机器学习——梯度下降法
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习——梯度下降法相关的知识,希望对你有一定的参考价值。
代价函数(cost function):弄清楚如何用最接近的直线和数据相拟合
线性拟合实际上是一个最小化的问题,使代价函数
![]()
(平方误差函数)最小(最小二乘法),采用梯度下降算法可将代价函数J最小化
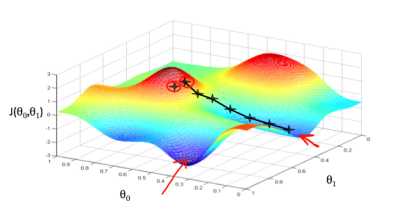
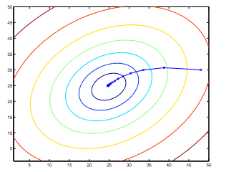
梯度下降模拟图
在假设函数的参数范围内随机选择一组特定参数,我们以最快下降的方向降低成本函数。每个步骤的大小由参数α确定,称为学习速率(步长)。
梯度下降算法是:重复直至收敛。而步骤的方向由偏导数确定,在每次迭代中,要同时更新参数。
如下:
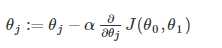

有两个参数情况下,左边是对的,保持同步更新
注解:
如果学习速率α太小,那么梯度下降就会很缓慢
如果学习速率α太大,则会导致震荡甚至无法收敛
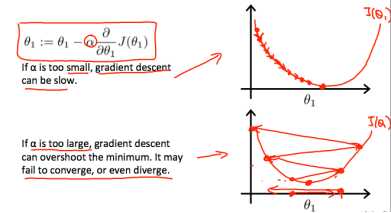
当学习速率到一个局部最低点时,不需要减小α,因为随着斜率的下降,θ1会减小移动的步伐,直至到达局部最小点
将梯度下降算法应用到线性回归模型中

找到使代价函数最小的那个点
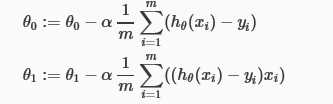
同步更新(梯度下降图)
重复迭代直至收敛(适用于多个变量)

梯度下降运算中的实用技巧
特征缩放:
如果含有两个特征x1和x2,如果x1范围为0~2000,x2范围在0~5,那么画出代价函数的轮廓图将非常偏斜
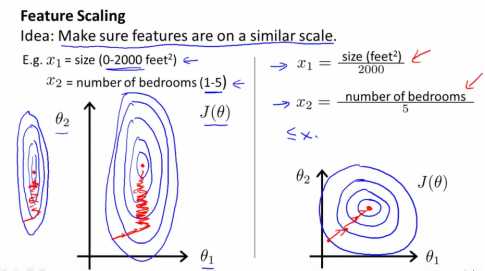
如果用这个代价函数来运营梯度下降的话,可能需要花很长时间并且会来回波动最终收敛到全局最小值。采用特征缩放,消耗掉这些值的范围,这样用梯度下降算法会下降更快。
一般比较合适的是将特征的取值约束到-1~+1的范围内,接近即可,范围太大和太小都不合理。
均值归一化:
有时也采用这种方法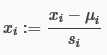
μi是所有特征的平均值,Si是范围值。均值归一化涉及从该值的值中减去输入变量的平均值输入变量导致输入变量的新的平均值为零。
如何保证梯度下降算法正确的工作
怎样选择学习率α
如果α太小,那么梯度下降将异常缓慢
如果α太大,那么可能不会在每次迭代中下降,或者收敛

如果学习率α足够小,那么可以确保在每次迭代中都下降,但太小则导致收敛特别缓慢。
我们还可以改进我们的特征,如长x1,宽x2,则可用面积x3=x1*x2来合并参数。
如果新的特征是原特征的平方或立方,那么特征缩减将变得尤为重要。
以上是关于机器学习——梯度下降法的主要内容,如果未能解决你的问题,请参考以下文章