oracle用rowid去掉重复值
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了oracle用rowid去掉重复值相关的知识,希望对你有一定的参考价值。
过滤重复数据用distinct,不过distinct会排序导致数据库消耗变多
rowid是伪列,一般在索引的回读中有用
两张表关联有很多
等值连接和不等值连接
内链接
外连接
自连接
一般两张表通过主键外键连接,连接条件数=表数-1 参考技术A 你可以将这个操作看做一个嵌套循环;
对test表的每一条记录,到test中找出所有a,b字段与当前字段一样的记录,找出其rowid最大值,跟当前记录的rowid比较,如果不等于则删除,如果相等,则保留。
所以,本条sql的功能是对所有a,b字段重复的记录,只保留一条。
就是说,本sql等价于下面的sql
delete
from
test
t
where
rowid
not
in
(
select
max(rowid)
from
test
group
by
a,b
)
oracle数据库:去除重复记录 rowid
rowid介绍
rowid是oracle中的一个重要的概念。用于定位数据库中一条记录的一个相对唯一的地址值。通常情况下,该值在该行数据插入到数据库表时即被确定且唯一。rowid它是一个伪列,它并不实际存在于表中。它是oracle在读取表中数据行时,根据每一行数据的物理地址信息编码而成的一个伪列。所以根据一行数据的rowid能找到一行数据的物理地址信息,从而快速地定位到数据行。数据库的大多数操作都是通过rowid来完成的,而且使用rowid来进行单行记录定位速度是最快的。
- 有时繁杂的数据检索时,普通检索条件不能达到要求,可以利用
rowid来精确检索结果。
oracle中如果要查询某张表中的多个字段,又只对某个字段去重的时候用distinct关键字或者group by都不行,【distinct和group by会对要查询的字段一起进行去重,也就是当查询的所有字段都相同,oracle才会认为是重复的】,这时可以使用rowid。
重复记录的查找
题目场景:当我们表里面出现了许多的重复记录时,我们需要将重复的记录找出来。
实现步骤:
- 按照重复内容分组
- 取出每一组的一条记录并且保留【注意具有唯一性】
- 删除未在保留范围的数据
准备数据:test表
--创建test表
create table test(
name varchar(20),
age number(3),
sex varchar(10),
weight number(3)
)
上面定义了4个字段,分别是姓名,年龄,性别,体重。接下来往里面添加数据。
--添加数据
insert into test values('貂蝉',22,'女',96);
insert into test values('小乔',24,'女',95);
insert into test values('孙尚香',21,'女',92);
insert into test values('露娜',20,'女',94);
insert into test values('女娲',26,'女',97);
insert into test values('甄姬',23,'女',91);
insert into test values('安琪拉',22,'女',98);
insert into test values('貂蝉',22,'女',96);
insert into test values('小乔',24,'女',95);
insert into test values('孙尚香',21,'女',92);
insert into test values('露娜',20,'女',94);
insert into test values('女娲',26,'女',97);
insert into test values('甄姬',23,'女',91);
insert into test values('安琪拉',22,'女',98);
这里故意添加一些重复的数据,接下来要用到这些,现在看一下表中的内容:
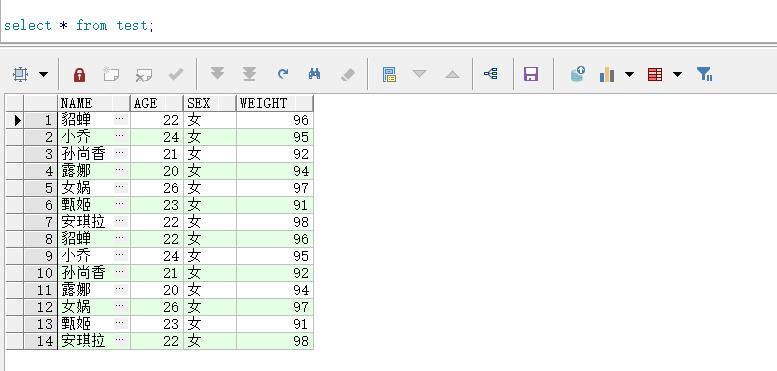
可以看到表中重复数据的内容也一模一样,来查看一下rowid
--查看rowid
select name,age,sex,weight,rowid from test order by age desc;
这里为了方便比较相同内容的rowid是不是一样,使用了排序。
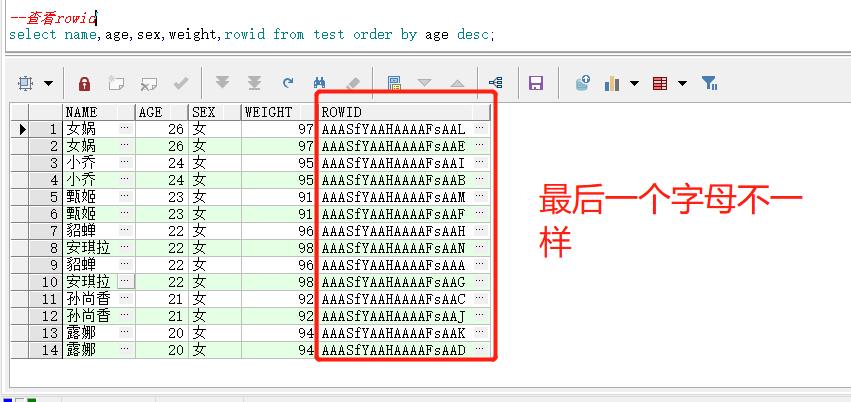
可以看到尽管内容都一样,但是rowid不一样。
现在来完成一个操作:将所有相同的记录只保留一份
- 将数据进行分组,按照重复信息分组
- 在每一组里面选取一条记录进行保存,取出特性:
rowid - 删除时,找那些不在保留范围内的数据,将不再范围的数据删除。
--将数据进行分组,按照重复信息分组
select name,sex,age,weight from test group by name,sex,age,weight;
将数据分组,这里将所有信息都查出来:
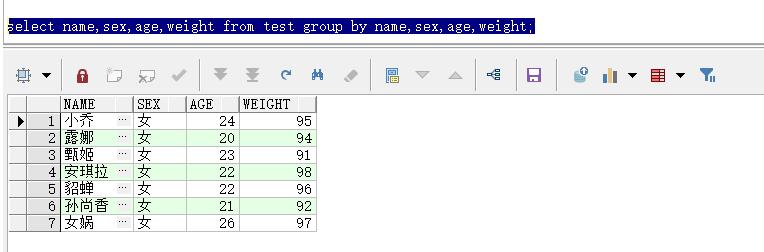
一共有7组数据,现在要每组数据取一条数据出来,因为其他的字段内容都相同,这里只能取rowid。
--找到每组最小的rowid,也可以取最大的
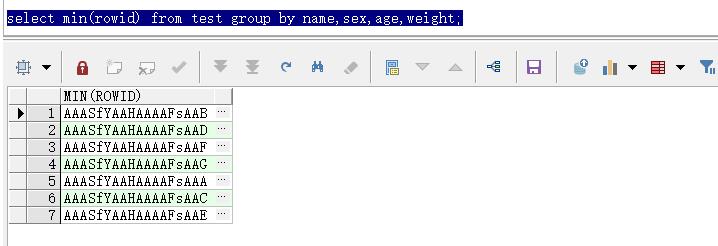
select min(rowid) from test group by name,sex,age,weight;
这里每组都取了一个rowid,如下图所示:
接下来只需要把不在这里的rowid的行删除即可,先把不在里面的rowid的行找出来:
--找到要删除的数据
select * from test where rowid not in (select min(rowid) from test group by name,sex,age,weight);
这里以刚才的结果集为查询目标,用not in函数找到要删除的rowid。
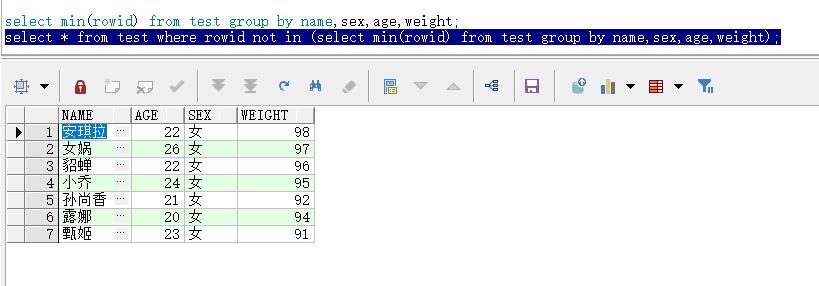
这里没有显示rowid,所有看不到,接下来只需要把这些数据删除即可:
delete from test where rowid not in (select min(rowid) from test group by name,sex,age,weight);
commit;
执行完删除之后提交一下事务,接着来查询表中所有数据看看:
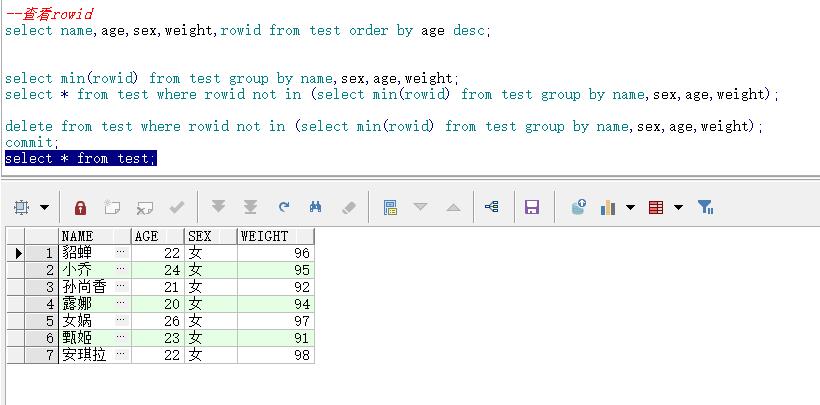
可以看到重复的数据都只有一条了,这就是rowid去除重复记录的用法。
以上是关于oracle用rowid去掉重复值的主要内容,如果未能解决你的问题,请参考以下文章