Paper ReadingObject Recognition from Scale-Invariant Features
Posted VincentCheng
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Paper ReadingObject Recognition from Scale-Invariant Features相关的知识,希望对你有一定的参考价值。
Paper: Object Recognition from Scale-Invariant Features
Sorce: http://www.cs.ubc.ca/~lowe/papers/iccv99.pdf
SIFT 即Scale Invariant Feature Transfrom, 尺度不变变换,由David Lowe提出。是CV最著名也最常用的特征。在图像目标识别的应用中,常常要求图像的特征有很好的roboust即不容易受到平移,旋转,尺度缩放,光照,仿射的英雄。SIFT算子具有尺度,旋转不变性,并且具有部分光照,视角不变性。
一、SIFT算子概述
1.1 SIFT 算子的特征
1. 局部性:对occlusion 和 clutter 有较好的鲁棒性
2. 独特性:使用SIFT特征可以将独立的特征匹配到大量物体
3. 多量性:即使是小物体可以生成很多SIFT特征
4. 高效性:有很好的实时性
5. 可扩展性:可以和其他不同的特征结合,增强鲁棒性
1.2 SIFT算子检测步骤
1. 尺度空间和高斯金字塔的构建:尺度空间的构建是为了模拟图像的多尺度特征,就像人眼对不同远近的物体,有不同的大小。
2. 尺度空间的极值检测,确定关键点的位置:检索图像所有的空间,通过高斯微分函数的最大值或者最小值点来确定关键点的位置。
3. 去除不好的关键点:边缘和第对比度的区域都是不好的关键点,去除不好的描述子能够使得算法更加efficient和roboust。 可以使用Harris Corner Detector
4. 根据关键点领域内的梯度信息确定关键点的主方向,后续的计算都是针对这个方向进行的,确定关键点的方向,使得key points 具有 rotataion invariant特性。
5. 生成SIFT描述子:前面的的尺度空间的关键点方向使得keypoints 具有 scale and rotation invariant接下来就可以直接生成SIFT算子了。
二、 算法原理
1. 尺度空间和空间金字塔的构建
对于实际场景而言,物体都是以一定尺度呈现的,而图像汇总物体大小是固定的。尺度空间的构建就是为了在数字图像中呈现现实世界人对图像的多尺度感知——距离和模糊程度。这样可以提高算法对物体的识别准确度。为了实现这两个目的SIFT算法使用两个步骤:1)降采样构建高斯金字塔 2) 使用高斯核构建多尺度空间。Lindeberg证明了高斯及其微分核是尺度空间分析中唯一线性的平滑核。我们先使用高斯函数:$G(x) = \\frac{1}{\\sqrt{2\\pi}\\sigma}e^{-x^2/2\\sigma^2}$来构建尺度空间。对于二维图像其对应二维高斯核函数可以定义为$G(x,y,\\sigma) = \\frac{1}{\\sqrt{2\\pi}\\sigma}e^{-(x^2+y^2)/2\\sigma^2}$.
一幅图像$I(x,y)$和高斯核函数卷积可以得到:
$$L(x,y,\\sigma) = G(x,y,\\sigma)*I(x,y) $$
参数$\\sigma$决定图像的分辨率,$\\sigma$越大图像越模糊。这便是原图像的尺度空间表示。
这一步仅仅是实现了不同图像的模糊程度模拟,我们还需要实现对不同大小图像的表示。这个可以直接通过对图像进行降采样得到。这样对于原图像我们使用高斯函数卷积达到不同模糊程度(不同$\\sigma$)关键点,这对应的是一个octave。然后我们对原图像降采样(比如将图像变为原来大小的一半)然后对新得到图像再次使用高斯函数卷积得到下一个octave,这样一直重复我们就可以得到多个octave,每个octave中有多个不同尺度模糊图像,所有的octave构成高斯金字塔。下面是其示意图:

2. 尺度空间极值检测
建立好高斯金字塔之后我们开始检测兴趣点(interest points),我们可以使用LOG(Laplacian of Gaussian)来检测图像中我们需要的兴趣点(边缘,角点)。然而LOG 很容易受到噪声的干扰,这也是我们之前对图像做Blur模糊的原因之一。LOG计算公式如下:
$$\\Delta^2 = \\frac{\\partial^2}{\\Delta_x^2}+\\frac{\\partial^2}{\\Delta_y^2}$$
但是二阶倒数计算起来太困难,于是我们选取了一个替代方案来近似LOG:使用DOG(Difference of Gaussian)计算公式如下:
$$D(x,y,\\sigma) = \\left(G(x,y,k\\sigma)-G(x,y,\\sigma) \\right)*I(x,y)$$
使用DOG 我们计算得到稳定的keypoints。我们可以使用前面够贱的高斯金字塔,相邻高斯金字塔相减得到DOG空间。
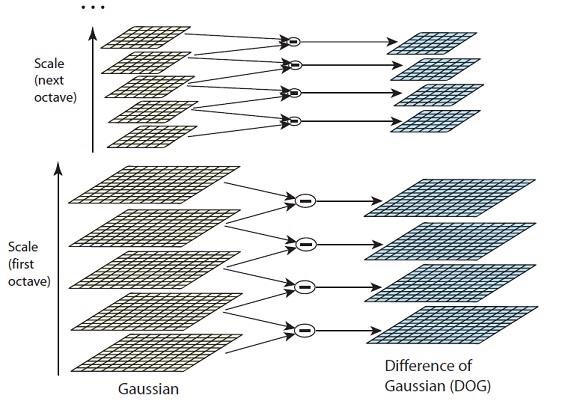
3. 去除不好的关键点
4. 给关键点赋方向
5. 生成SIFT features
以上是关于Paper ReadingObject Recognition from Scale-Invariant Features的主要内容,如果未能解决你的问题,请参考以下文章