数据结构与算法-hash表
Posted holoyong
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据结构与算法-hash表相关的知识,希望对你有一定的参考价值。
前言
哈希表是一种存放键-值对的数据结构,其中值用来存放我们真正需要的数据,键的主要目的就是为了找到值。哈希表理想情况下,只需要一次hash计算即可找到值数据,但通常情况下我们不需要耗费巨大的额外空间来追求这丝毫的查找速度(要追求低hash冲突率,必然要扩大hash表),我们更希望的是让空间和时间达到某种平衡,这可以通过调节hash函数来解决(装填因子)。
装填因子=表中的记录数/哈希表的长度,如果装填因子越小,表明表中还有很多的空单元,则发生冲突的可能性越小;而装填因子越大,则发生冲突的可能性就越大,在查找时所耗费的时间就越多(jdk中hashmap的默认装填因子为0.75)。
hash函数
将字符串作为键的时候,我们可以将他作为一个大的整数,采用保留除余法。我们可以将组成字符串的每一个字符取值然后进行哈希,比如
public int getHashCode(string str)
{
char[] s = str.toCharArray();
int hash = 0;
for (int i = 0; i < s.Length; i++)
{
hash = s[i] + (31 * hash);
}
return hash;
}
上面的哈希值是Horner计算字符串哈希值的方法,公式为:
h = s[0] · 31L–1 + … + s[L – 3] · 312 + s[L – 2] · 311 + s[L – 1] · 310
举个例子,比如要获取字符串”call”的哈希值,字符串c对应的unicode为99,a对应的unicode为97,L对应的unicode为108,所以字符串”call”的哈希值为 3045982 = 99·313 + 97·312 + 108·311 + 108·310 = 108 + 31· (108 + 31 · (97 + 31 · (99)))
对计算机而言,乘除是相当昂贵的计算,31*hash等价于hash<<5-hash,位运算要比乘除让计算机更舒服。
避免哈希冲突
避免has冲突的方法有很多,但工程中常用到的是拉链法(Separate chaining with linked lists)。
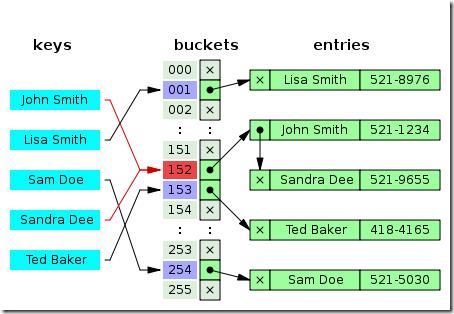
如下图,John Smith和Sandra Dee经过hash后都会映射在152的位置,这就产生了冲突,这里通过将发生冲突的entry(key-value)串连起来解决(串连的方法有很多,最简单的就是一个单链表,复杂一些的可以是二叉平衡树,只要能够进行有效查找的数据结构都可以)。
以上是关于数据结构与算法-hash表的主要内容,如果未能解决你的问题,请参考以下文章