哈希函数和哈希表综述 (转)
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了哈希函数和哈希表综述 (转)相关的知识,希望对你有一定的参考价值。
哈希表及哈希函数研究综述
摘要
随着信息化水平的不断提高,数据已经取代计算成为了信息计算的中心,对存储的需求不断提高信息量呈现爆炸式增长趋势,存储已经成为急需提高的瓶颈。哈希表作为海量信息存储的有效方式,本文详细介绍了哈希表的设计、冲突解决方案以及动态哈希表。另外针对哈希函数在相似性匹配、图片检索、分布式缓存和密码学等领域的应用做了简短得介绍
哈希经过这么多年的发展,出现了大量高性能的哈希函数和哈希表。本文通过介绍各种不同的哈希函数的设计原理以及不同的哈希表实现,旨在帮助读者在实际应用中,根据问题的特点和性能要求选择最适合的哈希算法,设计最优的解决方案。
关键字:哈希函数;哈希表;存储;密码学;分布式缓存。
1.哈希表
1.1哈希表
哈希表(hash table)是哈希函数最主要的应用。哈希表是实现关联数组(associative array)的一种数据结构,广泛应用于实现数据的快速查找。用哈希函数计算关键字的哈希值(hash value),通过哈希值这个索引就可以找到关键字的存储位置,即桶(bucket)。哈希表不同于二叉树、栈、序列的数据结构一般情况下,在哈希表上的插入、查找、删除等操作的时间复杂度是O(1)。
哈希表T,有m个桶,存放着n个元素,那么T的装载因子(load factor)等于n/m,是评价一个哈希表的重要参数。
哈希表是典型的时间和空间的折衷。如果存储空间是无限的,那么可以把关键字key作为存储地址,存取时间为。相反,如果对存取时间没有限制,那么在使用最小的存储空间的情况下,进行顺序查找。而哈希表是在利用尽量少的存储的同时,实现O(1)时间复杂度的查找[1]。
1.2冲突
由于|U|>m,根据鸽巢原理[2]和生日悖论[3],必然存在不同的关键字的哈希值相同,即冲突(collision).设计哈希表时,一方面通过选择最合适的哈希函数的哈希函数尽量减少冲突的次数(在下面会详细介绍),另一方面,根据实际应用的特点设计冲突解决方法[4]。主要有两种方法解决冲突。
链接法[1][4][11]
对于每一个桶sS,用第二层的数据结构实现,根据实际的应用需要可以选择数组、链表、栈、树等,对于所有的xX并且h(x)=s,都存储在桶s中。如果|S|足够大,并且哈希函数均匀性比较好,使得每个桶中的元素不会超过3个,这样,第二层数据机构可以用简单的链表实现。
开放寻址法[1][4][11]
当h(x)已有其他元素时,依次计算探查序列h(x),h(x),h(x),...直到我们找到一个空的桶。不需要链表,不需要动态内存分配,空间利用率高,但是不支持删除,或者需要复杂的机制才能实现删除。有三种技术来计算探查序列:线性探查(linear probing)、二次探查(quadratic probing)、双重散列(double hashing)。相对于双重散列,线性探查和二次探查的性能依赖于关键字的分布和哈希函数的性能[8]。对于一般应用,双重散列的性能会好一些[9]。
删除操作对开放寻址法比较麻烦。有两种处理方法:1)设置标记法;2)重新插入后边的键值对,直到遇到null。
开放寻址法与拉链法的比较
(1) 线性探查和二次探查存在群集(cluster)现象,平均查找长度较长,拉链法处理冲突简单,且无群集现象,因此平均查找长度较短。
(2) 由于拉链法中各个链表上的结点空间是动态分配的,因此它更适合于建表前无法确定哈希表长的应用。
(3) 开放定址法为了保持较好的性能,一般装载因子α较小,故当结点规模较大时会浪费空间。而拉链法中可取α≥1,当结点较大时,增加的指针域可忽略不计,同时,随着α的增大,开放寻址法性能下降比较严重,而链接法相对而言比较缓和[11]。因此链接法更适合于规模比较大的应用。
(4) 拉链法指针需要额外的空间,故当结点规模较小时,开放定址法较为节省空间,而若将节省的指针空间用来扩大散列表的规模,可使装填因子变小,这又减少了开放定址法中的冲突,从而提高平均查找速度。
(5) 开放寻址法中,整个哈希表在连续的空间内,对于规模比较小的应用,开放寻址法(特别是线性探查)具有比较好的缓存性能。
(6) 在用拉链法构造的散列表中,如果链表是双向链表,那么删除一个节点可以在O(1)时间内完成。而对开放地址法构造的散列表,删除结点不能简单地将被删结点的空间置为空,在用开放地址法处理冲突的散列表上执行删除操作,只能在被删结点上做删除标记,而不能真正删除结点[1][4]。
尽管哈希表有很多种不同的实现,但是它们的原理本质上是相同的:哈希表有两级逻辑结构,哈希值是第二级逻辑结构的的入口。哈希函数性能比较好的情况下,第二级逻辑结构的大小是O(1)的,因此整个查找时间也是O(1)的。拉链法的第二级逻辑结构是桶对应的链表,探查序列可以看成是开放寻址法的第二级逻辑结构。
Coalesced hashing[12]
结合了开放寻址法和拉链法,相对于开放寻址法,它的优点是它不会产生一次聚集和二次聚集现象。另外由于它的局部性特征,缓存性能比较好。当负载因子比较大时,它人能保持比较好的性能。当然与开放寻址一样,删除操作费用比较大。
Cuckoo hashing[13]
主要原理是排他性的插入,当发生冲突时,原先桶中的元素被挤出,重新把这个元素插入到表中的其他位置。它的主要优点是在任何情况下,它的查找时间是O(1)。缺点是,当表中元素比较多时,每插入一个新的元素,会发生大量的插入操作。有可能存在环,这种情况下,只能进行哈希表的重构。
Hopscotch hashing[14]
它的原理是,但发生冲突时,新的元素插入到原始桶的邻居桶中,也就是说它与原始桶的距离不会大于一个常数,这样的好处是,任何情况下,查找时间都是O(1),另外,当表接近于饱和时,即α趋向于1时,仍然保持较好的性能。缺点是,每插入一个元素,有可能导致表中大量元素的移动,另外实现起来比较复杂。
Robin Hood hashing[15]
对于的元素x,应该存储的位置是h(x),实际存储的位置是h(x)。h(x)=h(x)-h(x),即两个位置之间的距离,也就是查找长度。当插入x时,如果发生冲突,假设y存储在h(x)中,此时h(y)=h(x)。当h(x)<h(y),探测下一个位置,当h(x)>h(y),那么x将挤出,y作为新的元素进行同样的插入操作。当元素插入完成后,所有的h趋向于一个常数,也就是查找长度是O(1)。与Hopscotch hashing相似,当α比较大时,一个新的元素的插入都会引起表中大量元素的移动和重新插入。
2-choice hashing
两个哈希函数h1和h2,以及它们对应的两个链接法实现的哈希表。当插入x时,计算h1(x)和h2(x),将x插入到含元素少的桶中。查找时需要分别遍历h1(x)和h2(x)
1.3动态哈希表[16][21]
以上介绍的解决冲突的方法,存在一个前提:哈希表的桶的数目保持不变,即哈希表在初始化时指定一个参数,以后在使用的过程中,只允许在其中添加、删除、查找元素等操作,而不允许改变桶的数目。
在实际的应用中,当哈希表较小,元素个数不多时,采用以上方法完全可以应付。但是,一旦元素较多,或数据存在一定的偏斜性(数据集中分布在某个桶上)时,以上方法不足以解决这一问题。另一方面,随着元素的插入和删除,为了让装载因子α维持在一定的范围内,使哈希表有良好的时间和空间性能,需要不断地调整哈希表的大小。我们引入一种称之为动态散列的方法:在哈希表的元素增长的同时,动态的调整桶的数目。动态散列不需要对哈希表中所有元素进行再次插入操作(重组),而是在原来基础上,进行动态的桶扩展。
Linear hashing[17][18]
Linear hashing依次循环分裂所有的桶,S指向要分裂的桶,当某一个桶溢出时,分裂S桶,S指向下一个桶。S逐渐指向溢出桶,将溢出桶分裂。需要注意的时,每次发生分裂的桶总是由S决定,与当前值被插入的桶已满或溢出无关。为处理溢出情况,可引入溢出页解决哈希函数比较简单:
hi(x) = x mod 2i , i=1,2,3,4,….
随着哈希表不断增大,i不断增大。在删除元素后,如果发现桶为空,可以将它与相邻的桶合并。Berkeley DB 用的就是Liner hashing。
Extendible hashing[16][19][20]
是应用字典树(trie)进行桶查找,引入一个包含桶指针的目录数组,当某个桶发生溢出时,将这个桶分裂,目录数组加倍,同时调整各个桶指针。Extendible hashing的好处在于实现桶的动态增长,且增长的同时,用目录项翻倍的较小的代价取代桶数翻倍的传统做法,效率得到提升。当然,它也存在一定问题:当散列的数据分布不均或偏斜较大时,即大量哈希值有相同的前缀,会使得目录项的数目很大,绝大多数的桶指针指向同一个桶,空间利用率很低;目录数组是指数级增长,随着元素的增长,目录数组占用的空间非常大。
动态散列通过桶的分裂或合并来适应哈希表大小的变化。这样保持空间的使用效率,所带来的性能开销较低[20]。只有少量元素所在的桶发生变化,也就是哈希表的结构局部性变化,减少了重构哈希表带来的时延,同时,每个桶中元素的数量较少。
1.4分布式哈希表
如果把数据全部存储在一台机器上,如果这台机器发生故障,会造成数据丢失,此外,如果有大量的请求访问,也会造成延迟。因此引入了分布式哈希表(distributed hash table),它数据分散存储在多个节点,每个节点只存储一部分数据,实现整个系统的存储,常应用于P2P网络中。比较常见的四种协议有Chord[22],CAN(Content Addressable Network)[23],Pastry[24][25]和Tapestry[26]。分布式哈希表应该具有可扩展性(scalable)、容错性(fault tolerant)和自组织性(self-organizing)等特点。分布式哈希表一般是基于一致性哈希(consistent hashing)实现的,consistent hashing 最开始是在网络缓存中提出的,在下面关于缓存的部分会详细介绍。
2.哈希函数
2.1定义
哈希函数h(hash function)是一种映射关系,它可以把任意长度的输入映射到任意一个固定长度的整数值,也称为散列函数。
h:U->{0,1,…,m-1}
这里,U关键字所有可能取值的集合,称为全域(universe),设哈希值的全集{0,1,…,m-1}用S表示。把关键字看成是0、1串,也就是二进制表示。散列(hash)英文原意是“混杂”、“拼凑”、“重新表述”。实际上,散列是与排序相反的一种操作,排序是将集合中的元素按照某种方式比如字典顺序排列在一起而散列通过计算哈希值,打破元素之间原有的关系,使集合中的元素尽可能地无序,随机排列。
X是特定应用中关键字取值的集合,X中的关键字很少能在U中均匀分布,为了使所对应的哈希值能在S中均匀分布,哈希函数最好具有雪崩效应(avalanche),也就是说,关键字中每一比特位的改变都能使哈希值大多数比特位发生变化。
哈希函数的性能当然也受计算平台的影响[7]。
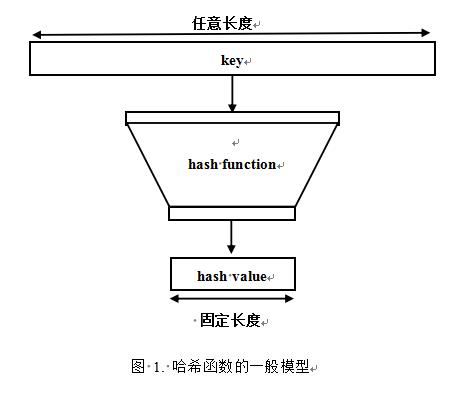
2.2性质
一般而言,理想的哈希函数应该具有以下特性。
1.Calculability[1]。在现有计算能力下,在较短的时间内计算完成。
2.Determinism。相同的输入的多次计算结果相同,也就是说,得到的哈希值于外界条件(例如时间)无关。
3.Universality
4.Uniformity[6]。尽量将关键字key等可能地映射到S中的每一个哈希值,即得到的哈希值在S中均匀分布,值得注意的是,这里均匀分布并不要求随机分布。当然,如果哈希值随机分布的话,必定是随机分布的,但是,均匀分布并不能推导出随机分布。可以用chi-squared test[5]评估哈希函数的均匀分布特性。
5.Independence[1]。将关键字等可能地映射到任意哈希值,与其他关键字已经映射的哈希值无关[4]。
2.3Hashing Methods
简单的构造哈希函数的方法有以下几种
除法散列法
设计哈希函数的比较简单的一种方法是除法散列法(division method),它是取关键字k除以m的余数作为哈希值,即:
h(k)=k mod m.
例如哈希表的大小m=23,当k=45时,h(k)=22。
尽量避免选择m=2,这样的话,h(k)等于k最左边p位所表示的数。但是一个好的哈希函数应该将关键字的每一位都考虑在内。一个接近2的整数幂的素数时比较理想的选择[4]。
乘法散列法[4]
乘法散列法(multiplication method)的定义如下:
h(k)=m(KAmod1)
首先用关键字k乘上常数A(0<A<1),并且取kA的小数部分。然后用m乘以得到的结果,并向下取证。
对m的取值没有特别的要求,为了计算的方便,m常取2的整数次幂,这样乘法操作可以优化为简单的移位操作。
折叠法[35]
折叠法(folding method)是将关键字k分割成位数相同的几部分(最后一部分除外),然后将它们相加(舍去进位)得到哈希值。这种方法适用于k位数较多,并且关键字中每一位上数字分布大致均匀。
平方取中法[35]
平方取中法(middle of square)将关键字k平方,取中间几位作为哈希值。k中的中间几位与k中的每一位都相关,因此,如果k是随机分布的,那么得到的哈希值也是随机分布的。
数字分析法[35]
数字分析法(digit analysis)的思想是这样的:如果哈希表中可可能出现的关键字是知道的,可以去关键字中的某几位作为哈希值。根据实际应用确定要选取的部分,尽量避免发生冲突。
随机数法[35]
选择一个随机函数,把关键字的随机函数值作为它的哈希值。通常当关键字的长度不等时用这种方法。
构造哈希函数的方法很多,实际工作中要根据不同的情况选择合适的方法。通常考虑的因素有关键字的长度和分布情况、哈希值的范围等。如:当关键字是整数类型时就可以用除法散列法和乘法散列法;如果关键字是小数类型,选择随机数法会比较好。
2.4perfect hashing[4][16][39][40]
当所有的关键字是确定的且每个关键字可一一列举时,可以设计完美哈希(perfect hashing)它的特点是没有冲突,即单射函数,比如把十二个月份映射到{0,...11}。
比较常用的是Fredman在1894年提出的[39],下面看一下他是如何设计的[4]。
使用两级的全域散列,在每级上都使用全域散列。第一级与链接法实现的哈希表是一样的,利用从全域哈希函数族H中选择的哈希函数h将n个关键字映射到m个桶中。第二级不是将桶j中的元素链接起来,而是桶j也用哈希表实现。为尽量避免第二级哈希表不发生冲突,让它的大小是桶中元素个数的平方。这看上去会使总的存储空间比较大,但是如果选择恰当的哈希函数,总存储空间可以限制为O(n)。
如果在完美哈希上再加一条限制,所有哈希值落在一段连续的区间内,那么就称为最小完美哈希(minimal perfect hashing)。
动态完美哈希(Dynamic perfect hashing)支持元素从表中删除[40]。
2.5应用
哈希表
哈希表是哈希函数最主要的应用。一个均匀分布的哈希函数对哈希表的性能有非常大的影响,它可以减少冲突发生时带来的系统开销。
分布式缓存
比较传统的应用是,通过哈希函数计算数据的哈希值,利用哈希值来找到缓存区间的地址,当发生冲突时,只需将此地址上原有的数据丢弃即可,实现比较简单。
网络环境下的分布式缓存系统一般基于一致性哈希(Consistent hashing)[27][28]。简单的说,一致性哈希将哈希值取值空间组织成一个虚拟的环,各个服务器与数据关键字K使用相同的哈希函数映射到这个环上,数据会存储在它顺时针“游走”遇到的第一个服务器。可以使每个服务器节点的负载相对均衡,很大程度上避免资源的浪费。
但是如果某个服务器宕机,那么就会使它下一个服务器负载加重。为了解决这个问题,引入了虚拟节点[29],将所有的数据关键字映射到多于服务器数目的一组虚拟节点,然后虚拟节点再映射到真实的服务器。用户数据真正存储在它映射的虚拟节点所对应的物理服务器上。所以当服务器宕机时,虚拟节点的数量固定不变,而只需要将服务不可用的虚拟节点重新迁移,这样只需要迁移宕机节点的数据。最大限度地减小服务器增减时的缓存重新分布。
在动态分布式缓存系统中,哈希算法的设计是关键点。使用分布更合理的算法可以使得多个服务节点间的负载相对均衡,可以很大程度上避免资源的浪费以及部分服务器过载。 使用带虚拟节点的一致性哈希算法,可以有效地降低服务硬件环境变化带来的数据迁移代价和风险,从而使分布式缓存系统更加高效稳定。
Bloom filters[30][31][32]
它的作用是判断一个元素是否属于一个集合,这个集合用一个位数组表示。相对于其他表示集合的数据结构,Bloom filter 最大的优点是占用空间少,这对海量数据的处理至关重要,另外,判断向集合添加一个元素或判断一个元素是否属于这个集合的时间是O(1),与集合中已存在的元素个数无关。当然,它也存在一个很明显的缺点,可能吧不存在的元素误认为存在集合中(false positive)。因此,Bloom filter不适合那些“零错误”的应用。
下面看一下Bloom filter的实现。初始状态时,Bloom Filter是一个m位的位数组,每一位都置为0。假设当前集合S={x, x,…,x},Bloom Filter使用k个相互独立的哈希函数(Hash Function),它们分别将集合中的每个元素映射到{1,…,m}的范围中。对任意一个元素x,第i个哈希函数映射的位置h(x)(1≤h(x)≤m)就会被置为1(1≤i≤k)。注意,如果一个位置多次被置为1,那么只有第一次会起作用,后面几次将没有任何效果。判断x是否在集合中,分别计算x的k个哈希值,假设k=4,如果所有h(x)的位置都是1(1≤i≤k),那么就认为x是集合中的元素(可能实际上x不在集合中),否则就认为x不在集合中。
传统的Bloom filter 不支持从集合中删除元素。为了解决这个问题,引入了Counting Bloom filter[33][34]。它将Bloom filter位数组的每一位扩展为一个小的计数器,在插入元素时,将哈希值对应的k(k为哈希函数个数)个计算器的值加1,删除元素时给对应的k个计数器的值减1。
删除重复数据
可以利用哈希函数删除集合中的重复元素。用哈希函数计算所有元素的哈希值,将这些元素存放在一个哈希表T中。一组重复的元素必定在同一个桶T[i]中,然后分别在每一个桶中比较,去除重复的元素。用这种方法去除重复元素要比其他的方法效率高很多。
加密哈希函数
在密码学和数据安全技术中,哈希函数是实现有效、安全可靠数字签名和认证的重要工具,是安全认证协议中的重要模块 。相对于其他哈希函数,因为安全方面的考虑,加密哈希函数(cryptographic hash function)性能上有更高的要求[41]:
单向性:对于任意给定的哈希值h。找到一个k使得h(k)=h在计算上是不可行的。
抗弱碰撞性:对任意给定的x,找到满足xy且h(x)=h(y)的y在计算是不可行的。
抗强碰撞性:找到任意一对满足h(y)=h(x)的元素(x,y)在计算上是不可行的。
现在常用的加密哈希函数比如MD5、SHA-1都是基于分块加密(block cipher)的。2005年,我国王小云教授提出找到SHA-1的碰撞由理论上的2^80将为2^69[42]。2012年10月,美国NIST选择了Keccak算法作为SHA - 3的标准算法,Keccak拥有更好的加密性能以及抗解密能力。
局部敏感哈希[43]
局部有敏感哈希(locality sensitive hashing,LSH)的基本思想是:将原始数据空间中的两个相邻数据点通过相同的映射或投影变换(projection)后,这两个数据点在新的数据空间中仍然相邻的概率很大,而不相邻的数据点被映射到同一个桶的概率很小。LSH与其他有雪崩要求的哈希函数截然相反。比较常见的局部敏感哈希有MinHash[43]、Nilsimsa Hash[44]和SimHash[45]。
LSH的应用范围很广,凡是在大量数据之间进行相似性查找都可使用LSH,比如查找重复网页、查找相似的文章、图像检索、音乐检索、指纹匹配等。
LSH为我们提供了一种在海量的高维数据集中查找与查询数据点(query data point)近似最相邻的某个或某些数据点。需要注意的是,LSH并不能保证一定能够查找到与查询数据点最相邻的数据,而是减少需要匹配的数据点个数的同时保证查找到最近邻的数据点的概率很大。
数据库索引[46]
散列索引是数据库中一种常见的索引方式,相对于BTree索引,它查找速度比较快,常用作辅助索引。
2.5常用的哈希函数
Person hashing
Siphash
One at a time
Lookup3
MurmurHash
CityHash
FarmHash
xxhash
FNV1a
MD5
MD4
SHA-1
SHA-3
CRC32
SpookyHash
总结
没有万能的哈希表及哈希函数,每个哈希表及哈希函数都有它最适合的应用场景。掌握各种哈希算法,了解它们的优缺点。在遇到问题时,分析数据特点及性能要求,选择或设计出最合适的哈希表及哈希函数。
参考:
[1] Robert Sedgewick.Algorithms in C.
[2] Herstein, I. N. Topics In Algebra[M].Waltham: Blaisdell Publishing Company,1964:90
[3] W. W. Rouse Ball.Mathematical Recreations and Essays[M]. New York: Macmillan,1960:45.
[4] Thomas H. Coremen, Charles E. Leiserson,Ronald L. Stein. Introduction to Algorithms[M],
[5] Pearson, Karl. On the criterion that a given system of deviations from the probable in the case of a correlated system of variables is such that it can be reasonably supposed to have arisen from random sampling[J]. Philosophical Magazine 1900,Series 5 50 (302): 157–175
[6] Mahima Singh,Deepak Garg.Choosing Best Hashing Strategies and Hash Functions.
[7] Fast Hashing on the Pentium
[8] On the k-independence required by linear probing and minwise independence
[9] How Caching Affects Hashing
[10]A Probabilistic Study on Combinatorial Expanders and Hashing
[11]The art of programming.
[12] J. S. Vitter and W.-C. Chen, Design and Analysis of Coalesced Hashing, Oxford University Press, New York, NY, 1987, ISBN 0-19-504182-8
[13]Pagh, Rasmus; Rodler, Flemming Friche (2001). "Cuckoo Hashing". Algorithms — ESA 2001. Lecture Notes in Computer Science 2161. pp. 121–133
[14] Herlihy, Maurice and Shavit, Nir and Tzafrir, Moran (2008). "DISC ‘08: Proceedings of the 22nd international symposium on Distributed Computing". Arcachon, France: Springer-Verlag. pp. 350–364
[15]Celis, Pedro (1986). Robin Hood hashing (Technical report). Computer Science Department, University of Waterloo. CS-86-14.
[16]Advanced Data Structures
[17]Litwin, Witold (1980), "Linear hashing: A new tool for file and table addressing" (PDF), Proc. 6th Conference on Very Large Databases: 212–223
[18]Larson, Per-Åke (April 1988), "Dynamic Hash Tables", Communications of the ACM 31 (4): 446–457, doi:10.1145/42404.42410
[19]Fagin, R.; Nievergelt, J.; Pippenger, N.; Strong, H. R. (September 1979), "Extendible Hashing - A Fast Access Method for Dynamic Files", ACM Transactions on Database Systems 4 (3): 315–344, doi:10.1145/320083.320092
[20]Database System Concepts.
[21]Dynamic Hashing Schemes
[22] Stoica, I.; Morris, R.; Karger, D.; Kaashoek, M. F.; Balakrishnan, H. (2001). "Chord: A scalable peer-to-peer lookup service for internet applications". ACM SIGCOMM Computer Communication Review 31 (4): 149. doi:10.1145/964723.383071
[23]Ratnasamy et al. (2001). "A Scalable Content-Addressable Network". In Proceedings of ACM SIGCOMM 2001. Retrieved 2013-05-20
[24]A. Rowstron and P. Druschel (Nov 2001). "Pastry: Scalable, decentralized object location and routing for large-scale peer-to-peer systems". IFIP/ACM International Conference on Distributed Systems Platforms (Middleware), Heidelberg, Germany: 329–350.
[25]A. Rowstron, A-M. Kermarrec, M. Castro and P. Druschel (Nov 2001). "SCRIBE: The design of a large-scale event notification infrastructure". NGC2001 UCL London.
[26]Zhao, Ben Y.; Huang, Ling; Stribling, Jeremy; Rhea, Sean C.; Joseph, Anthony D.; Kubiatowicz, John D. (2004). "Tapestry: A Resilient Global-scale Overlay for Service Deployment". IEEE Journal on Selected Areas in Communications (IEEE) 22 (1): 41–53. doi:10.1109/JSAC.2003.818784.
[27]Karger, D.; Lehman, E.; Leighton, T.; Panigrahy, R.; Levine, M.; Lewin, D. (1997). "Consistent Hashing and Random Trees: Distributed Caching Protocols for Relieving Hot Spots on the World Wide Web". Proceedings of the Twenty-ninth Annual ACM Symposium on Theory of Computing. ACM Press New York, NY, USA. pp. 654–663. doi:10.1145/258533.258660.
[28]Karger, D.; Sherman, A.; Berkheimer, A.; Bogstad, B.; Dhanidina, R.; Iwamoto, K.; Kim, B.; Matkins, L.; Yerushalmi, Y. (1999). "Web Caching with Consistent Hashing". Computer Networks 31 (11): 1203–1213. doi:10.1016/S1389-1286(99)00055-9
[29]Dynamo: Amazon’s Highly Available Key-value Store
[30]Bloom, Burton H. (1970), "Space/Time Trade-offs in Hash Coding with Allowable Errors", Communications of the ACM 13 (7): 422–426,
[31]Broder, Andrei; Mitzenmacher, Michael (2005), "Network Applications of Bloom Filters: A Survey", Internet Mathematics 1 (4): 485–509,
[32]M. Mitzenmacher. Compressed Bloom Filters. IEEE/ACM Transactions on Networking 10:5 (2002), 604—612.
[33]Kirsch, Adam; Mitzenmacher, Michael (2006), "Less Hashing, Same Performance: Building a Better Bloom Filter", in Azar, Yossi; Erlebach, Thomas, Algorithms – ESA 2006, 14th Annual European Symposium, Lecture Notes in Computer Science 4168, Springer-Verlag, Lecture Notes in Computer Science 4168, pp. 456–467
[34]Rottenstreich, Ori; Kanizo, Yossi; Keslassy, Isaac (2012), "The Variable-Increment Counting Bloom Filter", 31st Annual IEEE International Conference on Computer Communications, 2012, Infocom 2012, pp. 1880–1888,
[35]严蔚敏 数据结构
[36]Carter, Larry; Wegman, Mark N. (1979). "Universal Classes of Hash Functions". Journal of Computer and System Sciences 18 (2): 143–154. doi:10.1016/0022-0000(79)90044-8. Conference version in STOC‘77
[37]Miltersen, Peter Bro. "Universal Hashing" (PDF). Archived from the original on 24 June 2009.
[38]Kaser, Owen; Lemire, Daniel (2013). "Strongly universal string hashing is fast". Computer Journal (Oxford University Press). arXiv:1202.4961. doi:10.1093/comjnl/bxt070.
[39]Fredman, M. L., Komlós, J., and Szemerédi, E. 1984. Storing a Sparse Table with 0(1) Worst Case Access Time. J. ACM 31, 3 (Jun. 1984), 538-544
[40]Dietzfelbinger, M., Karlin, A., Mehlhorn, K., Meyer auf der Heide, F., Rohnert, H., and Tarjan, R. E. 1994. Dynamic Perfect Hashing: Upper and Lower Bounds. SIAM J. Comput. 23, 4 (Aug. 1994), 738-761.
[41]Cryptography and Network Security Principles and Practice, 5th Edition
[42]Xiaoyun Wang, Yiqun Lisa Yin, and Hongbo Yu, Finding Collisions in the Full SHA-1
[43]A. Rajaraman and J. Ullman (2010). "Mining of Massive Datasets
[44]Damiani et. al (2004). "An Open Digest-based Technique for Spam Detection"
[45] Charikar, Moses S.. (2002). "Similarity Estimation Techniques from Rounding Algorithms". Proceedings of the 34th Annual ACM Symposium on Theory of Computing 2002: (ACM 1–58113–495–9/02/0005)….
[46]Database.System.Concepts.6th Edition
http://www.cnblogs.com/qiaoshanzi/p/5295554.html
以上是关于哈希函数和哈希表综述 (转)的主要内容,如果未能解决你的问题,请参考以下文章