走入计算机的第三十六天(自己创建锁及锁的类型)
Posted 方杰0410
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了走入计算机的第三十六天(自己创建锁及锁的类型)相关的知识,希望对你有一定的参考价值。
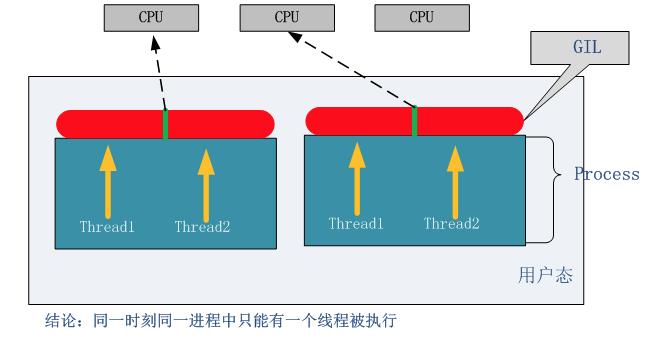
Python中的线程是操作系统的原生线程,Python虚拟机使用一个全局解释器锁(Global Interpreter Lock)来互斥线程对Python虚拟机的使用。为了支持多线程机制,一个基本的要求就是需要实现不同线程对共享资源访问的互斥,所以引入了GIL。
GIL:在一个线程拥有了解释器的访问权之后,其他的所有线程都必须等待它释放解释器的访问权,即使这些线程的下一条指令并不会互相影响。
在调用任何Python C API之前,要先获得GIL
GIL缺点:多处理器退化为单处理器;优点:避免大量的加锁解锁操作.
2.3.1 GIL的早期设计
Python支持多线程,而解决多线程之间数据完整性和状态同步的最简单方法自然就是加锁。 于是有了GIL这把超级大锁,而当越来越多的代码库开发者接受了这种设定后,他们开始大量依赖这种特性(即默认python内部对象是thread-safe的,无需在实现时考虑额外的内存锁和同步操作)。慢慢的这种实现方式被发现是蛋疼且低效的。但当大家试图去拆分和去除GIL的时候,发现大量库代码开发者已经重度依赖GIL而非常难以去除了。有多难?做个类比,像mysql这样的“小项目”为了把Buffer Pool Mutex这把大锁拆分成各个小锁也花了从5.5到5.6再到5.7多个大版为期近5年的时间,并且仍在继续。MySQL这个背后有公司支持且有固定开发团队的产品走的如此艰难,那又更何况Python这样核心开发和代码贡献者高度社区化的团队呢?
2.3.2 GIL的影响
无论你启多少个线程,你有多少个cpu, Python在执行一个进程的时候会淡定的在同一时刻只允许一个线程运行。
所以,python是无法利用多核CPU实现多线程的。
这样,python对于计算密集型的任务开多线程的效率甚至不如串行(没有大量切换),但是,对于IO密集型的任务效率还是有显著提升的。
所以对于GIL,既然不能反抗,那就学会去享受它吧!
同步锁
锁通常被用来实现对共享资源的同步访问。为每一个共享资源创建一个Lock对象,当你需要访问该资源时,调用acquire方法来获取锁对象(如果其它线程已经获得了该锁,则当前线程需等待其被释放),待资源访问完后,再调用release方法释放锁。


1 import threading 2 3 import time 4 def sub(): 5 global num #引用全局变量 6 lock.acquire() #启动锁 7 temp=num #赋值变量 8 time.sleep(0.1) 睡眠 9 num=temp-1 #变量自减一 10 lock.release() #关闭锁 11 12 time.sleep(2) #睡眠时间 13 num=100 #全局变量 14 l=[] #定义空的字典 15 lock=threading.Lock() #创建锁 16 for i in range(100): # #创建线程的数量 17 t=threading.Thread(target=sub,args=()) #创建对象线程 18 t.start() #启动对象线程 19 l.append(t) #将对象线程写入空字典中 20 for t in l: 21 t.join() #主线程运行完后,子线程才能运行 22 print(num)
import threading
R=threading.Lock()
R.acquire()
\'\'\'
对公共数据的操作
\'\'\'
R.release()
所谓死锁: 是指两个或两个以上的进程或线程在执行过程中,因争夺资源而造成的一种互相等待的现象,若无外力作用,它们都将无法推进下去。此时称系统处于死锁状态或系统产生了死锁,这些永远在互相等待的进程称为死锁进程。
1 import threading 2 import time 3 class MyThread(threading.Thread): ##创建一个子类,父类是(threading.Thread) 4 def __init__(self): 5 threading.Thread.__init__(self) #调用父类的功能 6 def run(self): #用父类的功能 7 self.foo() #调用自己的功能 8 self.fo() #调用自己的功能 9 def foo(self): #创建自己的功能 10 LockA.acquire() #开启大锁 11 print(\'qqqqq\') #启动功能 12 LockB.acquire() #开启小锁 13 print(\'wwwww\') #启动功能 14 LockB.release() #关闭小锁 15 LockA.release() #关闭大锁 16 def fo(self): #创建自己的功能 17 LockB.acquire() #开启小锁 18 print(\'lllll\') #启动功能 19 LockA.acquire() #开启大锁 20 time.sleep(1) 21 print(\'dddddd\') #启动功能 22 LockA.release() #关闭大锁 23 LockB.release() #关闭小锁 24 LockA=threading.Lock() #创建大锁 25 LockB=threading.Lock() #创建小锁 26 for i in range(10): #创建线程的数量 27 t=MyThread() #创建对象 28 t.start() #启动对象 #两个锁同时运行,但是两个锁会打结,一个等待着一个 29 t.run() #对象调用父类下的功能,相当于串型
在Python中为了支持在同一线程中多次请求同一资源,python提供了可重入锁RLock。这个RLock内部维护着一个Lock和一个counter变量,counter记录了acquire的次数,从而使得资源可以被多次require。直到一个线程所有的acquire都被release,其他的线程才能获得资源。上面的例子如果使用RLock代替Lock,则不会发生死锁。
1 import threading 2 import time 3 class MyThread(threading.Thread): #调用父类的功能 4 def __init__(self): 5 threading.Thread.__init__(self) 6 def run(self): 7 self.foo() 8 self.fo() 9 def foo(self): 10 Lock.acquire() # 11 print(\'qqqqq\') 12 Lock.acquire() 13 print(\'wwwww\') 14 Lock.release() 15 Lock.release() 16 def fo(self): 17 Lock.acquire() 18 print(\'qqqqq\') 19 time.sleep(1) 20 Lock.acquire() 21 print(\'wwwww\') 22 Lock.release() 23 Lock.release() 24 Lock=threading.RLock() #创建一个锁R 25 for i in range(10): 26 t=MyThread() 27 t.start()
Semaphore管理一个内置的计数器,
每当调用acquire()时内置计数器-1;
调用release() 时内置计数器+1;
计数器不能小于0;当计数器为0时,acquire()将阻塞线程直到其他线程调用release()。
实例:(同时只有5个线程可以获得semaphore,即可以限制最大连接数为5):
1 import threading 2 import time 3 4 semaphore=threading.Semaphore(5) #创建同时执行的数量 5 def foo(): #创建对象 6 semaphore.acquire() #启动执行的数量 7 time.sleep(0.1) #睡眠时间 8 print(\'sb\') #打印 9 semaphore.release() #关闭执行数量 10 11 for i in range(100): #创建线程的数量 12 t=threading.Thread(target=foo,args=( )) #创建对象线程 13 t.start() #启动对象线程
Lock与Rlock的区别
这两种锁的主要区别是:RLock允许在同一线程中被多次acquire。而Lock却不允许这种情况。注意:如果使用RLock,那么acquire和release必须成对出现,即调用了n次acquire,必须调用n次的release才能真正释放所占用的琐。