DataFrame.groupby()简析
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了DataFrame.groupby()简析相关的知识,希望对你有一定的参考价值。
groupby分组函数:
返回值:返回重构格式的DataFrame,特别注意,groupby里面的字段内的数据重构后都会变成索引
groupby(),一般和sun()一起使用,如下例:
from pandas import Series,DataFrame
a=[[‘Li‘,‘男‘,‘PE‘,98.],[‘Li‘,‘男‘,‘MATH‘,60.],[‘liu‘,‘男‘,‘MATH‘,60.],[‘yu‘,‘男‘,‘PE‘,100.]]
af=DataFrame(a,columns=[‘name‘,‘sex‘,‘course‘,‘score‘])
af
产生的DataFrame结构为:
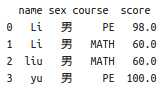
af.groupby([‘name‘,‘course‘])[‘score‘].sum()#先将af按照namej进行分组,再按照score进行分组,最后将score进行叠加
生成的新DataFrame数据结构为:
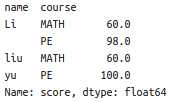
特别注意:groupby里面的字段内的数据重构后都会变成索引
当使用groupby()进行分组之前,name和course字段都为数值字段,不可进行访问,。执行group之前,执行下面代码:
af[‘Li‘]
提示错误!
使用group分组之后,name和course都变成了索引,name为外层索引,course为外层索引。执行下面代码:
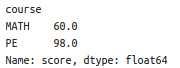
af.groupby([‘name‘,‘course‘])[‘score‘].sum()[‘Li‘]
成功访问到了数据,显示结果:
以上是关于DataFrame.groupby()简析的主要内容,如果未能解决你的问题,请参考以下文章
具有聚合唯一值的pyspark dataframe groupby [重复]
将 Pandas dataframe.groupby 结果写入 S3 存储桶