Spark Standalone如何通过start-all.sh启动集群
Posted 一路向前走
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark Standalone如何通过start-all.sh启动集群相关的知识,希望对你有一定的参考价值。
1.start-all.sh脚本分析
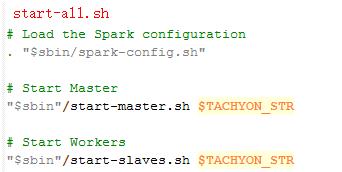
图1 start-all.sh部分内容
我们可以从start-all.sh脚本源文件中看到它其实是start-master.sh和start-slaves.sh两个脚本的组合。
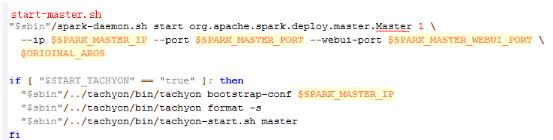
图2 start-master.sh部分内容
由图2可见,start-master.sh最终是通过类org.apache.spark.deploy.master.Master来完成的,待会儿我们分析.
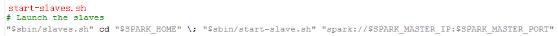
图3 start-slaves.sh部分内容
由图3可见,start-slaves.sh是由slaves.sh和start-slave.sh来组成的。
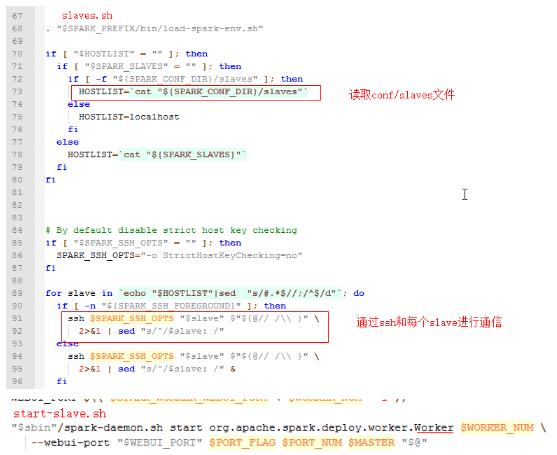
图4 slaves.sh和start-slave.sh部分内容
由图4可见,可以看到slave节点是由org.apache.spark.deploy.worker.Worker类来完成的,master和slave的start都是由spark-daemon.sh脚本来运行的
2.具体执行类分析
脚本最后的执行者其实是类。我们具体看一下Master、Worker的执行过程。
2.1 Master节点启动分析
Master.scala文件由一个Master类和其伴生对象组成。
从main函数开始,主要启动Rpc环境,目前Spark中提供了两种Rpc环境:Akka和Netty
def main(argStrings: Array[String]) {
SignalLogger.register(log)
val conf = new SparkConf
//命令转换器,将通过脚本传递过来的参数转化为类Master的变量
val args = new MasterArguments(argStrings, conf)
//启动master并返回一个三元组:(1)Master Rpc环境(2)web UI绑定的端口号(3)REST server绑定的端口号
val (rpcEnv, _, _) = startRpcEnvAndEndpoint(args.host, args.port, args.webUiPort, conf)
//等待直到RpcEnv退出
rpcEnv.awaitTermination()
}
(1)master参数主要是通过MasterArguments类来完成的,如下所示,由代码可见master默认的端口是7070,web端口是8080
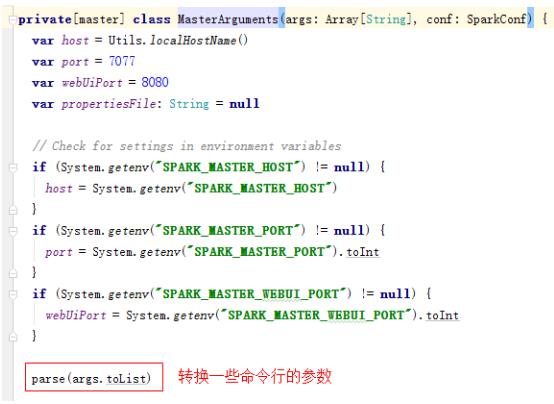
图5 Master转换类
(2)通过startRpcEnvAndEndpoint方法实现启动Master并返回三元组,由Master RpcEnv、绑定的web UI端口号和REST server绑定的端口号
def startRpcEnvAndEndpoint(
host: String,
port: Int,
webUiPort: Int,
conf: SparkConf): (RpcEnv, Int, Option[Int]) = {
val securityMgr = new SecurityManager(conf)
//通过RpcEnvFactory生成RpcEnv,这里默认使用的是NettyRpcEnvFactory
val rpcEnv = RpcEnv.create(SYSTEM_NAME, host, port, conf, securityMgr)
//返回一个Master的远程调用masterEndpoint
val masterEndpoint = rpcEnv.setupEndpoint(ENDPOINT_NAME,
new Master(rpcEnv, rpcEnv.address, webUiPort, securityMgr, conf))
//绑定端口的请求
val portsResponse = masterEndpoint.askWithRetry[BoundPortsResponse](BoundPortsRequest)
(rpcEnv, portsResponse.webUIPort, portsResponse.restPort)
}
2.2 Worker节点启动分析
Worker节点的启动和Master的很类似,如下所示:
def main(argStrings: Array[String]) {
SignalLogger.register(log)
val conf = new SparkConf
//命令转换器,将通过脚本传递过来的参数转化为类Worker的变量
val args = new WorkerArguments(argStrings, conf)
//启动Worker Rpc环境
val rpcEnv = startRpcEnvAndEndpoint(args.host, args.port, args.webUiPort, args.cores,
args.memory, args.masters, args.workDir)
//等待直到RpcEnv退出
rpcEnv.awaitTermination()
}
(1)启动Worker Rpc环境如下所示
def startRpcEnvAndEndpoint(
host: String,
port: Int,
webUiPort: Int,
cores: Int,
memory: Int,
masterUrls: Array[String],
workDir: String,
workerNumber: Option[Int] = None,
conf: SparkConf = new SparkConf): RpcEnv = {
// The LocalSparkCluster runs multiple local sparkWorkerX RPC Environments
//LocalSparkCluster启动多个本地的sparkWorker RPC环境,系统名为sparkWorker1,sparkWorker2.。。
val systemName = SYSTEM_NAME + workerNumber.map(_.toString).getOrElse("")
val securityMgr = new SecurityManager(conf)
//通过RpcEnvFactory生成RpcEnv,这里默认使用的是NettyRpcEnvFactory
val rpcEnv = RpcEnv.create(systemName, host, port, conf, securityMgr)
//从RpcAddress得到master的地址,即从spark://host:port解析得到host和port封装到RpcAddress
val masterAddresses = masterUrls.map(RpcAddress.fromSparkURL(_))
//返回一个Worker的远程调用
rpcEnv.setupEndpoint(ENDPOINT_NAME, new Worker(rpcEnv, webUiPort, cores, memory,
masterAddresses, systemName, ENDPOINT_NAME, workDir, conf, securityMgr))
rpcEnv
}
下一篇我们继续了解Spark Rpc,了解Master、Worker和Client是如何通信的。
以上是关于Spark Standalone如何通过start-all.sh启动集群的主要内容,如果未能解决你的问题,请参考以下文章