怎样检测有没有使用tcmalloc
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了怎样检测有没有使用tcmalloc相关的知识,希望对你有一定的参考价值。
参考技术A可以对任何链接了tcmalloc的程序进行堆栈检查,并且不需要重新编译。
为了抓住所有的内存泄漏,tcmalloc必须被链接到你的可执行程序中。堆栈检查器可能误解列在它后面的链接库的一些内存。例如,它可能把这些库的内存误报为内存泄漏,而实际上并没有。
把tcmalloc链接到你的程序,即时你不想使用堆栈检查器来检查也是安全的。你的程序并不会运行的有任何一点缓慢,因为你没有用到任何一点堆栈检查的特性。
可以通过LD_PRELOAD在那些不是你编译的程序中运行堆栈检查。
tcmalloc源码分析
tcmalloc源码分析
- 说明
- 介绍
- 1)如何使用TCMalloc
- 2)TCMalloc是如何生效的
- 3)TCMalloc是什么
- 4)TCMalloc的初始化
- 5)TCMalloc的内存分配算法概览
- 6)TCMalloc的实现细节
- 7)一些图
说明
从TCMalloc解密处转载,方便日后复习
其他摘自参考文章:
TCMalloc源码阅读(二)–线程局部缓存ClassSize分析
tcmalloc源码阅读(三)—ThreadCache分析之线程局部缓存
TCMalloc内存分配器如何减少内存碎片?
tcmalloc内存分配器分析笔记:基于gperftools-2.4
介绍
TCMalloc全称Thread-Caching Malloc,即线程缓存的malloc,实现了高效的多线程内存管理,用于替代系统的内存分配相关的函数(malloc、free,new,new[]等)
TCMalloc是gperftools的一部分,除TCMalloc外,gperftools还包括heap-checker、heap-profiler和cpu-profiler。本文只讨论gperftools的TCMalloc部分
git仓库
官方介绍(里面有些内容已经过时了)
1)如何使用TCMalloc
安装
以下是比较常规的安装步骤,详细可参考gperftools中的INSTALL
从git仓库clone版本的gperftools的安装依赖autoconf、automake、libtool,以Debian为例# apt install autoconf automake libtool
- 生成configure等一系列文件
$ ./autogen.sh
- 生成Makefile
$ ./configure
- 编译
$ make
- 安装
# make install默认安装在/usr/local/下的相关路径(bin、lib、share),可在configure时以–prefix=PATH指定其他路径
64位Linux系统需要注意
- 在64位Linux环境下,gperftools使用glibc内置的stack-unwinder可能会引发死锁,因此官方推荐在配置和安装gperftools之前,先安装libunwind-0.99-beta,最好就用这个版本,版本太新或太旧都可能会有问题。
- 即便使用libunwind,在64位系统上还是会有问题,但只影响heap-checker、heap-profiler和cpu-profiler,TCMalloc不受影响,因此不再赘述,感兴趣的读者可参阅gperftools的INSTALL。
- 如果不希望安装libunwind,也可以用gperftools内置的stack unwinder,但需要应用程序、TCMalloc库、系统库(比如libc)在编译时开启帧指针(frame pointer)选项。
- 在x86-64下,编译时开启帧指针选项并不是默认行为。因此需要指定-fno-omit-frame-pointer编译所有应用程序,然后在configure时通过–enable-frame-pointers选项使用内置的gperftools stack unwinder
使用
以动态库的方式
以动态库的方式
- 安装之后,通过-ltcmalloc或-ltcmalloc_minimal将TCMalloc链接到应用程序即可
#include <stdlib.h> int main( int argc, char *argv[] ) malloc(1);$ g++ -O0 -g -ltcmalloc test.cc && gdb a.out(gdb) b test.cc:5 Breakpoint 1 at 0x7af: file test.cc, line 5. (gdb) r Starting program: /home/wanglong/test/tcmalloc/a.out [Thread debugging using libthread_db enabled] Using host libthread_db library "/lib/x86_64-linux-gnu/libthread_db.so.1". Breakpoint 1, main (argc=1, argv=0x7fffffffddd8) at test.cc:5 5 malloc(1); (gdb) s tc_malloc (size=1) at src/tcmalloc.cc:1892 1892 return malloc_fast_path<tcmalloc::malloc_oom>(size); (gdb)通过gdb断点可以看到对malloc()的调用已经替换为TCMalloc的实现
以静态库的方式
以静态库的方式
- gperftools的README中说静态库应该使用libtcmalloc_and_profiler.a库而不是libprofiler.a和libtcmalloc.a,但简单测试后者也是OK的,而且在实际项目中也是用的后者,不知道是不是文档太过老旧了
$ g++ -O0 -g -pthread test.cc /usr/local/lib/libtcmalloc_and_profiler.a如果使用了libunwind,需要指定-Wl,–eh-frame-hdr选项,以确保libunwind可以找到编译器生成的信息来进行栈回溯。
eh-frame(exception handling frame)参考资料:
2)TCMalloc是如何生效的
为什么指定-ltcmalloc或者与libtcmalloc_and_profiler.a连接之后,对malloc、free、new、delete等的调用就由默认的libc中的函数调用变为TCMalloc中相应的函数调用了呢?答案在libc_override.h中,下面只讨论常见的两种情况:使用了glibc,或者使用了GCC编译器。其余情况可自行查看相应的libc_override头文件
使用glibc(但没有使用GCC编译器)
在glibc中,内存分配相关的函数都是弱符号weak symbol,因此TCMalloc只需要定义自己的函数将其覆盖即可,以malloc和free为例:
libc_override_redefine.hextern "C" void* malloc(size_t s) return tc_malloc(s); void free(void* p) tc_free(p); // extern "C"可以看到,TCMalloc将malloc()和free()分别定义为对tc_malloc()和tc_free()的调用,并在tc_malloc()和tc_free()中实现具体的内存分配和回收逻辑。
new和delete也类似void* operator new(size_t size) return tc_new(size); void operator delete(void* p) CPP_NOTHROW tc_delete(p);
使用GCC编译器
如果使用了GCC编译器,则使用其支持的函数属性:
alias。
libc_override_gcc_and_weak.h:#define ALIAS(tc_fn) __attribute__ ((alias (#tc_fn), used)) extern "C" void* malloc(size_t size) __THROW ALIAS(tc_malloc); void free(void* ptr) __THROW ALIAS(tc_free); // extern "C"将宏展开,
__attribute__ ((alias ("tc_malloc"), used))表明tc_malloc是malloc的别名。
具体可参阅GCC相关文档:
- alias (“target”)
The alias attribute causes the declaration to be emitted as an alias for another symbol, which must be specified. For instance,
void __f () /* Do something. */;
void f () attribute ((weak, alias (“__f”)));
defines f to be a weak alias for __f. In C++, the mangled name for the target must be used. It is an error if __f is not defined in the same translation unit.
Not all target machines support this attribute.
used
This attribute, attached to a function, means that code must be emitted for the function even if it appears that the function is not referenced. This is useful, for example, when the function is referenced only in inline assembly.
When applied to a member function of a C++ class template, the attribute also means that the function will be instantiated if the class itself is instantiated.
3)TCMalloc是什么
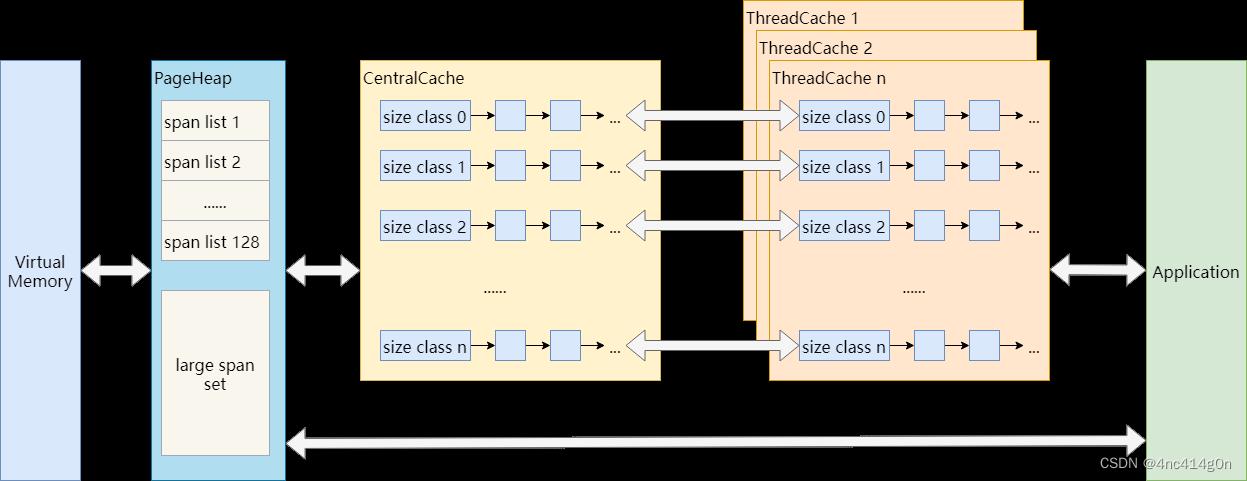
TCMalloc是专门对多线并发的内存管理而设计的,TCMalloc主要是在线程级实现了缓存,使得用户在申请内存时大多情况下是无锁内存分配
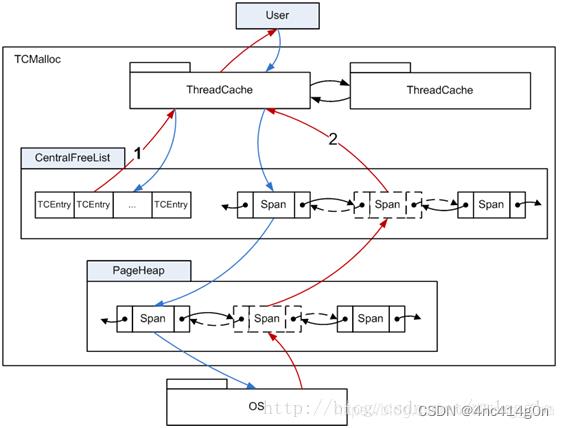
整个 TCMalloc对小内存(小于等于256k)的管理实现了三级缓存,分别是
- ThreadCache(线程级缓存),
- Central Cache(中央缓存:CentralFreeeList),
- PageHeap(页缓存)
小内存的分配和释放流程如下图所示,红线表示内存的申请,蓝线表示内存的释放过程。
4)TCMalloc的初始化
何时初始化
TCMalloc定义了一个类TCMallocGuard,并在文件tcmalloc.cc中定义了该类型的静态变量module_enter_exit_hook,在其构造函数中执行TCMalloc的初始化逻辑,以确保TCMalloc在main()函数之前完成初始化,防止在初始化之前就有多个线程。
tcmalloc.cc:static TCMallocGuard module_enter_exit_hook;如果需要确保TCMalloc在某些全局构造函数运行之前就初始化完成,则需要在文件顶部创建一个静态TCMallocGuard实例。
如何初始化
TCMallocGuard的构造函数实现
static int tcmallocguard_refcount = 0; // no lock needed: runs before main() TCMallocGuard::TCMallocGuard() if (tcmallocguard_refcount++ == 0) ReplaceSystemAlloc(); // defined in libc_override_*.h tc_free(tc_malloc(1)); ThreadCache::InitTSD(); tc_free(tc_malloc(1)); // Either we, or debugallocation.cc, or valgrind will control memory // management. We register our extension if we're the winner. #ifdef TCMALLOC_USING_DEBUGALLOCATION // Let debugallocation register its extension. #else if (RunningOnValgrind()) // Let Valgrind uses its own malloc (so don't register our extension). else MallocExtension::Register(new TCMallocImplementation); #endif可以看到,TCMalloc初始化的方式是调用tc_malloc()申请一字节内存并随后调用tc_free()将其释放。至于为什么在InitTSD前后各申请释放一次,不太清楚,猜测是为了测试在TSD(Thread Specific Data,详见后文)初始化之前也能正常工作
初始化内容
那么TCMalloc在初始化时都执行了哪些操作呢?这里先简单列一下,后续讨论TCMalloc的实现细节时再逐一详细讨论:
- 初始化SizeMap(Size Class)
- 初始化各种Allocator
- 初始化CentralCache
- 创建PageHeap
总之一句话,创建TCMalloc自身的一些元数据,比如划分小对象的大小等等
5)TCMalloc的内存分配算法概览
TCMalloc的官方介绍中将内存分配称为Object Allocation,本文也沿用这种叫法,并将object翻译为对象,可以将其理解为具有一定大小的内存
按照所分配内存的大小,TCMalloc将内存分配分为三类:
- 小对象分配,(0, 256KB]
- 中对象分配,(256KB, 1MB]
- 大对象分配,(1MB, +∞)
简要介绍几个概念,Page,Span,PageHeap:
与操作系统管理内存的方式类似,TCMalloc将整个虚拟内存空间划分为n个同等大小的Page,每个page默认8KB。又将连续的n个page称为一个Span。
TCMalloc定义了PageHeap类来处理向OS申请内存相关的操作,并提供了一层缓存。可以认为,PageHeap就是整个可供应用程序动态分配的内存的抽象。
PageHeap以span为单位向系统申请内存,申请到的span可能只有一个page,也可能包含n个page。可能会被划分为一系列的小对象,供小对象分配使用,也可能当做一整块当做中对象或大对象分配
小对象分配
Size Class
对于256KB以内的小对象分配,TCMalloc按大小划分了85个类别(官方介绍中说是88个左右,但我个人实际测试是85个,不包括0字节大小),称为Size Class,每个size class都对应一个大小,比如8字节,16字节,32字节。应用程序申请内存时,TCMalloc会首先将所申请的内存大小向上取整到size class的大小,比如1~ 8字节之间的内存申请都会分配8字节,9~16字节之间都会分配16字节,以此类推。因此这里会产生内部碎片。TCMalloc将这里的内部碎片控制在12.5%以内,具体的做法在讨论size class的实现细节时再详细分析。
ThreadCache
对于每个线程
- TCMalloc都为其保存了一份单独的缓存,称之为ThreadCache,这也是TCMalloc名字的由来(Thread-Caching Malloc)。每个ThreadCache中对于每个size class都有一个单独的FreeList,缓存了n个还未被应用程序使用的空闲对象。
- 小对象的分配直接从ThreadCache的FreeList中返回一个空闲对象,相应的,小对象的回收也是将其重新放回ThreadCache中对应的FreeList中。
- 由于每线程一个ThreadCache,因此从ThreadCache中取用或回收内存是不需要加锁的,速度很快。
- 为了方便统计数据,各线程的ThreadCache连接成一个双向链表。ThreadCache的结构示大致如下:

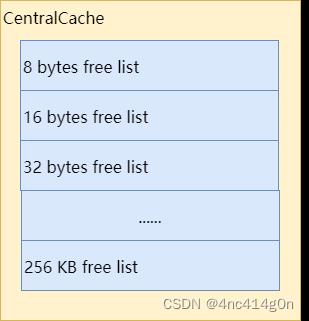
CentralCache
那么ThreadCache中的空闲对象从何而来呢?答案是CentralCache——一个所有线程公用的缓存。
- 与ThreadCache类似,CentralCache中对于每个size class也都有一个单独的链表来缓存空闲对象,称之为CentralFreeList,供各线程的ThreadCache从中取用空闲对象。
- 由于是所有线程公用的,因此从CentralCache中取用或回收对象,是需要加锁的。为了平摊锁操作的开销,ThreadCache一般从CentralCache中一次性取用或回收多个空闲对象。
- CentralCache在TCMalloc中并不是一个类,只是一个逻辑上的概念,其本质是CentralFreeList类型的数组。后文会详细讨论CentralCache的内部结构,现在暂且认为CentralCache的简化结构如下:
PageHeap
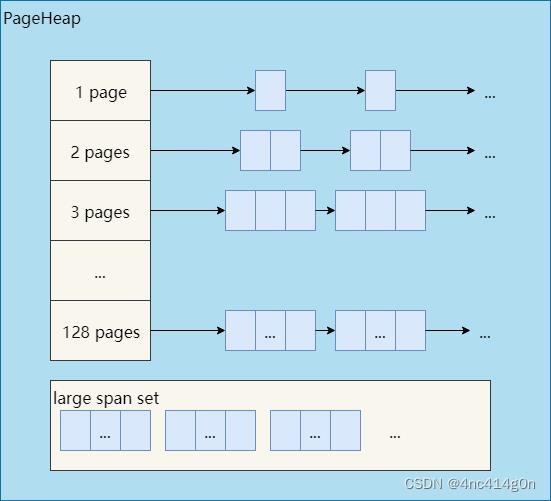
CentralCache中的空闲对象又是从何而来呢?答案是之前提到的PageHeap——TCMalloc对可动态分配的内存的抽象。
- 当CentralCache中的空闲对象不够用时,CentralCache会向PageHeap申请一块内存(可能来自PageHeap的缓存,也可能向系统申请新的内存),并将其拆分成一系列空闲对象,添加到对应size class的CentralFreeList中。
- PageHeap内部根据内存块(span)的大小采取了两种不同的缓存策略。128个page以内的span,每个大小都用一个链表来缓存,超过128个page的span,存储于一个有序set(std::set)。讨论TCMalloc的实现细节时再具体分析,现在可以认为PageHeap的简化结构如下
内存回收
上面说的都是内存分配,内存回收的情况是怎样的?
- 应用程序调用free()或delete一个小对象时,仅仅是将其插入到ThreadCache中其size class对应的FreeList中而已,不需要加锁,因此速度也是非常快的。
- 只有当满足一定的条件时,ThreadCache中的空闲对象才会重新放回CentralCache中,以供其他线程取用。同样的,当满足一定条件时,CentralCache中的空闲对象也会还给PageHeap,PageHeap再还给系统。
- 内存在这些组件之间的移动会在后文详细讨论,现在先忽略这些细节。
小结
总结一下,小对象分配流程大致如下:
- 将要分配的内存大小映射到对应的size class。
- 查看ThreadCache中该size class对应的FreeList。
- 如果FreeList非空,则移除FreeList的第一个空闲对象并将其返回,分配结束。
- 如果FreeList是空的:
- 从CentralCache中size class对应的CentralFreeList获取一堆空闲对象。
- 如果CentralFreeList也是空的,则:
- 向PageHeap申请一个span。
- 拆分成size class对应大小的空闲对象,放入CentralFreeList中。
- 将这堆对象放置到ThreadCache中size class对应的FreeList中(第一个对象除外)。
- 返回从CentralCache获取的第一个对象,分配结束
中对象分配
超过256KB但不超过1MB(128个page)的内存分配被认为是中对象分配,采取了与小对象不同的分配策略。
- 首先,TCMalloc会将应用程序所要申请的内存大小向上取整到整数个page(因此,这里会产生1B~8KB的内部碎片)。之后的操作表面上非常简单,向PageHeap申请一个指定page数量的span并返回其起始地址即可:
Span* span = Static::pageheap()->New(num_pages); result = (PREDICT_FALSE(span == NULL) ? NULL : SpanToMallocResult(span)); return result;
- 问题在于,PageHeap是如何管理这些span的?即PageHeap::New()是如何实现的。
- 前文说到,PageHeap提供了一层缓存,因此PageHeap::New()并非每次都向系统申请内存,也可能直接从缓存中分配。
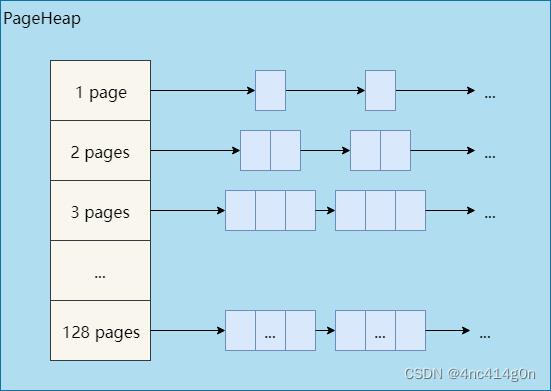
- 对128个page以内的span和超过128个page的span,PageHeap采取的缓存策略不一样。为了描述方便,以下将128个page以内的span称为小span,大于128个page的span称为大span。
先来看小span是如何管理的,大span的管理放在大对象分配一节介绍。
- PageHeap中有128个小span的链表,分别对应1~128个page的span
假设要分配一块内存,其大小经过向上取整之后对应k个page,因此需要从PageHeap取一个大小为k个page的span,过程如下:
- 从k个page的span链表开始,到128个page的span链表,按顺序找到第一个非空链表。
- 取出这个非空链表中的一个span,假设有n个page,将这个span拆分成两个span:
- 一个span大小为k个page,作为分配结果返回。
- 另一个span大小为n – k个page,重新插入到n – k个page的span链表中。
- 如果找不到非空链表,则将这次分配看做是大对象分配,分配过程详见下文。
大对象分配
超过1MB(128个page)的内存分配被认为是大对象分配,与中对象分配类似,也是先将所要分配的内存大小向上取整到整数个page,假设是k个page,然后向PageHeap申请一个k个page大小的span。
对于中对象的分配,如果上述的span链表无法满足,也会被当做是大对象来处理。也就是说,TCMalloc在源码层面其实并没有区分中对象和大对象,只是对于不同大小的span的缓存方式不一样罢了。
大对象分配用到的span都是超过128个page的span,其缓存方式不是链表,而是一个按span大小排序的有序set(std::set),以便按大小进行搜索。
假设要分配一块超过1MB的内存,其大小经过向上取整之后对应k个page(k>128),或者是要分配一块1MB以内的内存,但无法由中对象分配逻辑来满足,此时k <= 128。不管哪种情况,都是要从PageHeap的span set中取一个大小为k个page的span,其过程如下:
- 搜索set,找到不小于k个page的最小的span(best-fit),假设该span有n个page。
- 将这个span拆分为两个span:
- 一个span大小为k个page,作为结果返回。
- 另一个span大小为n – k个page,如果n – k > 128,则将其插入到大span的set中,否则,将其插入到对应的小span链表中。
- 如果找不到合适的span,则使用sbrk或mmap向系统申请新的内存以生成新的span,并重新执行中对象或大对象的分配算法
小结
以上讨论忽略了很多实现上的细节,比如PageHeap对span的管理还区分了normal状态的span和returned状态的span,接下来会详细分析这些细节。
在此之前,画张图概括下TCMalloc的管理内存的策略:
可以看到,不超过256KB的小对象分配,在应用程序和内存之间其实有三层缓存:PageHeap、CentralCache、ThreadCache。而中对象和大对象分配,则只有PageHeap一层缓存
6)TCMalloc的实现细节
算法概览一节涉及到了很多概念,比如Page,Span,Size Class,PageHeap,ThreadCache等,但只是粗略的一提,本节将详细讨论这些概念所涉及的实现细节
① Page
Page是TCMalloc管理内存的基本单位(这里的page要区分于操作系统管理虚拟内存的page),page的默认大小为8KB,可在configure时通过选项调整为32KB或64KB。
./configure <other flags> --with-tcmalloc-pagesize=32 (or 64)page越大,TCMalloc的速度相对越快,但其占用的内存也会越高。简单说,就是空间换时间的道理。默认的page大小通过减少内存碎片来最小化内存使用,但跟踪这些page会花费更多的时间。使用更大的page则会带来更多的内存碎片,但速度上会有所提升。官方文档给出的数据是在某些google应用上有3%~5%的速度提升。
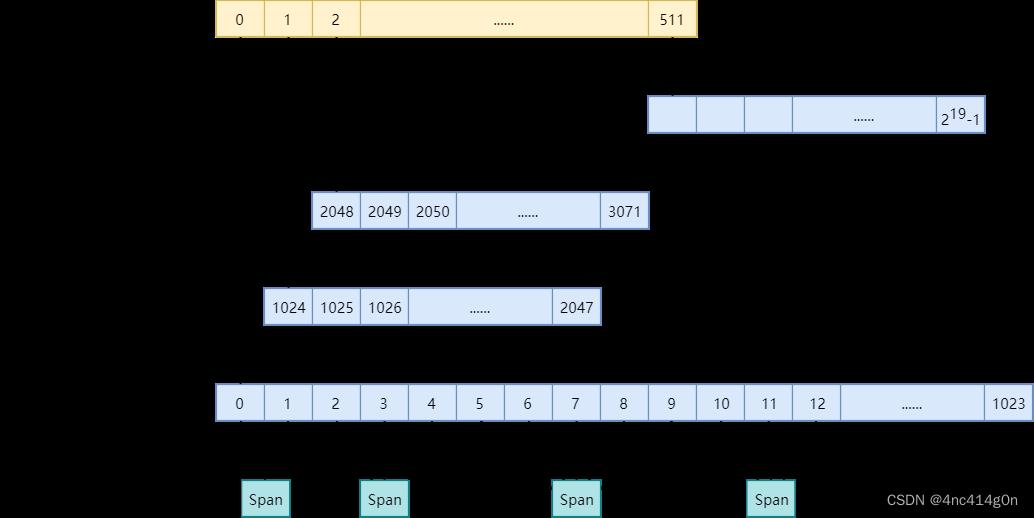
② PageID
TCMalloc并非只将堆内存看做是一个个的page,而是将整个虚拟内存空间都看做是page的集合。从内存地址0x0开始,每个page对应一个递增的PageID,如下图(以32位系统为例):
对于任意内存地址ptr,都可通过简单的移位操作来计算其所在page的PageID:static const size_t kPageShift = 13; // page大小:1 << 13 = 8KB const PageID p = reinterpret_cast<uintptr_t>(ptr) >> kPageShift;即,ptr所属page的PageID为ptr / page_size。

③ Span
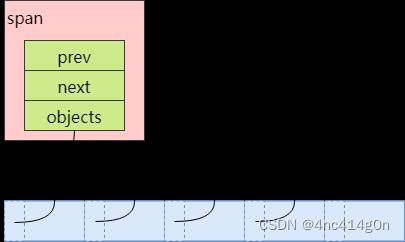
一个或多个连续的Page组成一个Span(a contiguous run of pages)。TCMalloc以Span为单位向系统申请内存。
如图,第一个span包含2个page,第二个和第四个span包含3个page,第三个span包含5个page。
- 一个span记录了起始page的PageID(start),以及所包含page的数量(length)。
- 一个span要么被拆分成多个相同size class的小对象用于小对象分配,要么作为一个整体用于中对象或大对象分配。当作用作小对象分配时,span的sizeclass成员变量记录了其对应的size class。
- span中还包含两个Span类型的指针(prev, next),用于将多个span以链表的形式存储。

span的三种状态
一个span处于以下三种状态中的一种:
- IN_USE
- ON_NORMAL_FREELIST
- ON_RETURNED_FREELIST
IN_USE比较好理解,正在使用中的意思,要么被拆分成小对象分配给CentralCache或者ThreadCache了,要么已经分配给应用程序了。因为span是由PageHeap来管理的,因此即使只是分配给了CentralCache,还没有被应用程序所申请,在PageHeap看来,也是IN_USE了。
ON_NORMAL_FREELIST和ON_RETURNED_FREELIST都可以认为是空闲状态,区别在于,ON_RETURNED_FREELIST是指span对应的内存已经被PageHeap释放给系统了(在Linux中,对于MAP_PRIVATE|MAP_ANONYMOUS的内存使用madvise来实现)。需要注意的是,即使归还给系统,其虚拟内存地址依然是可访问的,只是对这些内存的修改丢失了而已,在下一次访问时会导致page fault以用0来重新初始化
空闲对象链表
被拆分成多个小对象的span还包含了一个记录空闲对象的链表objects,由CentralFreeList来维护。
对于新创建的span,将其对应的内存按size class的大小均分成若干小对象,在每一个小对象的起始位置处存储下一个小对象的地址,首首相连
但当span中的小对象经过一系列申请和回收之后,其顺序就不确定了:
可以看到,有些小对象已经不再空闲对象链表objects中了,链表中的元素顺序也已经被打乱。
空闲对象链表中的元素乱序没什么影响,因为只有当一个span的所有小对象都被释放之后,CentralFreeList才会将其还给PageHeap

④ PageMap
PageMap之前没有提到过,它主要用于解决这么一个问题:给定一个page,如何确定这个page属于哪个span?
- 即,PageMap缓存了PageID到Span的对应关系。
- 32位系统、x86-64、arm64使用两级PageMap,以32位系统为例
在root_数组中包含512个指向Leaf的指针,每个Leaf又是1024个void*的数组,数组索引为PageID,数组元素为page所属Span的指针。一共219个数组元素,对应32位系统的219个page。
使用两级map可以减少TCMalloc元数据的内存占用,因为初始只会给第一层(即root_数组)分配内存(2KB),第二层只有在实际用到时才会实际分配内存。而如果初始就给219个page都分配内存的话,则会占用219 * 4 bytes = 2MB的内存
底层使用的基数树:
⑤ Size Class
TCMalloc将每个小对象的大小(1B~256KB)分为85个类别(官方介绍中说是88个左右,但我个人实际测试是85个,不包括0字节大小),称之为Size Class,每个size class一个编号,从0开始递增(实际编号为0的size class是对应0字节,是没有实际意义的)。
- 举个例子,896字节对应编号为30的size class,下一个size class 31大小为1024字节,那么897字节到1024字节之间所有的分配都会向上舍入到1024字节。
SizeMap::Init()实现了对size class的划分,规则如下
划分跨度
TCMalloc为了提高内存分配效率和减少内存的浪费,对小内存进行了细化分类,在默认的情况下:
16字节以内,每8字节划分一个size class。
- 满足这种情况的size class只有两个:8字节、16字节。
16~128字节,每16字节划分一个size class。
- 满足这种情况的size class有7个:32, 48, 64, 80, 96,
112, 128字节。 128B~256KB,按照每次步进(size / 8)字节((2(n+1)-2n)/8)的长度划分(n的值为log2(size)取整),并且步长需要向下对齐到2的整数次幂(见函数
AlignmentForSize()),比如:
- 144字节:128 + 128 / 8 = 128 + 16 = 144
- 160字节:144 + 144 / 8 = 144 + 18 = 144 + 16 = 160
- 176字节:160 + 160 / 8 = 160 + 20 = 160 + 16 = 176 以此类推
一次移动多个空闲对象
ThreadCache会从CentralCache中获取空闲对象,也会将超出限制的空闲对象放回CentralCache。ThreadCache和CentralCache之间的对象移动是批量进行的,即一次移动多个空闲对象。CentralCache由于是所有线程公用,因此对其进行操作时需要加锁,一次移动多个对象可以均摊锁操作的开销,提升效率。
那么一次批量移动多少呢?每次移动64KB大小的内存,即因size class而异,但至少2个,至多32个(可通过环境变量TCMALLOC_TRANSFER_NUM_OBJ调整)。
移动数量的计算也是在size class初始化的过程中计算得出的。
一次申请多个page
对于每个size class,TCMalloc向系统申请内存时一次性申请n个page(一个span),然后均分成多个小对象进行缓存,以此来均摊系统调用的开销。
不同的size class对应的page数量是不同的,如何决定n的大小呢?从1个page开始递增,一直到均分成若干小对象后所剩的空间小于span总大小的1/8为止,因此,浪费的内存被控制在12.5%以内。这是TCMalloc减少内部碎片的一种措施。
另外,所分配的page数量还需满足一次移动多个空闲对象的数量要求(源码中的注释是这样说的,不过实际代码是满足1/4即可,原因不明)
合并操作
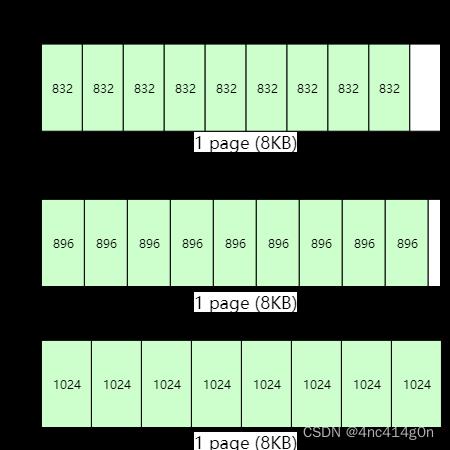
在上述规则之上,还有一个合并操作:TCMalloc会将相同page数量,相同对象数量的相邻的size class合并为一个size class。比如
- 第30个size class的对象大小是832字节,page数量为1个,因此包含8192 / 832 = 9个小对象。
- 第31个size class对应的page数量(1个)和对象数量(9个)跟第30个size class完全一样,因此第30个size class和第31个size class合并,所以第30个size class对应的对象大小为896字节。
- 下一个size class对应的对象大小为1024字节,page数量为1个,因此对象数量是8个,跟第30个size class的对象数量不一样,无法合并。
- 最终,第30个size class对应的对象大小为896字节
记录映射关系
由以上划分规则可以看到,一个size class对应:
- 一个对象大小
- 一个申请page的数量
- 一个批量移动对象的数量
TCMalloc将size class与这些信息的映射关系分别记录在三个以size class的编号为索引的数组中(
class_to_size_ , num_objects_to_move_, class_to_pages_)
还有一项非常重要的映射关系:小对象大小到size class编号的映射。TCMalloc将其记录在一个一维数组class_array_中。
256KB以内都是小对象,而size class的编号用一个字节就可以表示,因此存储小对象大小对应的size class编号需要256K个unsigned char,即256KB的内存。但由于size class之间是有间隔的(1024字节以内间隔至少8字节,1024以上间隔至少128字节),因此可以通过简单的计算对class_array_的索引进行压缩,以减少内存占用。
给定大小s,其对应的class_array_索引计算方式如下:(位运算)// s <= 1024 static inline size_t SmallSizeClass(size_t s) return (static_cast<uint32_t>(s) + 7) >> 3; // s > 1024 static inline size_t LargeSizeClass(size_t s) return (static_cast<uint32_t>(s) + 127 + (120 << 7)) >> 7;当s = 256KB时,计算结果即为class_array_的最大索引2169,因此数组的大小为2170字节
计算任意内存地址对应的对象大小
当应用程序调用free()或delete释放内存时,需要有一种方式获取所要释放的内存地址对应的内存大小。结合前文所述的各种映射关系,在TCMalloc中按照以下顺序计算任意内存地址对应的对象大小:
- 计算给定地址计所在的PageID(ptr >> 13)
- 从PageMap中查询该page所在的span
- span中记录了size class编号
- 据size class编号从class_to_size_数组中查询对应的对象大小
这样做的好处是:不需要在内存块的头部记录内存大小,减少内存的浪费。
小结
size class的实现中有很多省空间省时间的做法:
- 省空间
- 控制划分跨度的最大值(8KB),减少内部碎片
- 控制一次申请page的数量,减少内部碎片
- 通过计算和一系列元数据记录内存地址到内存大小的映射关系,避免在实际分配的内存块中记录内存大小,减少内存浪费
- 两级PageMap或三级PageMap
- 压缩class_array_
- 省时间
- 一次申请多个page
- 一次移动多个空闲对象
线程局部缓存ClassSize分析(摘自其他文章)
问题
- 小对象是如何划分的?
- 对于任意一个小于kMaxSize的size是如何映射到某一种缓存对象上?
SizeMap分析
TCMalloc对这些细化分类构建了两个映射表,即
- class_array_[kClassArraySize]:表示了size到class的映射关系(size需要先经过函数ClassIndex(size) 转换 )
- class_to_size_[kNumClasses]:表示了class到size的映射关系。
要申请一个size的内存时,先从class_array_[ClassIndex(size)]查到size对应的sizeclass,然后从映射class_to_size_[kNumClasses]获取实际获取的内存大小。
同时TCMalloc另外维护了两种映射表:
- class_to_pages_[kNumClasses]:class_to_pages_[kNumClasses]表示了Central Cache每次从PageHeap获取内存时,对应的sizeclass每次需要从PageHeap获取几页内存
- num_objects_to_move_[kNumClasses:num_objects_to_move_[kNumClasses]表示了ThreadCache每次从Central Cache获取内存时,对应的sizeclass每次需要从Central Cache获取的buffer(Object)个数。
在do_malloc函数中有如下两行代码:
size_t cl = Static::sizemap()->SizeClass(size); size = Static::sizemap()->class_to_size(cl);不难理解,这两行代码就是size映射到它最接近的缓存对象上。接下来继续探究SizeClass(size_t)和class_to_(size_t)两个函数,这两个函数在
common.h文件中,代码如下:class SizeMap private: ... //其他暂时不关心的 //------------------------------------------------------------------- // Mapping from size to size_class and vice versa //------------------------------------------------------------------- // Sizes <= 1024 have an alignment >= 8. So for such sizes we have an // array indexed by ceil(size/8). Sizes > 1024 have an alignment >= 128. // So for these larger sizes we have an array indexed by ceil(size/128). // // We flatten both logical arrays into one physical array and use // arithmetic to compute an appropriate index. The constants used by // ClassIndex() were selected to make the flattening work. // // Examples: // Size Expression Index // ------------------------------------------------------- // 0 (0 + 7) / 8 0 // 1 (1 + 7) / 8 1 // ... // 1024 (1024 + 7) / 8 128 // 1025 (1025 + 127 + (120<<7)) / 128 129 // ... // 32768 (32768 + 127 + (120<<7)) / 128 376 static const int kMaxSmallSize = 1024; static const size_t kClassArraySize = ((<以上是关于怎样检测有没有使用tcmalloc的主要内容,如果未能解决你的问题,请参考以下文章