spark性能调优 spark shuffle中JVM内存使用及配置内幕详情
Posted 人生,唯有锻炼与读书不能辜负
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了spark性能调优 spark shuffle中JVM内存使用及配置内幕详情相关的知识,希望对你有一定的参考价值。
转载:http://www.cnblogs.com/jcchoiling/p/6494652.html
引言
Spark 从1.6.x 开始对 JVM 的内存使用作出了一种全新的改变,Spark 1.6.x 以前是基于静态固定的JVM内存使用架构和运行机制,如果你不知道 Spark 到底对 JVM 是怎么使用,你怎么可以很有信心地或者是完全确定地掌握和控制数据的缓存空间呢,所以掌握Spark对JVM的内存使用内幕是至关重要的。很多人对 Spark 的印象是:它是基于内存的,而且可以缓存一大堆数据,显现 Spark 是基于内存的观点是错的,Spark 只是优先充分地利用内存而已。如果你不知道 Spark 可以缓存多少数据,你就误乱地缓存数据的话,肯定会有问题。
在数据规模已经确定的情况下,你有多少 Executor 和每个 Executor 可分配多少内存 (在这个物理硬件已经确定的情况下),你必须清楚知道你的內存最多能够缓存多少数据;在 Shuffle 的过程中又使用了多少比例的缓存,这样对于算法的编写以及业务实现是至关重要的!!!
文章的后部份会介绍 Spark 2.x 版本 JVM 的内存使用比例,它被称之为 Spark Unified Memory,这是统一或者联合的意思,但是 Spark 没有用 Shared 这个字,因为 A 和 B 进行 Unified 和 A 和 B 进行 Shared 其实是两个不同的概念, Spark 在运行的时候会有不同类型的 OOM,你必须搞清楚这个 OOM 背后是由什么导致的。 比如说我们使用算子 mapPartition 的时候,一般会创建一些临时对象或者是中间数据,你这个时候使用的临时对象和中间数据,是存储在一个叫 UserSpace 里面的用户操作空间,那你有没有想过这个空间的大小会导致应用程序出现 OOM 的情况,在 Spark 2.x 中 Broadcast 的数据是存储在什么地方;ShuffleMapTask 的数据又存储在什么地方,可能你会认为 ShuffleMapTask 的数据是缓存在 Cache 中。这篇文章会介绍 JVM 在 Spark 1.6.X 以前和 2.X 版本对 Java 堆的使用,还会逐一解密上述几个疑问,也会简单介绍 Spark 1.6.x 以前版本在 Spark On Yarn 上内存的使用案例,希望这篇文章能为读者带出以下的启发:
- 了解 JVM 内存使用架构剖析
- 了解 JVM 在 Spark 1.6.x 以前和 Spark 2.x 中可以缓存多少数据
- 了解 Spark Unified Memory 的原理与机制还有它三大核心空间的用途
- 了解 Shuffle 在 Spark 1.6.x 以前和 Spark 2.x 中可以使用多少缓存
- 了解 Spark1.6.x 以前 on Yarn 对内存的使用
- 了解 在 Spark 1.6.x 以前和 Spark 2.x Shuffle 的参数配置
一、JVM内存使用架构剖析
JVM 有很多不同的区,最开始的时候,它会通过类装载器把类加载进来,在运行期数据区中有 "本地方法栈","程序计数器","Java 栈"、"Java 堆"和"方法区"以及本地方法接口和它的本地库。从 Spark 的角度来谈代码的运行和数据的处理,主要是谈 Java 堆 (Heap) 空间的运用。
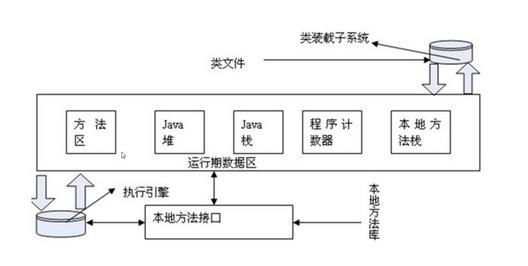
- 本地方法栈:这个是在迭归的时候肯定是至关重要的;
- 程序计数器:这是一个全区计数器,对于线程切换是至关重要的;
- Java 栈 (Stack):Stack 区属于线程私有,高效的程序一般都是并发的,每个线程都会包含一个 Stack 区域,Stack 区域中含有基本的数据类型以及对象的引用,其它线程均不能直接访问该区域;Java 栈分为三大部份:基本数据类型区域、操作指令区域、上下文等;
- Java 堆 (Heap):存储的全部都是 Object 对象实例,对象实例中一般都包含了其数据成员以及与该对象对应类的信息,它会指向类的引用一个,不同线程肯定要操作这个对象;一个 JVM 实例在运行的时候只有一个 Heap 区域,而且该区域被所有的线程共享;补充说明:垃圾回收是回收堆 (heap) 中内容,堆上才有我们的对象。
- 方法区:又名静态成员区域,包含整个程序的 class、static 成员等,类本身的字节码是静态的;它会被所有的线程共享和是全区级别的;
二、Spark 1.6.x 和 2.x 的 JVM 剖析
1、Spark JVM 到底可以缓存多少数据
下图显示的是Spark 1.6.x 以前版本对 Java 堆 (heap) 的使用情况,左则是 Storage 对内存的使用,右则是 Shuffle 对内存的使用,这叫 StaticMemoryManagement,数据处理以及类的实体对象都存放在 JVM 堆 (heap) 中。

2、Spark 1.6.x 版本对 JVM 堆的使用
JVM Heap 默认情况下是 512MB,这是取决于 spark.executor.memory 的参数,在回答 Spark JVM 到底可以缓存多少数据这个问题之前,首先了解一下 JVM Heap 在 Spark 中是如何分配内存比例的。无论你定义了 spark.executor.memory 的内存空间有多大,Spark 必然会定义一个安全空间,在默认情况下只会使用 Java 堆上的 90% 作为安全空间,在单个 Executor 的角度来讲,就是 Heap Size x 90%。
埸景一:假设说在一个Executor,它可用的 Java Heap 大小是 10G,实际上 Spark 只能使用 90%,这个安全空间的比例是由 spark.storage.safetyFaction 来控制的。(如果你内存的 Heap 非常大的话,可以尝试调高为 95%),在安全空间中也会划分三个不同的空间:一个是 Storage 空间、一个是 Unroll 空间和一个是 Shuffle 空间。
安全空间 (safe):计算公式是 spark.executor.memory x spark.storage.safetyFraction。也就是 Heap Size x 90%,在埸景一的例子中是 10 x 0.9 = 9G;
缓存空间 (Storage):计算公式是 spark.executor.memory x spark.storage.safetyFraction x spark.storage.memoryFraction。也就是 Heap Size x 90% x 60%;Heap Size x 54%,在埸景一的例子中是 10 x 0.9 x 0.6 = 5.4G;一个应用程序可以缓存多少数据是由 safetyFraction 和 memoryFraction 这两个参数共同决定的。
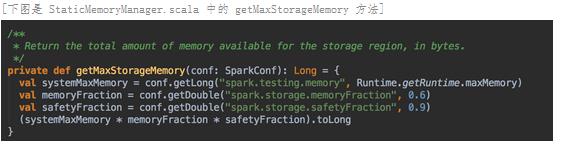
Unroll 空间:
计算公式是 spark.executor.memory x spark.storage.safetyFraction x spark.storage.memoryFraction x spark.storage.unrollFraction
也就是 Heap Size x 90% x 60% x 20%;Heap Size x 10.8%,在埸景一的例子中是 10 x 0.9 x 0.6 x 0.2 = 1.8G,你可能把序例化后的数据放在内存中,当你使用数据时,你需要把序例化的数据进行反序例化。

对 cache 缓存数据的影响是由于 Unroll 是一个优先级较高的操作,进行 Unroll 操作的时候会占用 cache 的空间,而且又可以挤掉缓存在内存中的数据 (如果该数据的缓存级别是 MEMORY_ONLY 的话,否则该数据会丢失)。
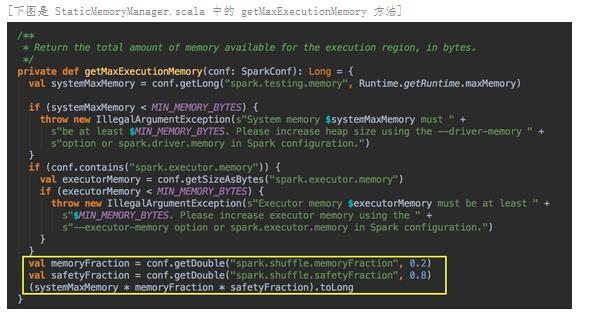
Shuffle 空间:
计算公式是 spark.executor.memory x spark.shuffle.memoryFraction x spark.shuffle.safteyFraction。在 Shuffle 空间中也会有一个默认 80% 的安全空间比例,所以应该是 Heap Size x 20% x 80%;Heap Size x 16%,在埸景一的例子中是 10 x 0.2 x 0.8 = 1.6G;从内存的角度讲,你需要从远程抓取数据,抓取数据是一个 Shuffle 的过程,比如说你需要对数据进行排序,显现在这个过程中需要内存空间。
3、Spark Unified Memory 原理和运行机制
下图是一种叫联合内存 (Spark Unified Memeory),数据缓存与数据执行之间的内存可以相互移动,这是一种更弹性的方式,下图显示的是 Spark 2.x 版本对 Java 堆 (heap) 的使用情况,数据处理以及类的实体对象存放在 JVM 堆 (heap) 中。

以上是关于spark性能调优 spark shuffle中JVM内存使用及配置内幕详情的主要内容,如果未能解决你的问题,请参考以下文章