斯坦福机器学习第一周
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了斯坦福机器学习第一周相关的知识,希望对你有一定的参考价值。
一.监督学习和无监督学习
1.监督学习,就是人们常说的分类,通过已有的训练样本(即已知数据以及其对应的输出)去训练得到一个最优模型(这个模型属于某个函数的集合,最优则表示在某个评价准则下是最佳的),再利用这个模型将所有的输入映射为相应的输出,对输出进行简单的判断从而实现分类的目的,也就具有了对未知数据进行分类的能力。
监督学习中可以通过分类预测,也可以通过线性回归来预测。
如果目标变量是离散型,如是 / 否 、 1/2/3 、 ― 冗或者红 / 黄 / 黑 等 ,则可以选择分类器算法;
如果目标变量是连续型的数值,如 0.0~ 100.00 、 -999~999 或者 +00~-00 等 ,则需要选择回归算法。
2.无监督学习则是另一种研究的比较多的学习方法,它与监督学习的不同之处,在于我们事先没有任何训练样本,而需要直接对数据进行建模。这听起来似乎有点不可思议,但是在我们自身认识世界的过程中很多处都用到了无监督学习。比如我们去参观一个画展,我们完全对艺术一无所知,但是欣赏完多幅作品之后,我们也能把它们分成不同的派别(比如哪些更朦胧一点,哪些更写实一些,即使我们不知道什么叫做朦胧派,什么叫做写实派,但是至少我们能把他们分为两个类)。无监督学习里典型的例子就是聚类了.
二.代价函数
对于回归问题,我们需要求出代价函数来求解最优解,常用的是平方误差代价函数。
比如,对于下面的假设函数: 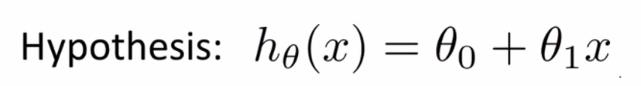
里面有θ0和θ1两个参数,参数的改变将会导致假设函数的变化,比如: 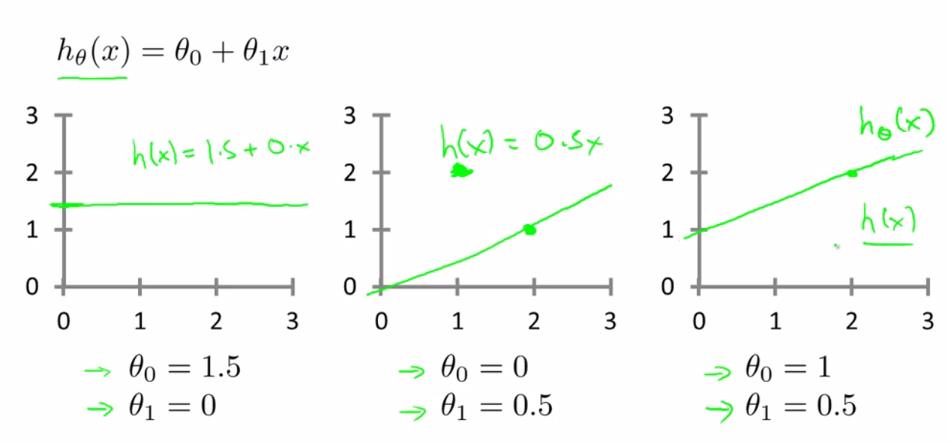
现实的例子中,数据会以很多点的形式给我们,我们想要解决回归问题,就需要将这些点拟合成一条直线,找到最优的θ0和θ1来使这条直线更能代表所有数据。
而如何找到最优解呢,这就需要使用代价函数来求解了,以平方误差代价函数为例。
从最简单的单一参数来看,假设函数为: 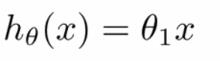
平方误差代价函数的主要思想就是将实际数据给出的值与我们拟合出的线的对应值做差,这样就能求出我们拟合出的直线与实际的差距了。
为了使这个值不受个别极端数据影响而产生巨大波动,采用类似方差再取二分之一的方式来减小个别数据的影响。这样,就产生了代价函数: 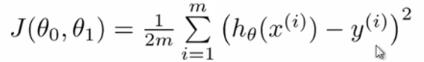 、
、
而最优解即为代价函数的最小值,根据以上公式多次计算可得到
代价函数的图像: 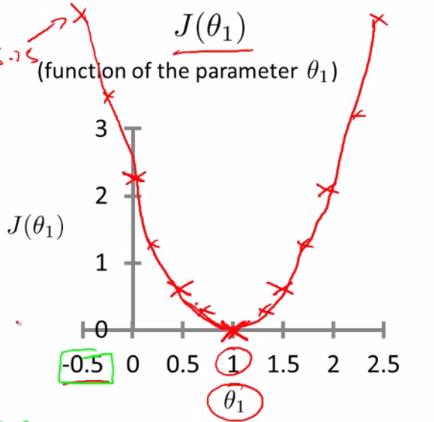
可以看到该代价函数的确有最小值,这里恰好是横坐标为1的时候。
如果更多参数的话,就会更为复杂,两个参数的时候就已经是三维图像了: 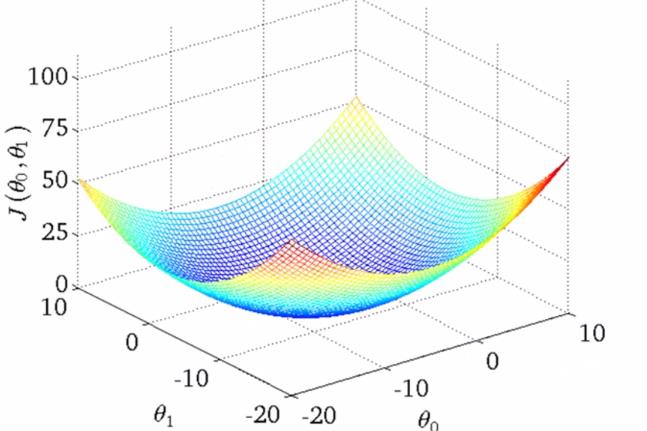
高度即为代价函数的值,可以看到它仍然有着最小值的,而到达更多的参数的时候就无法像这样可视化了,但是原理都是相似的。
因此,对于回归问题,我们就可以归结为得到代价函数的最小值: 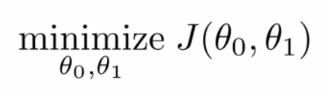
三.梯度下降算法
算法:


 初始值就在local minimum的位置,则会如何变化?已经在local minimum位置,所以derivative 肯定是0,因此不会变化;
初始值就在local minimum的位置,则会如何变化?已经在local minimum位置,所以derivative 肯定是0,因此不会变化;


4.Feature Scaling


以上是关于斯坦福机器学习第一周的主要内容,如果未能解决你的问题,请参考以下文章
斯坦福大学Andrew Ng教授主讲的《机器学习》公开课观后感