爬虫实践---电影排行榜和图片批量下载
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了爬虫实践---电影排行榜和图片批量下载相关的知识,希望对你有一定的参考价值。
1.目标网址:http://dianying.2345.com/top/
需要找到的信息:电影的名字,主演,简介,和标题图片
2.查看页面结构:
容易看到,需要的主题部分,都被包裹在‘<ul>“列表标签里,
那么简单的用bs4库找到 "<ul>" tag并迭代取出每一条“<li>”tag,
最后再从每个<li>标签里找到需要的信息即可。
3.图片下载:
在电影排行榜爬虫当中,有一项目标是:爬取每个电影的标题图,
那么如何以文本的形式爬下来呢?
在计算机的世界里,一切的数据归根到底都是以“0”和“1”的二进制形式存在的。
图片自然也不例外,任何一张图片,都是以“字节流 ”的形式,
通过了一定的编码方式,被计算机排列组合,从而显示成我们肉眼所看到的图片。
那么只要把图片数据从网上下载下来,然后再以二进制的格式写入到本地即可。
给出一个图片下载的通用代码片段:
import requests def get_pic_from_url(url): #从url以二进制的格式下载图片数据 pic_content = requests.get(url,stream=True).content open(‘filename‘,‘wb‘).write(pic_content)
4.完整代码
import requests from bs4 import BeautifulSoup def get_html(url): try: r = requests.get(url,timeout = 30) r.raise_for_status r.encoding = ‘gb2312‘ return r.text except: return ‘error‘ def get_content(url): html = get_html(url) soup = BeautifulSoup(html,‘lxml‘) # 找到电影排行榜的ul列表 movie_list = soup.find(‘ul‘,class_=‘picList clearfix‘) movies = movie_list.find_all(‘li‘) for movie in movies: # 找到图片链接,电影名称 img_url = movie.find(‘img‘)[‘src‘] name = movie.find(‘span‘,class_=‘sTit‘).text #这里做一个异常捕获,防止没有上映时间 try: time = movie.find(‘span‘,class_=‘sIntro‘).text except: time = ‘暂无上映时间‘ # 迭代找出“pACtor”的所有子孙节点,解决每一位演员的名字分割问题 try: actors = movie.find(‘p‘,class_=‘pActor‘).contents actor = ‘‘ for act in actors: actor = actor + act.string + ‘ ‘ except: actor = ‘暂无主演‘ # 找到影片简介 intro = movie.find(‘p‘,class_=‘pTxt pIntroShow‘).text print("片名:{}\\t{}\\n{}\\n{} \\n \\n".format(name,time,actor,intro)) # 把图片下载下来,以二进制读写模式打开 with open(‘C:/Users/Administrator/Desktop/img/‘+name+‘.png‘,‘wb+‘) as f: f.write(requests.get(img_url).content) def main(): url = ‘http://dianying.2345.com/top/‘ get_content(url) if __name__ == ‘__main__‘: main()
5.输出结果
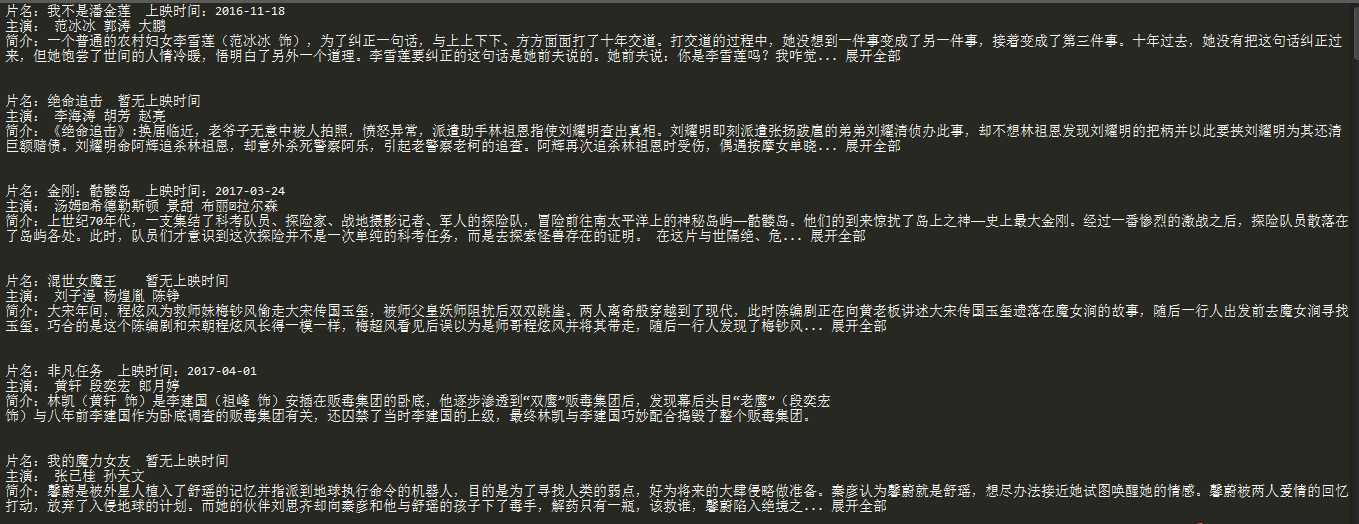
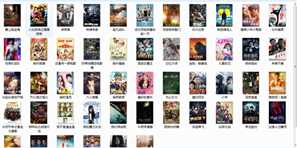
6.注意点
requests的content和text属性的区别:
从print 结果来看是没有任何区别的
resp.text返回的是Unicode型的数据。
resp.content返回的是bytes型也就是二进制的数据。
也就是说,如果想获取文本,可以通过r.text。
如果想取图片,文件,则可以通过r.content。
以上是关于爬虫实践---电影排行榜和图片批量下载的主要内容,如果未能解决你的问题,请参考以下文章