栈和队列的常见题型
Posted 滴巴戈
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了栈和队列的常见题型相关的知识,希望对你有一定的参考价值。
一、常见题型如下:
1. 实现一个栈,要求实现Push(出栈)、Pop(入栈)、Min(返回最小值的操作)的时间复杂度为O(1)
2. 使用两个栈实现一个队列
3. 使用两个队列实现一个栈
4. 元素出栈、入栈顺序的合法性。如入栈的序列(1,2,3,4,5),出栈序列为(4,5,3,2,1)
5. 一个数组实现两个栈。
二、解法分析及示例代码
1.第一题最小值栈
前两种操作Push(出栈)、Pop(入栈)比较好实现,也是栈中比较基本的操作,题目没有明确要求所以我们可以直接用STL容器,进行个封装即可,stack中这两个操作的时间复杂度就是O(1),但是第三个操作Min(返回最小值的操作)的时间复杂度为O(1),则要我们自己想办法。思路是用两个栈,一个就是普通的存取数据的栈,另一个为当前栈未知的最小值,因为出栈入栈都会使当前栈的最小值发生变化,所以插入数据和删除数据两个栈都要进行操作,返回当前栈最小值的话,就可以直接对第二个栈操作。
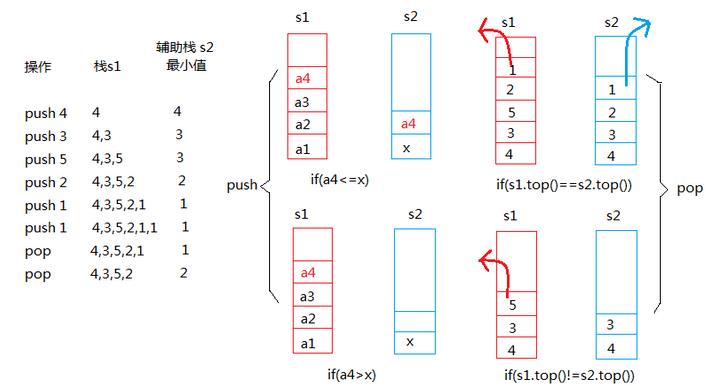
★使用两个栈,s1,s2,先将第一个元素同时对s1,s2入栈,然后接着对s1入栈,将s1入栈的元素和s2.top比较,假如s2.top大于入栈元素,则把该元素对s2也入栈(☛s2.top和入栈元素相等时也要入栈S2);否则将下一个元素对主栈S1入栈,依次进行;
★出栈时,把s1出栈的元素和栈顶(s2.top)比较,相等就是最小值;同时s1,s2出栈,否则s1单独出栈。
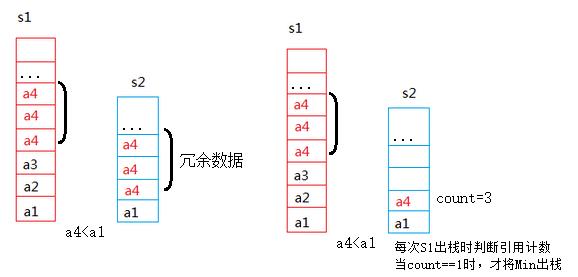
这种方法在出现大量重复的数据情况下辅助栈也会保存大量重复的最小值数据,这时空间利用率较低。这个时候就想到了另一种方案,就是引用计数,将重复的最小值数据用引用计数来实现存储。实现图示如下:
代码示例:
1 template <class T> 2 class MyStack 3 { 4 public: 5 void Push(const T& x) 6 { 7 _st.push(x); //数据栈先入栈 8 if (min_st.empty()) //如果Min栈之前没有数据,则直接入栈 9 { 10 min_st.push(make_pair(x, 1); //x入Min栈,并置计数为1 11 } 12 else { 13 pair<T, count>& _min = min_st.top(); 14 if (x < _min.first) //如果入数据栈的数据小于Min栈顶数据,则也入MIn栈 15 { 16 min_st.push(make_pair(x, 1)); //x入Min栈,并置计数为1 17 }else if (x == _min.first) //如果入数据栈的数据等于Min栈顶数据,即出现冗余数据,计数加1 18 { 19 _min.second++; 20 } 21 } 22 } 23 void Pop() 24 { 25 assert(!_st.empty()); 26 pair<x, count>& _min = min_st.top(); 27 if (_st.top() == _min.first) 28 { 29 if (--_min.second == 0) //计数为1时,最小值出栈,否则计数减1 30 { 31 min_st.pop(); 32 } 33 } 34 _st.pop(); 35 } 36 T Min() 37 { 38 return min_st.top(); 39 } 40 private: 41 stack<T> _st; //数据栈 42 stack<pair<T, count>> min_st; //最小值栈 43 };
2.两个栈实现一个队列
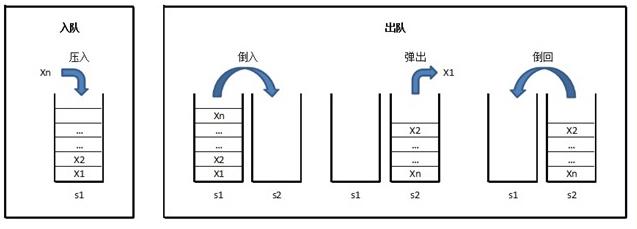
思路是:两个栈s1,s2,始终维护s1作为存储空间,以s2作为临时缓冲区。
入队时,将元素压入s1。
出队时,将s1的元素逐个“倒入”(弹出并压入)s2,将s2的顶元素弹出作为出队元素,之后再将s2剩下的元素逐个“倒回”s1。
见下面示意图:
实现代码如下:
1 template <class T> 2 class TwoStackQueue 3 { 4 public: 5 void Push(T k) 6 { 7 s1.push(k); 8 } 9 void Pop() 10 { 11 if (s1.empty() && s2.empty() == false) { 12 while (s1.empty()) 13 { 14 s2.push(s1.top()); 15 s1.pop(); 16 } 17 s2.pop(); 18 while (s2.empty()) 19 { 20 s1.push(s2.top()); 21 s2.pop(); 22 } 23 } 24 } 25 private: 26 stack<T> s1; 27 stack<T> s2; 28 };
这个题还可以优化一下。即:在出队时,将s1的元素逐个“倒入”s2时,原在s1栈底的元素,不用“倒入”s2(即只“倒”s1.Count()-1个),可直接弹出作为出队元素返回。这样可以减少一次压栈的操作。
上述思路,有些变种,如:
入队时,先判断s1是否为空,如不为空,说明所有元素都在s1,此时将入队元素直接压入s1;如为空,要将s2的元素逐个“倒回”s1,再压入入队元素。
出队时,先判断s2是否为空,如不为空,直接弹出s2的顶元素并出队;如为空,将s1的元素逐个“倒入”s2,把最后一个元素弹出并出队。
相对于第一种方法,变种的s2好像比较“懒”,每次出队后,并不将元素“倒回”s1,如果赶上下次还是出队操作,效率会高一些,但下次如果是入队操作,效率不如第一种方法。我感觉(没做深入研究),入队、出队操作随机分布时,上述两种方法总体上时间复杂度和空间复杂度应该相差无几(无非多个少个判断)。
真正性能较高的,其实是另一个变种。即:
入队时,将元素压入s1。
出队时,判断s2是否为空,如不为空,则直接弹出顶元素;如为空,则将s1的元素逐个“倒入”s2,把最后一个元素弹出并出队。
这个思路,避免了反复“倒”栈,仅在需要时才“倒”一次。
3.两个队列实现一个栈
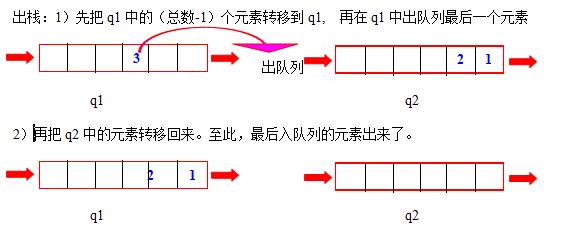
思路是:q1是专职进出栈的,q2只是个中转站
入栈:直接入队列q1即可
出栈:把q1的除最后一个元素外全部转移到队q2中,然后把刚才剩下q1中的那个元素出队列。之后把q2中的全部元素转移回q1中。

代码示例:
1 template<class T> 2 class Queue 3 { 4 public: 5 void Push(const T& x) 6 { 7 _in.push(x); 8 } 9 10 void Pop() 11 { 12 assert(!_in.empty() || !_out.empty()); 13 14 if (_out.empty()) 15 { 16 while (!_in.empty()) 17 { 18 _out.push(_in.top()); 19 _in.pop(); 20 } 21 } 22 23 _out.pop(); 24 } 25 26 T& Front() 27 { 28 assert(!_in.empty() || !_out.empty()); 29 30 if (_out.empty()) 31 { 32 while (!_in.empty()) 33 { 34 _out.push(_in.top()); 35 _in.pop(); 36 } 37 } 38 39 return _out.top(); 40 } 41 42 43 private: 44 stack<T> _in; 45 stack<T> _out; 46 };
思路二:
q1是专职进出栈的,q2只是个中转站。元素集中存放在一个栈中,但不是指定(q1 或 q2)。定义两个指针:pushtmp:指向专门进栈的队列q1; tmp:指向临时作为中转站的另一个栈q2
入栈:直接入pushtmp所指队列即可
出栈:把pushtmp的除最后一个元素外全部转移到队列tmp中,然后把刚才剩下q1中的那个元素出队列
示例代码二:
1 void Push(Queue *q1, Queue *q2, int k) 2 { 3 Queue *pushtmp; 4 if(!IsQueueEmpty(q1)) 5 { 6 pushtmp = q1; 7 } 8 else 9 { 10 pushtmp = q2; 11 } 12 EnQueue(pushtmp, k); 13 } 14 15 int Pop(Queue *q1, Queue *q2) 16 { 17 int tmpvalue; 18 Queue *pushtmp, *tmp; 19 if(!IsQueueEmpty(q1)) 20 { 21 pushtmp = q1; 22 tmp = q2; 23 } 24 else 25 { 26 pushtmp = q2; 27 tmp = q1; 28 } 29 30 if(IsQueueEmpty(pushtmp)) 31 { 32 printf("Stack Empty!\\n"); 33 } 34 else 35 { 36 while(SizeOfQueue(pushtmp) != 1) 37 { 38 EnQueue(tmp, DeQueue(pushtmp)); 39 } 40 tmpvalue = DeQueue(pushtmp); 41 return tmpvalue; 42 } 43 }
比较: 在第二种思路中,出栈后就不用转移回原来的栈了(图示最后一步),这样减少了转移的次数。
4.元素出栈、入栈顺序的合法性
这是比较常见的判断出栈顺序是否合法性的题目,思路是:
1)用一个 st 栈做入栈序列(1,2,3,4,5)出入栈操作,然后定义指针 in 和 out ,in 指向入栈序列,out 指向需要判断的出栈序列;
2)将入栈序列第一个数据入栈,如果此数据与第一个出栈序列数据相等,则再出栈,再比较两个序列的第二个数据;
3)若不相等,入栈序列第二个数据入栈,再与出栈序列比较;
4)若入栈序列遍历完且临时栈已空,而出栈序列没完,则不合法,若出栈序列也遍历完,则合法。

示例代码:
1 bool IsInvalidStack(char* in, char* out) 2 { 3 assert(in && out); 4 5 stack<char> st; 6 while (1) 7 { 8 while (!st.empty()) 9 { 10 if (*out && st.top() == *out) 11 { 12 st.pop(); 13 ++out; 14 } 15 else 16 { 17 break; 18 } 19 } 20 21 if (*in) 22 { 23 st.push(*in); 24 ++in; 25 } 26 else 27 { 28 if (*out) 29 { 30 return false; 31 } 32 else 33 { 34 return true; 35 } 36 } 37 } 38 } 39 void TestIsInvalidStack() 40 { 41 char* in = "12345"; 42 char* out = "45321"; 43 cout<<IsInvalidStack(in, out)<<endl; 44 }
5.一个数组实现两个栈
这个题有多种思路解题:
①奇偶位存储:数组的奇数位置存储一个栈的元素,偶数位置存储另一个栈的元素;
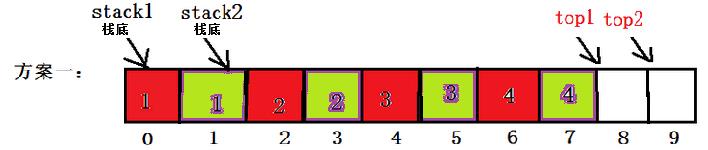
示例代码:
1 template<class T, size_t N> 2 class DoubleStack 3 { 4 public: 5 DoubleStack() 6 :_top1(-2) 7 ,_top2(-1) 8 {} 9 10 void Check(int pos) 11 { 12 if (pos >= _a.size()) 13 { 14 _a.resize(pos*2); 15 } 16 } 17 18 void Push1(const T& x) 19 { 20 Check(_top1+2); 21 _a[_top1+2] = x; 22 } 23 24 void Push2(const T& x) 25 { 26 _a[_top2+2] = x; 27 } 28 29 private: 30 vector<T> _a; 31 int _top1; 32 int _top2; 33 };
②左右存储:两个栈分别从数组的中间向两头增长; 数组的中间位置看做两个栈的栈底,压栈时栈顶指针分别向两边移动,当任何一边到达数组的起始位置或是数组尾部,则开始扩容;
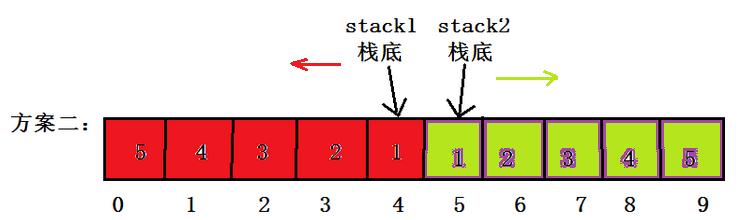
实际上方法二与方法一空间利用率相当本质上相同,所以方法二代码就不实现了。
③两端生长:两个栈分别从数组的两头开始增长。 将数组的起始位置看作是第一个栈的栈底,将数组的尾部看作第二个栈的栈底, 压栈时,栈顶指针分别向中间移动,直到两栈顶指针相遇,则扩容;
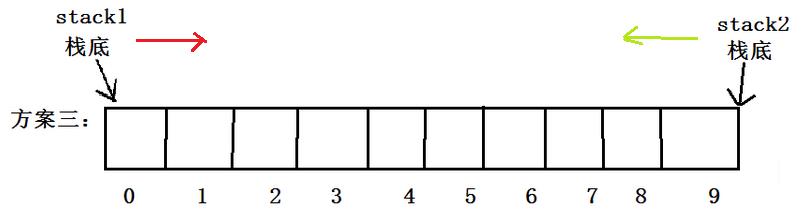
示例代码:
1 //两个栈分别从数组的两头开始向中间增长。 2 template <class T> 3 class DoubleStack2 4 { 5 public: 6 void Push(int index, T data) 7 { 8 if (top1 > top2) //已满 9 return; 10 if (index == 0) { //对栈1操作 11 top1++; 12 array[top1] = data; 13 } 14 else if(index == 1) { //对栈2操作 15 top2--; 16 array[top2] = data; 17 } 18 } 19 void Pop(int index) 20 { 21 if (index == 0) { //对栈1操作 22 if (top1 >= 0) //栈1不为空时 23 top1--; 24 } 25 else if (index == 1) { //对栈2操作 26 if (top2 < MAX) //栈2不为空时 27 top2++; 28 } 29 } 30 T& top(int index) 31 { 32 if (index == 0 && top1 > 0) { //对栈1操作 33 return array[top1 - 1]; 34 } 35 if (index ==1 && top2 < MAX) { 36 return array[top2 + 1] 37 } 38 } 39 private: 40 T* array[MAX]; 41 int top1; 42 int top2; 43 };
前两种方法在一定的情况下会造成空间的浪费,比如当一个栈存满了而另一个栈还是空的,这时候空间利用率不高,所以建议采用第三种方式完成。当一个栈一直入栈,另一个栈一直出栈时,方法三的空间利用率是比较好的。
以上是关于栈和队列的常见题型的主要内容,如果未能解决你的问题,请参考以下文章