从字节码层面看“HelloWorld”
Posted liuxiaopeng
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了从字节码层面看“HelloWorld”相关的知识,希望对你有一定的参考价值。
一、HelloWorld 字节码生成
众所周知,Java 程序是在 JVM 上运行的,不过 JVM 运行的其实不是 Java 语言本身,而是 Java 程序编译成的字节码文件。可能一开始 JVM 是为 Java 语言服务的,不过随着编译技术和 JVM 自身的不断发展和成熟,JVM 已经不仅仅只运行 Java 程序。任何能编译成为符合 JVM 字节码规范的语言都可以在 JVM 上运行,比较常见的 Scala、Groove、JRuby等。今天,我就从大家最熟悉的程序“HelloWorld”程序入手,分析整个 Class 文件的结构。虽然这个程序比较简单,但是基本上包含了字节码规范中的所有内容,因此即使以后要分析更复杂的程序,那也只是“量”上的变化,本质上没有区别。
我们先直观的看下源码与字节码之间的对应关系:
HelloWorld的源码:
package com.paddx.test.asm;
public class HelloWorld {
public static void main(String[] args) {
System.out.println("Hello,World!");
}
}
编译器采用JDK 1.7:
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>1.7</source>
<target>1.7</target>
</configuration>
</plugin>
编译以后的字节码文件(使用UltraEdit的16进制模式打开):
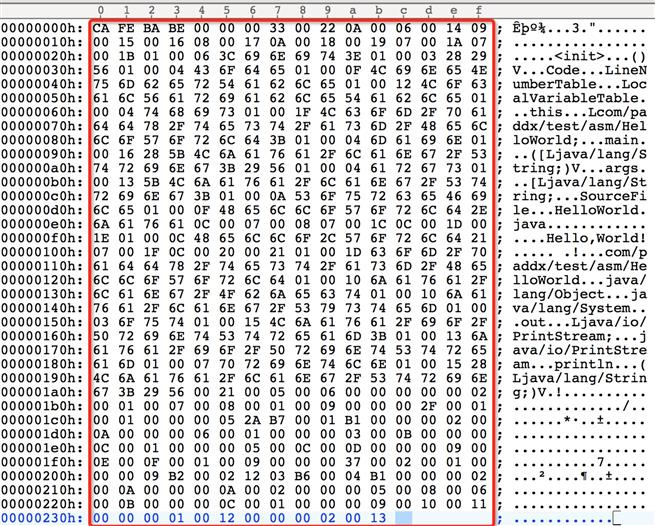
红色框内的部分就是HelloWorld.class的内容,其他部分是UltraEdit自动生成的:红色框顶部的0~f代表列号,左边部分代表行号,右侧部分是二进制码对应的字符(utf-8编码)。
二、字节码解析
要弄明白 HelloWorld.java 和 HelloWorld.class 文件是如何对应的,我们必须对 JVM 的字节码规范有所了解。字节码文件的结构非常紧凑,没有任何冗余的信息,连分隔符都没有,它采用的是固定的文件结构和数据类型来实现对内容的分割的。字节码中包括两种数据类型:无符号数和表。无符号数又包括 u1,u2,u4,u8四种,分别代表1个字节、2个字节、4个字节和8个字节。而表结构则是由无符号数据组成的。
字节码文件的格式固定如下:
| type | descriptor |
| u4 | magic |
| u2 | minor_version |
| u2 | major_version |
| u2 | constant_pool_count |
| cp_info | constant_pool[cosntant_pool_count – 1] |
| u2 | access_flags |
| u2 | this_class |
| u2 | super_class |
| u2 | interfaces_count |
| u2 | interfaces[interfaces_count] |
| u2 | fields_count |
| field_info | fields[fields_count] |
| u2 | methods_count |
| method_info | methods[methods_count] |
| u2 | attributes_count |
| attribute_info | attributes[attributes_count] |
现在,我们就按这个格式对上述HelloWorld.class文件进行分析:
magic(u4):CA FE BA BE ,代表该文件是一个字节码文件,我们平时区分文件类型都是通过后缀名来区分的,不过后缀名是可以随便修改的,所以后缀名是不能真正区分一个文件的类型。区分文件类型的另个办法就是magic数字,JVM 就是通过 CA FE BA BE 来判断该文件是不是class文件。
minor_version(u2):00 00,小版本号,因为我这里采用的1.7,所以小版本号为0.
major_version(u2):00 33,大版本号,x033转换为十进制为51,下表是jdk 1.6 以后对应支持的 Class 文件版本号:
| 编译器版本 | -target参数 | 十六进制版本 | 十进制版本 |
| JDK 1.6.0_01 | 不带(默认 -target 1.6) | 00 00 00 32 | 50.0 |
| JDK 1.6.0_01 | -target 1.5 | 00 00 00 31 | 49.0 |
| JDK 1.6.0_01 | -target 1.4 -source 1.4 | 00 00 00 30 | 48.0 |
| JDK 1.7.0 | 不带(默认 -target 1.7) | 00 00 00 33 | 51.0 |
| JDK 1.7.0 | -target 1.6 | 00 00 00 32 | 50.0 |
| JDK 1.7.0 | -target 1.4 -source 1.4 | 00 00 00 30 | 48.0 |
| JDK 1.8.0 | 不带(默认 -target 1.8) | 00 00 00 34 | 52.0 |
constant_pool_count(u2):00 22,常量池数量,转换为十进制后为34,这里需要注意的是,字节码的常量池是从1开始计数的,所以34表示为(34-1)=33项。
TAG(u1):0A,常量池的数据类型是表,每一项的开始都有一个tag(u1),表示常量的类型,常量池的表的类型包括如下14种,这里A(10)表示CONSTANT_Methodref,代表方法引用。
| 常量类型 | 值 |
| CONSTANT_Utf8_info | 1 |
| CONSTANT_Integer_info | 3 |
| CONSTANT_Float_info | 4 |
| CONSTANT_Long_info | 5 |
| CONSTANT_Double_info | 6 |
| CONSTANT_Class_info | 7 |
| CONSTANT_String_info | 8 |
| CONSTANT_Fieldref_info | 9 |
| CONSTANT_Methodref_info | 10 |
| CONSTANT_InterfaceMethodref_info | 11 |
| CONSTANT_NameAndType_info | 12 |
| CONSTANT_MethodHandle_info | 15 |
| CONSTANT_MethodType_info | 16 |
| CONSTANT_InvokeDynamic_info | 18 |
每种常量类型对应表结构:
| 常量 | 项目 | 类型 | 描述 |
| CONSTANT_Utf8_info | tag | u1 | 1 |
| length | u2 | 字节数 | |
| bytes | u1 | utf-8编码的字符串 | |
| CONSTANT_Integer_info | tag | u1 | 3 |
| bytes | u4 | int值 | |
| CONSTANT_Float_info | tag | u4 | 4 |
| bytes | u1 | float值 | |
| CONSTANT_Long_info | tag | u1 | 5 |
| bytes | u8 | long值 | |
| CONSTANT_Double_info | tag | u1 | 6 |
| bytes | u8 | double值 | |
| CONSTANT_Class_info | tag | u1 | 7 |
| index | u2 | 指向全限定名常量项的索引 | |
| CONSTANT_String_info | tag | u1 | 8 |
| index | u2 | 指向字符串常量的索引 | |
| CONSTANT_Fieldref_info | tag | u1 | 9 |
| index | u2 | 指向声明字段的类或接口描述符CONSTANT_Class_info的索引值 | |
| index | u2 | 指向CONSTANT_NameAndType_info的索引值 | |
| CONSTANT_Methodref_info | tag | u1 | 10 |
| index | u2 | 指向声明方法的类描述符CONSTANT_Class_info的索引值 | |
| index | u2 | 指向CONSTANT_NameAndType_info的索引值 | |
| CONSTANT_InterfaceMethodref_info | tag | u1 | 11 |
| index | u2 | 指向声明方法的接口描述符CONSTANT_Class_info的索引值 | |
| index | u2 | 指向CONSTANT_NameAndType_info的索引值 | |
| CONSTANT_NameAndType_info | tag | u1 | 12 |
| index | u2 | 指向该字段或方法名称常量的索引值 | |
| index | u2 | 指向该字段或方法描述符常量的索引值 | |
| CONSTANT_MethodHandle_info | tag | u1 | 15 |
| reference_kind | u1 | 值必须1~9,它决定了方法句柄的的类型 | |
| reference_index | u2 | 对常量池的索引 | |
| CONSTANT_MethodType_info | tag | u1 | 16 |
| description_index | u2 | 对常量池中方法描述符的索引 | |
| CONSTANT_InvokeDynamic_info | tag | u1 | 18 |
| bootstap_method_attr_index | u2 | 对引导方法表的索引 | |
| name_and_type_index | u2 | 对CONSTANT_NameAndType_info的索引 |
CONSTANT_Methodref_info(u2): 00 06,因为tag为A,代表一个方法引用表(CONSTANT_Methodref_info),所以第二项(u2)应该是指向常量池的位置,即常量池的第六项,表示一个CONSTANT_Class_info表的索引,用类似的方法往下分析,可以发现常量池的第六项如下,tag类型为07,查询上表可知道其即为CONSTANT_Class_info。

07之后的00 1B表示对常量池地27项(CONSTANT_Utf8_info)的引用,查看第27项如下图,即(java/lang/Object):
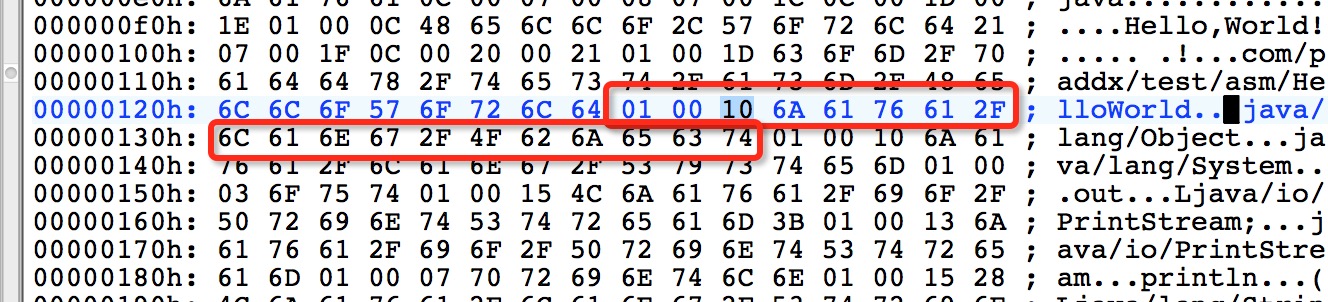
CONSTANT_NameAndType_info(u2):00 14,方法引用表的第三项(u2),常量池索引,指向第20项。
CONSTANT_Fieldref_info(u1):tag为09。
.....
常量池的分析都类似,其他的分析由于篇幅问题就不在此一一讲述了。跳过常量池就到了访问标识(u2):
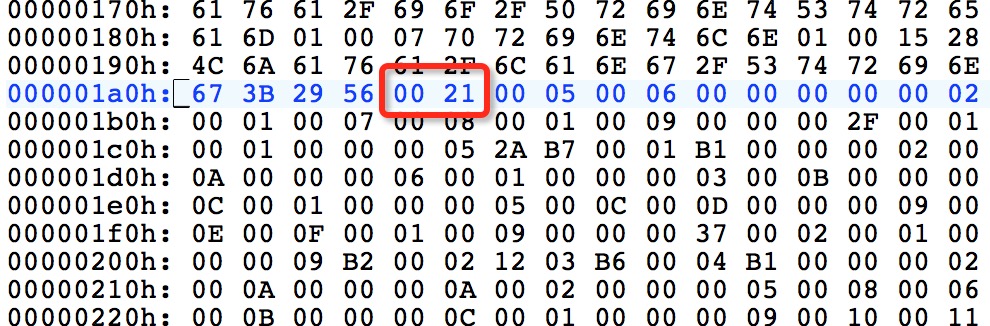
JVM 对访问标示符的规范如下:
| Flag Name | Value | Remarks |
| ACC_PUBLIC | 0x0001 | pubilc |
| ACC_FINAL | 0x0010 | final |
| ACC_SUPER | 0x0020 | 用于兼容早期编译器,新编译器都设置该标记,以在使用 invokespecial指令时对子类方法做特定处理。 |
| ACC_INTERFACE | 0x0200 |
接口,同时需要设置:ACC_ABSTRACT。不可同时设置:ACC_FINAL、ACC_SUPER、ACC_ENUM |
| ACC_ABSTRACT | 0x0400 | 抽象类,无法实例化。不可与ACC_FINAL同时设置。 |
| ACC_SYNTHETIC | 0x1000 | synthetic,由编译器产生,不存在于源代码中。 |
| ACC_ANNOTATION | 0x2000 | 注解类型(annotation),需同时设置:ACC_INTERFACE、ACC_ABSTRACT |
| ACC_ENUM | 0x4000 | 枚举类型 |
这个表里面无法直接查询到0021这个值,原因是0021=0020+0001,即public+invokespecial指令,源码中的方法main是public的,而invokespecial是现在的版本都有的,所以值为0021。
接着往下是this_class(u2):是指向constant pool的索引值,该值必须是CONSTANT_Class_info类型,值为00 05,即指向常量池中的第五项,第五项指向常量池中的第26项,即com/paddx/test/asm/HelloWorld:
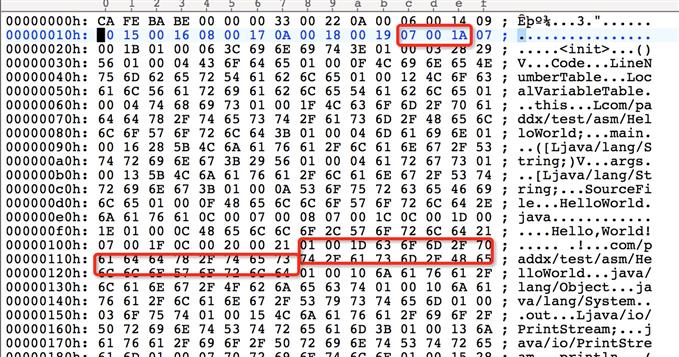
super_class(u2)):super_class是指向constant pool的索引值,该值必须是CONSTANT_Class_info类型,指定当前字节码定义的类或接口的直接父类。这里的取值为00 06,根据上面的分析,对应的指向的全限定性类名为java/lang/object,即当前类的父类为Object类。
interfaces_count(u2):接口的数量,因为这里没有实现接口,所以值为 00 00。
interfaces[interfaces_count]:因为没有接口,所以就不存在interfces选项。
field_count:属性数量,00 00。
field_info:因为没有属性,所以不存在这个选项。
method_count:00 02,为什么会有两个方法呢?我们明明只写了一个方法,这是因为JVM 会自动生成一个 <init>的方法。
method_info:方法表,其结构如下:
| Type | Descriptor |
| u2 | access_flag |
| u2 | name_index |
| u2 | descriptor_index |
| u2 | attributes_count |
| attribute_info | attribute_info[attributes_count] |
HelloWorld.class文件中对应的数据:

access_flag(u2): 00 01
name_index(u2):00 07
descriptor_index(u2):00 08
可以看看 07、08对应的常量池里面的值:
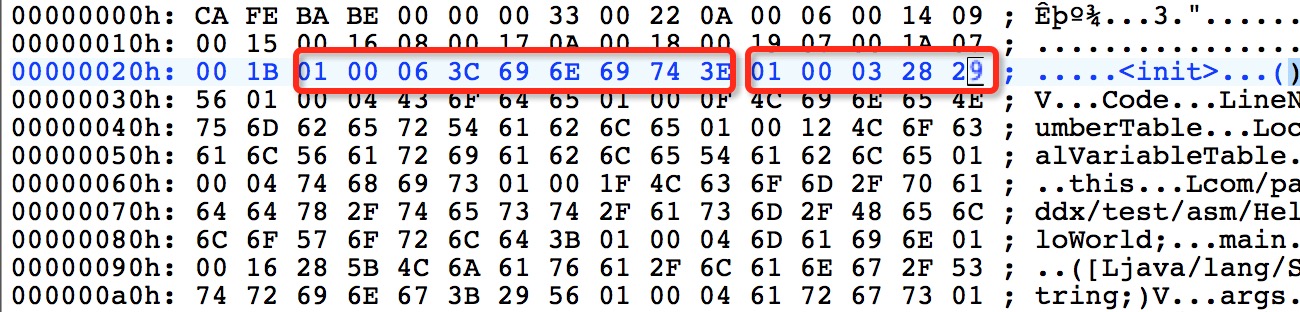
即 07 对应的是 <init>,08 对应的是();
attributes_count:00 01,表示包含一个属性
attribute_info:属性表,该表的结构如下:
| Type | Descriptor |
| u2 | attribute_name_index |
| u4 | attribute_length |
| u1 | bytes |
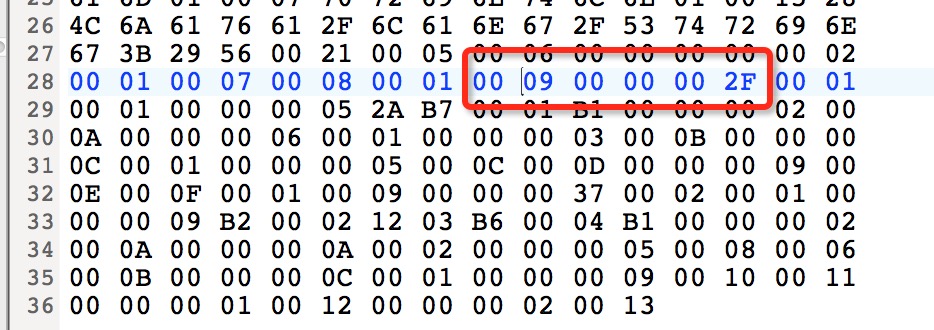
attribute_name_index(u2): 00 09,指向常量池中的索引。
attribute_length(u4):00 00 00 2F,属性的长度47。
attribute_info:具体属性的分析与上面类似,大家可以对着JVM的规范自己尝试分析一下。
第一个方法结束后,接着进入第二个方法:
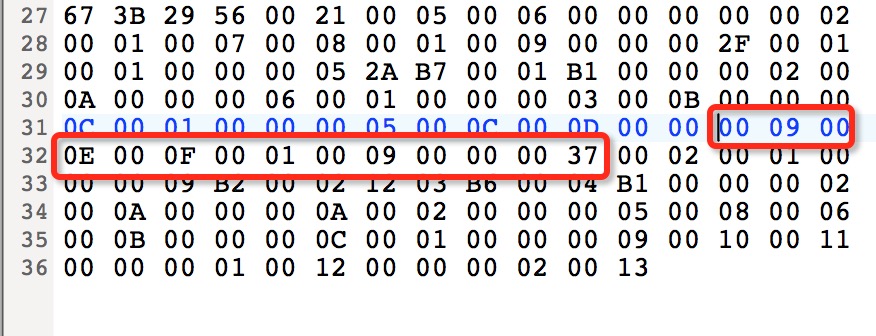
第二个方法的属性长度为x037,转换为十进制为55个字节。两个方法之后紧跟着的是attribute_count和attributes:
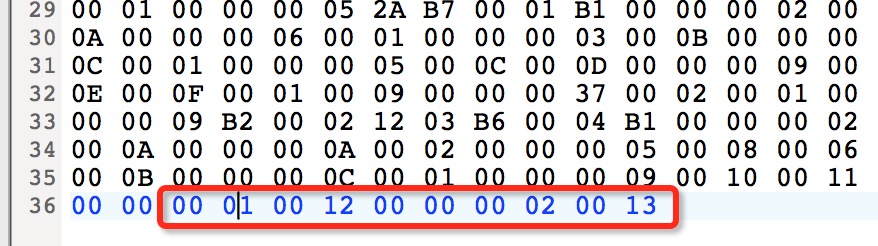
attribute_count(u2):值为 00 01,即有一个属性。
attribute_name_index(u2):指向常量池中的第十二项。
attribute_length(u4):00 00 00 02,长度为2。
分析完毕!
三、基于字节码的操作:
通过对HelloWorld这个程序的字节码分析,我们应该能够比较清楚的认识到整个字节码的结构。那我们通过字节码,可以做些什么呢?其实通过字节码能做很多平时我们无法完成的工作。比如,在类加载之前添加某些操作或者直接动态的生成字节码,CGlib就是通过这种方式来实现动态代理的。现在,我们就来完成另一个版本的HelloWorld:
package com.paddx.test.asm;
public class HelloWorld2 {
public static void sayHello(){
}
}
我们有个空的方法 sayHello(),现在要实现调该方法的时候打印出“HelloWorld”,怎么处理?如果我们手动去修改字节码文件,将打印“HelloWorld”的代码插入到sayHello方法中,原理上肯定没问题,不过操作过程还是比较复杂的。Java 的最大优势就在于只要你能想到的功能,基本上就有第三方开源的库实现过。字节码操作的开源库也比较多,这里我就用 ASM 4.0来实现该功能:
package com.paddx.test.asm;
import org.objectweb.asm.*;
import java.io.IOException;
import java.lang.reflect.InvocationTargetException;
public class AsmDemo extends ClassLoader{
public static void main(String[] args) throws IOException, IllegalAccessException, InstantiationException, InvocationTargetException {
ClassReader classReader = new ClassReader("com.paddx.test.asm.HelloWorld2");
ClassWriter cw=new ClassWriter(ClassWriter.COMPUTE_MAXS);
CustomVisitor myv=new CustomVisitor(Opcodes.ASM4,cw);
classReader.accept(myv, 0);
byte[] code=cw.toByteArray();
AsmDemo loader=new AsmDemo();
Class<?> appClass=loader.defineClass(null, code, 0,code.length);
appClass.getMethods()[0].invoke(appClass.newInstance(), new Object[]{});
}
}
class CustomVisitor extends ClassVisitor implements Opcodes {
public CustomVisitor(int api, ClassVisitor cv) {
super(api, cv);
}
@Override
public MethodVisitor visitMethod(int access, String name, String desc, String signature, String[] exceptions) {
MethodVisitor mv = super.visitMethod(access, name, desc, signature, exceptions);
if (name.equals("sayHello")) {
mv.visitFieldInsn(GETSTATIC, "java/lang/System", "out", "Ljava/io/PrintStream;");
mv.visitLdcInsn("HelloWorld!");
mv.visitMethodInsn(INVOKEVIRTUAL, "java/io/PrintStream", "println", "(Ljava/lang/String;)V");
}
return mv;
}
}
运行结果如下:
关于 ASM 4的操作在这就不细说了。有兴趣的朋友可以自己去研究一下,有机会,我也可以再后续的博文中跟大家分享。
四、总结
本文通过HelloWorld这样一个大家都非常熟悉的例子,深入的分析了字节码文件的结构。利用这些特性,我们可以完成一些相对高级的功能,如动态代理等。这些例子虽然都很简单,但是“麻雀虽小五脏俱全”,即使再复杂的程序也逃离不了这些最基本的东西。技术层面的东西就是这样子,只要你能了解一个简单的程序的原理,举一反三,就能很容易的理解更复杂的程序,这就是技术“易”的方面。同时,反过来说,即使“HelloWorld”这样一个简单的程序,如果我们深入探究,也不一定能特别理解其原理,这就是技术“难”的方面。总之,技术这种东西只要你用心深入地去研究,总是能带给你意想不到的惊喜~
以上是关于从字节码层面看“HelloWorld”的主要内容,如果未能解决你的问题,请参考以下文章