ST(time);
scanf("%d",&m);
while (m--){
int x,y;
scanf("%d%d",&x,&y);
if (in[x+1]>in[y+1])
swap(x,y);
int LCA=RMQ(in[x+1],in[y+1]);
printf("%d\\n",depth[x+1]+depth[y+1]-depth[LCA]*2);
}
return 0;
}
其他算法
1.取最大子树为重儿子的树链剖分可以 $O(n)$ 时间空间预处理,在线 $O(\\log n)$ 查询 LCA。
2.在上述 RMQ 算法的基础上,再加上“四毛子方法(Method Of Four Russians)” 可以实现 $O(n)$ 时间空间预处理, $O(1)$ 在线查询 LCA。
练习题
POJ1330
HDU2586
CodeVS2370
POJ1470
HDU4547
本文为博主原创文章,请勿随意转载。谢谢!
以上是关于LCA算法解析-Tarjan&倍增的主要内容,如果未能解决你的问题,请参考以下文章