mahout in Action2.2-聚类介绍-K-means聚类算法
Posted brucemengbm
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了mahout in Action2.2-聚类介绍-K-means聚类算法相关的知识,希望对你有一定的参考价值。
1 实战操作了解聚类
2.了解相似性概念
3 使用mahout执行一个简单的聚类实例
4.用于聚类的各种不同的距离測算方法
作为人类,我们倾向于与志同道合的人合作—“鸟的羽毛聚集在一起。
我们可以发现反复的模式通过联系在我们的记忆中的我们看到的、听到的、问道的、尝到的东 西。 比如,相比較盐 ,糖可以是我们很多其它地想起蜜。所以我们把糖和蜜的味道结合起来叫他们甜蜜。
甚至我们不知道甜蜜的味道,可是知道他跟世界上全部的含糖的东西是相似的。是同 一类的。我们还知道它与盐是不同类的东西。无意中。我们不同的味道使用了聚类。把糖和盐做了聚类。每一个组有数百个项目。
在自然界中,我们观察不同类型的群体。
觉得猿与猴是同一种灵长类动物。
全部的猴子 都有一些性状如短高度,长尾巴,和一个扁平的鼻子。相反。猿类有较大的尺寸,长长的手臂,和更大的头。猿看起来不同于猴子,但都喜欢香焦。所以我们能够认 为猿和猴子作为两个不同的组,或作为一个单一的爱香蕉的灵长类动物群。我们考虑一个集群全然取决于我们选择的项目之间的相似性測量的特点(在这样的情况下, 灵长类动物)。
在这一章中,从mahout学习的聚类的样例中。我们将会知道聚类是什么。怎样有数据概念联系起来。让我们从基础開始吧!
7.1 聚类的基础
聚类的过程是怎么样的呢?假如你能够去有成千上万的书籍的图书馆。在图书馆内 ,图书是杂乱无章的。要找到想读的书必须横扫全部的书籍,一本一本的才干特定的书。这不仅是繁琐和缓慢。并且很枯燥。
依照标题的字母顺序排序会对读者通过标题寻找有非常大的帮助,假设大多数人仅仅是简单地浏览一下。仅仅是找一个大概的主题的书籍呢?这样通过依照书籍的主题进 行分类要比依照标题的字母顺序更实用。可是怎样进行分组呢?刚刚接手这份工作。你也不会知道全部的书籍是什么的?是冲浪的、浪漫的。或你没有遇到过的课 题。
通过按主题把书籍分类。你不得不把全部书放在同一线上,一本一本的開始阅读。当你遇到一本书的内容是类似曾经的一本书,你就返回去把它们放在在一起。当你完毕,你从数千上万的书中获取到你要的主题的一堆书。
干得好!这是你的第一个聚类的经验。假设一百个主题组太多了。你就得从头開始和反复刚才的过程获得书堆。直到你的主题,从还有一个堆是全然不同的。
聚类是全部关于组织项目从一个给定集合成一组类似的项目。在某些方面。这些集群能够被觉得是作为项目相似集,可是与其它集群项目不同的。
聚类集合包括三项
● 算法 ———–这是用来组书籍的方法
●相似性和差异性的概念——-一个在前面讨论的,依赖于这本书是否属于已经存在的堆。还是应 该另组新一堆的推断。
●终止条件———图书馆的样例中。当达到这些书不能堆积起来了,或这些堆已经相当不同的。这就是终止
在这个简单的样例中,圈出来的显然是基于距离三个集群。代表了聚类的结果。圆是一个在聚类方面是一个非常好的方法。
因为群组通过中心点和半径来定义的,圆的中心被叫为群重心。或者群平均(平均值),群重心的坐标是类簇中的全部点的x,y轴的平均值
项目的相似性測量

图7.1x-y平面图的点。圆圈代表了聚类。在平面团中的点归类了单个逻辑群组。聚类算法故意于识别群组
在本章中,我们将聚类可视化为一个几何问题。
聚类的核心是使用几何的技术表达不同距离的測算。
我们找到一些重要的距离測算法和聚类关系。
平面聚类点与文本聚类之间的详细相似性就能够抽象出来。
在后面的章节中。我们探讨了广泛用于聚类的方法数据,以及mahout 中使用
方法。
图书馆的样例是将书分堆直到达到一定阈值的一种策 略。
在这个样例中形成的簇的数目取决于数据;基于很多书和临界值,你可能发现了100后者20。甚至是1个类簇。一个更好的策略是建立目标簇,而不是一个 临界值,然后找到最好的群组与约束。接下来我们将具体的介绍目标簇和不同的变量
7.2项目的相似性測量
聚类的重要问题是找到一方法。通过不论什么两个数中的一个数来量化相似性。注意一下我们整片文章中使用的专业术语 :项目和点,这两个是聚类数据的单位。
在X-Y平面的样例,相似性的度量(相似性度量)的分为两个点之间的欧几里德距离。
图书馆的样例没有这样的清晰的数学手段,而不是全然依赖的智慧馆员之间的相似度来推断书。这工作不在我们的案例,由于我们须要一个度量。可在计算机上实现.
一个可能的度量是基于两本书的标题共同含有的词的数量。
基于哈利·波特:哲学家的石头和哈利·波特这两本书:阿兹卡班的囚徒中常见的三个词:哈利、波特、the。
即时魔戒也:两塔是类似于哈利·波特系列。这一措施相似不会捕获这一切。你须要改变的相似性度量来对书籍本身的内容帐户。
你能够将单词计数。
仅仅可惜。说的easy做起来难。
这些书不仅有几百个网页的文本。并且英语的特点也使的分类方法更加困难。在英语文本中有一些非常频繁的次比如 a,an ,the 等等。它总是常常发生但又不能说明这是这两本书的相似点。
为了对抗这样的影响。你能够在计算中使用的加权值,而且使用低权重表示这些词来降低对相似度值的影响。
在出现非常多次的词使用低权重值,出现少的用高权重。你能够衡量一个特定的书常常出现的,比方那些强烈建议内容的书籍–类似于魔术类的哈利波特。
你给书中的每个单词一个权重。就能算出这本中的相似性–就是全部词的词频乘以每个词的权重的和。
假设这两本书的长度同样,那么这个就是一个比較适当的方法。
假设一本书有300页,还有一本有1000页呢?当然书页大的书的词也多。
聚类算法
9.1 K-means聚类
K-means须要用户设定一个聚类个数(k)作为输入数据,有时k值可能很大(10,000),这是Mahout闪光的(shines)地方,它确保聚类的可測量性。
为了用k-means达到高质量的聚类,须要预计一个k值。预计k值一种近似的方法是依据你须要的聚类个数。比方100万篇文章,假设平均500篇 分为一类,k值能够取2000(1000000/500)。
这样的预计聚类个数很模糊。但k-means算法就是生成这样的近似的聚类。
9.1.1 All you need to know about k-means
以下看一下k-means算法的细节,K-means算法是硬聚类算法。是典型的局域原型的目标函数聚类方法的代表,它是数据点到原型的某种距离作 为优化的目标函数,利用函数求极值的方法得到迭代运算的调整规则。
算法採用误差平方和准则函数作为聚类准则函数。
K-means算法是非常典型的基于距离的聚类算法,採用距离作为相似性的评价指标。即觉得两个对象的距离越近,其相似度就越大。该算法觉得簇是由距离靠近的对象组成的。因此把得到紧凑且独立的簇作为终于目标。k个初始类聚类中心点的选取对聚类结果具有较大的。
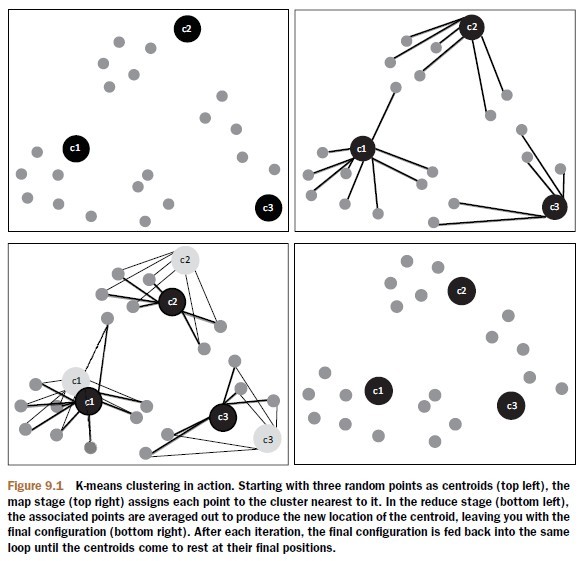
算法步骤:
(1)随机选取随意k个对象作为初始聚类中心,初始代表一个簇。
(2)计算点到质心的距离,并把它归到近期的质心的类。
(3)又一次计算已经得到的各个类的质心;
(4)迭代2~3步直至新的质心与原质心相等或小于指定阈值。算法结束。
这样的两步算法是最大期望算法(EM)的典型样例,
第一步是计算期望(E)。利用对隐藏变量的现有预计值,计算其最大似然预计值;
第二步是最大化(M)。最大化在 E 步上求得的最大似然值来计算參数的值。
M 步上找到的參数预计值被用于下一个 E 步计算中,这个过程不断交替进行。
9.1.2 Running k-means clustering
K-mean聚类用到KMeansClusterer或KMeansDriver类。前一个是在内存(in-memory)里对节点聚类。后者採用 MapReduce任务运行。
这两种方法都能够就像一个普通的Java程序运行,而且能够从硬盘读取和写入数据。
它们也能够在hadoop上运行聚类。通 过分布式文件系统读写数据。
以下举例,使用一个随机点生成器函数来创建一些点。
这些点生成矢量格式的点作为一个正态分布环绕着一个中心。使用Mahout的in-memory K-means 聚类方法对这些点聚类。
创建节点:generateSamples方法,取(1,1)为中心点。标准差为2,400个环绕着(1,1)的随机点,近似于正态分布。
另外又取了2个数据集。中心分别为(1,0)和(0,2)。标准差分别为0.5和0.1。
KMeansClusterer.clusterPoints()方法用到一下參数:
- List<Vector>作为输入。
- 距离算法DistanceMeasure採用EuclideanDistanceMeasure;
- 聚类的阈值Threshold为0.01;
- 聚类的个数为3;
- 聚类的中心点採用RandomPointsUtil。随机选取的节点。


Mahout-example里的DisplayKMeans类能够直观的看到该算法在二维平面的结果。9.2节将介绍执行一个Java Swing application的DisplayKMeans。
假设数据量非常大时,应採取MapReduce执行方式,将聚类算法执行在多个机器上,每一个mapper得到一个子集的点,每一个子集执行一个mapper。这些mapper任务计算出近期的集群作为输入流。
K-means聚类的MapReduce Job
採用KMeansDriver类的run()方法,须要输入的參数有:
- Hadoop的配置conf。
- 输入Vectors的路径。SequenceFile格式;
- 初始化聚类中心的路径,SequenceFile格式;
- 输出结果的路径,SequenceFile格式;
- 求相似距离时採用的方法。这里採用EuclideanDistanceMeasure。
- 收敛的阈值,没有超过该阈值的点可移动时,停止迭代。
- 最大迭代次数,这是硬性限制,到达该最大迭代次数时,聚类停止;
- true-迭代结束后聚类。
- true-串行运行该算法,false-并行运行该算法;
public static void run(Configuration conf,Path input,Path clustersIn,Path output,
DistanceMeasure measure,
double convergenceDelta,
int maxIterations,
boolean runClustering,
boolean runSequential)

採用SparseVectorsFromSequenceFile工具,将sequenceFile转换成Vector。由于K-means算法须要用户初始化k个质心。
以上是关于mahout in Action2.2-聚类介绍-K-means聚类算法的主要内容,如果未能解决你的问题,请参考以下文章