哈希是什么?为什么哈希存取比较快?
Posted 阿丙的博客园
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了哈希是什么?为什么哈希存取比较快?相关的知识,希望对你有一定的参考价值。
不太恰当的比喻:
XM 指的是“小明”,也指的是“小萌”
XM就是哈希值,小明和小萌就是拥有同一个哈希值的,存在同一个链表的元素。
想要获取小萌,首先使用hashcode获取到这两个人,然后再通过equals获取到小萌。
个人理解
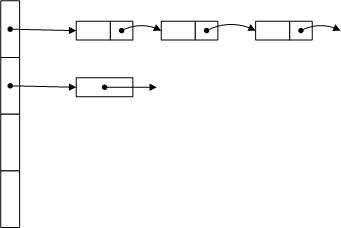
哈希表其实就是一个一维数组,而数组中的每一个元素都是一个单向链表而已。这样的数据结构解决了数组的增删元素的不足和链表的查询效率的不足。
数组是存在连续的存储空间,而链表的存储空间不连续
--------------------------------
哈希算法将任意长度的二进制值映射为固定长度的较小二进制值,这个小的二进制值称为哈希值。哈希值是一段数据唯一且极其紧凑的数值表示形式。如果散列一段明文而且哪怕只更改该段落的一个字母,随后的哈希都将产生不同的值。要找到散列为同一个值的两个不同的输入,在计算上是不可能的,所以数据的哈希值可以检验数据的完整性。
哈希表是根据设定的哈希函数H(key)和处理冲突方法将一组关键字映象到一个有限的地址区间上,并以关键字在地址区间中的象作为记录在表中的存储位置,这种表称为哈希表或散列,所得存储位置称为哈希地址或散列地址。作为线性数据结构与表格和队列等相比,哈希表无疑是查找速度比较快的一种。
哈希通过将单向数学函数(有时称为“哈希算法”)应用到任意数量的数据所得到的固定大小的结果。如果输入数据中有变化,则哈希也会发生变化。哈希可用于许多操作,包括身份验证和数字签名。也称为“消息摘要”。
--------------------------------
原来hash是一个短的key值,来代替原有的对象,这样查询的效率就会高非常多的倍数。
也可以用在通信方面,比如两个系统有相同的hash函数,这样就不需要传递大的对象,只需要传递hash值给对方,然后,对方在根据hash函数本地计算出对象。
觉得很棒。
--------------------------------
哈希算法存取之所以快,是因为其 直接通过关键字key得到要存取的记录内存存储位置
试想这样的场景,你很想学太极拳,听说学校有个叫张三丰的人打得特别好,于是你到学校学生处找人,学生处的工作人员可能会拿出学生名单,一个一个的查找,最终告诉你,学校没这个人,并说张三丰几百年前就已经在武当山作古了。可如果你找对了人,比如在操场上找那些爱运动的同学,人家会告诉你,"哦,你找张三丰呀,有有有,我带你去。于是他把你带到了体育馆内,并告诉你,那个教大家打太极的小伙子就是张三丰\',原来"张三丰.是因为他太极拳打得好而得到的外号。学生处的老师找张三丰,那就是顺序表查找,依赖的是姓名关键字的比较。而通过爱好运动的同学询问时,没有遍历,没有比较,就凭他们"欲找太极\'张三丰\',必在体育馆当中"的经验,直接告诉你位置。
也就是说,我们只需要通过某个函数f,使得
存储位置=f (关键字)
那样我们可以通过查找关键字不需要比较就可获得需要的记录的存储位置。这就是一种新的存储技术一一散列技术(哈希算法)。
散列技术是在记录的存储位置和它的关键字之间建立一个确定的对应关系f,使得每个关键字key 对应一个存储位置f (key)。查找时,根据这个确定的对应关系找到给定值key 的映射f (key) ,若查找集合中存在这个记录,则必定在f (key) 的位置上。
这里我们把这种对应关系f 称为散列函数, 又称为哈希(Hash) 函数。按这个思想,采用散列技术将记录存储在一块连续的存储空间中,这块连续存储空间称为散列表或哈希表(Hash table)。 那么关键字对应的记录存储位置我们称为散列地址。
散列表是个一维数组,是连续的,而散列地址是不连续的
整个散列过程其实就是两步。
(1) 在存储时,通过散列函数计算记录的散列地址,并按此散列地址存储该记录。
(2) 当查找记录时,我们通过同样的散列函数计算记录的散列地址,按此散列地址访问该记录。由于存取用的是同一个散列函数, 因此结果当然也是相同的。
所以说,散列技术既是一种存储方法,也是一种查找方法。然而它与线性表、树、图等结构不同的是,前面几种结构,数据元素之间都存在某种逻辑关系,可以用连线图示表示出来,而散列技术的记录之间不存在什么逻辑关系,它只与关键字有关联。因此,散列主要是面向查找的存储结构。
我们时常会碰到两个关键字key1 != key2,但是却有f(key1) = f(key2),这种现象我们称为哈希冲突,如果没有哈希冲突,散列表是一种非常高效的查找数据结构,其时间复杂度为O(1);
所以说,实际上哈希算法的时间复杂度并没有O(1)
--------------------------------
为什么哈希存取比较快呢,很简单啦,因为有种算法叫做哈希算法,哈希算法会根据你要存入的数据,先通过该算法,计算出一个地址值,这个地址值就是你需要存入到集合当中的数据的位置,而不会像数组那样一个个的进行挨个存储,挨个遍历一遍后面有空位就存这种情况了,而你查找的时候,也是根据这个哈希算法来的,将你的要查找的数据进行计算,得出一个地址,这个地址会印射到集合当中的位置,这样就能够直接到这个位置上去找了,而不需要像数组那样,一个个遍历,一个个对比去寻找,这样自然增加了速度,提高了效率了.
--------------------------------
因为哈希是常数的时间复杂度啊,不管数据量是大还是小,只要用一个固定的算法算出哈希值就能直接找到结果。
--------------------------------
哈希是个人名,也是一个算法的名称。
哈希算法是数据查找技术中最经典的算法之一。
用哈希算法建立索引值,加快查询速度。
--------------------------------
最最简单易懂的说法就是,hash算法将你传入的key运算成一个地址值,类似指针那样,指向内存中的某块区域,存的时候根据该地址值,将value存到这个地址值映射的内存区域里,取得时候从key作hash运算后得出的地址值所对应的内存区域中取出结果;
--------------------------------
自己的理解:哈希一般是基于数组的,只要知道数组的下表,就可以很快的存取该元素。
通过对元素的一个关键字,在通过一个函数,把这个关键字转换成数组的下标,这个函数就是哈希函数。
这样,就能通过关键字很快的存取元素。
有时候会发生冲突现象,即不同的关键字,通过哈希函数算出的结果是一样的,这时候就可以用线性探测或者连地址法等来解决。
在使用哈希的时候,要考虑你存的数据个数的大小,然后再确定数组的大小,一般数组的大小是数据个数的两倍(好像)。具体为什么就不是特别清楚了。。。。
--------------------------------
你好,哈希存储基于一种映射关系的存储,实现这种映射关系的是哈希函数H(key)(这个函数按一定的标准可以自己设定),由节点的关键码key值决定节点的存储地址,然后直接由key值存储或查找数据,查找数据的时间复杂度为O(1)。所以查找的速度非常飞,毕竟时间复杂度为O(n),顺序存储查找的时间复杂度为O(n)。
--------------------------------
参考CSDN博客
以上是关于哈希是什么?为什么哈希存取比较快?的主要内容,如果未能解决你的问题,请参考以下文章