谷歌开源了TensorFlow,世界就要马上被改变了吗
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了谷歌开源了TensorFlow,世界就要马上被改变了吗相关的知识,希望对你有一定的参考价值。
Google 开源了其第二代深度学习技术 TensorFlow——被使用在 Google搜索、图像识别以及邮箱的深度学习框架。这在相关媒体圈、工程师圈、人工智能公司、人工智能研究团队里有了一些讨论。比较有趣的是,微软亚洲研究院立刻向
媒体发邮件表示,我们发布了开源分布式机器学习工具包(DMTK)。
对于大众来说,这件事让人
“困惑”。从 “深度学习” 到 “分布式系统”,太多概念大众一知半解,现今给出的资料又让人难以理解。而对于 “Google 开源
TensorFlow” 这一事件,各个公司、团队、学术权威也是众说纷纭。因此,出门问问为大家 “破雾”,并讲一讲这次开源意味着什么。
什么是深度学习?
深
度学习系统是什么?深度学习理论于 2006年 被提出,它通过模拟 “人脑的神经网络”
来解释图像、声音和文本等数据。但是目前的计算机还达不到模拟人脑数量庞大的神经元(千亿级),因此便有了用到成千上万大型计算机(计算平台集群)来吸收
数据对其进行自动分类的 “分布式深度学习系统”。
TensorFlow 的起源和此次开源事件
将自家研发的深度学习系统命名为 “DistBelief”,它使得 Google
能够同时处理成千上万台大型计算机的数据,构建更大型的神经网络和大规模训练。Google
的搜索、图像识别及邮箱等均采用了该技术。一般情况下,深度学习系统都需要先设定好 feature(特征),再学习如何分辨。但
Google DistBelief 神奇的地方在于,“Google Brain” 开发团队 “XLab” 曾用它在未事先获取 “猫的特征描述”
信息的情况下,从大量 YouTube 视频中区分出了哪些是猫的视频。这意味着深度学习系统 “DistBelief” 自行总结出了猫的
feature(特征)!虽然这个案例的识别范围、识别率有待提高(81.7%),但作为人工智能最经典案例之一,为人工智能翻开了新的篇章。而 “猫”
的事件,也让曾经的 Google Brain 开发团队 “XLab” 的核心人员、现在被李彦宏挖到百度的吴恩达得到了
“Google Brain” 之父的美誉。不过,时代总是进步,而 “DistBelief” 有缺陷。
称,虽然 DistBelief 非常成功,但它仅仅以神经网络为目的、十分局限,而且很难进行配置。另外,DistBelief 牢牢绑定在
Google 的内部基础设施上,几乎不可能将代码与外界共享。因此,本文的主角,Google 的第二代深度学习系统 “TensorFlow”
横空出世了。
Google 表示,TensorFlow
在设计上尤其针对克服 DistBelief 的短板,灵活、更通用、易使用、更快,而且完全开源。TensorFlow
可以被架设在智能手机这样小的设备上,甚至仅一块电路板上,更灵活; TensorFlow
可以被使用在很多计算平台,无论是智能手机还是大型计算机、单个 CPU / GPU 计算机还是成百上千 GPU 卡组成的分布式系统,ARM 的还是
X86 的构架,更通用;TensorFlow 支持多种编程语言,提供了很多深度学习模型库,易使用;在很多指标上,TensorFlow 要比
DistBelief 要快一倍,更快。但是,学术界和工程界的一些朋友并不喜欢这个 “刚刚闯入” 开源界的 “小伙子”,判了它 “意义不大”
的死刑。“TensorFlow” 之所以 “开源” 却不讨好,是因为 TensorFlow 不是第一个被开源的深度学习系统,并且目前只开源了
“单机版”,而非能够识别猫的 “分布式版本”。除了并非第一以及只开源了单机版代码这两点外,Google 开源 TensorFlow
这件事最被人诟病的地方在于,在 “用事实”、“用数据” 说话的学术界、工程界,Google 并未用 “数据对比” 证明 TensorFlow 的
“灵活、更通用、易使用”。
对于 TensorFlow,出门问问的看法是,TensorFlow 对学术界意义不大,但是对工程界意义挺大。
TensorFlow 对工程界有意义:其它开源工具虽然众多 但对工程界很难有效使用
这次开源的 TensorFlow 是一种人工智能(更具体的说是深度学习)编程语言或计算框架,学术界从来都不缺少类似的开源工具,尤其是
“单机版工具包” 有很多。但是学术界的工具往往更多专注在核心算法上,在系统和工程方面比较欠缺,工业界很难直接有效的使用,而 Google 的
TensorFlow 在架构设计,跨平台可移植性,算法可扩展性等等偏工程方面会做的比较好。所以,TensorFlow
对学术界的帮助比较小,但对工业界的帮助有很大潜在可能性。比如语音识别、自然语言理解、计算机视觉、广告等等都可以应用这种深度学习算法,Google
也因为深度学习系统的应用使得 Google 语音识别水平提高 25%。
有意义归有意义,意义的大小
是另一回事了。在这个信息交流频繁的时代,没有公司能随便制造一个具有超大意义的事件或者跨时代的黑科技产品。对于工程界,TensorFlow
有意义但又不是神乎其神的东西,尤其是 Google 目前开源的 “单机版” 的 TensorFlow
意义要小一些。因为在工程界里,若要完成一整件事,如识别语音,TensorFlow
这种通用深度学习框架的存在更多是锦上添花,而非决定根本。比如说在一个可以应用的语音识别系统里, 除了深度学习算法外,还有很多工作是专业领域相关的
算法以及海量数据收集和工程系统架构的搭建。
其实,对于中国来说,TensorFlow
还有一个意义。在人工智能大潮下许多人和公司想入局,但大都没有能力理解并开发一个与国际同步的深度学习系统,而 TensorFlow
的存在会大大降低深度学习在各个行业中的应用难度。至于弄懂 TensorFlow 要花费大量时间的问题,就像很多公司用 Linux 或者
hadoop(一种分布式系统基础架构)但很少有公司弄懂了所有源代码一样,可以把 TensorFlow
当成一个黑盒,先快速用起来,之后再根据数据和专业领域知识来调整。
总的来说,如果 Google 按照其所说的那样,在未来完全开源 TensorFlow——包括其 “分布式版本”,那么 TensorFlow 对工程界的影响会更明显些——尤其对中国创业公司来说。 参考技术A Google 将自家研发的深度学习系统命名为 “DistBelief”,它使得 Google 能够同时处理成千上万台大型计算机的数据,构建更大型的神经网络和大规模训练。Google 的搜索、图像识别及邮箱等均采用了该技术。一般情况下,深度学习系统都需要先设定好 feature(特征),再学习如何分辨。但 Google DistBelief 神奇的地方在于,“Google Brain” 开发团队 “XLab” 曾用它在未事先获取 “猫的特征描述” 信息的情况下,从大量 YouTube 视频中区分除了哪些是猫的视频。这意味着深度学习系统 “DistBelief” 自行总结出了猫的 feature(特征)!虽然这个案例的识别范围、识别率有待提高(81.7%),但作为人工智能最经典案例之一,为人工智能翻开了新的篇章。而 “猫” 的事件,也让曾经的 Google Brain 开发团队 “XLab” 的核心人员、现在被李彦宏挖到百度的吴恩达得到了 “Google Brain” 之父的美誉。不过,时代总是进步,而 “DistBelief” 有缺陷。
Google 称,虽然 DistBelief 非常成功,但它仅仅以神经网络为目的、十分局限,而且很难进行配置。另外,DistBelief 牢牢绑定在 Google 的内部基础设施上,几乎不可能将代码与外界共享。因此,本文的主角,Google 的第二代深度学习系统 “TensorFlow” 横空出世了。
Google 表示,TensorFlow 在设计上尤其针对克服 DistBelief 的短板,灵活、更通用、易使用、更快,而且完全开源。TensorFlow 可以被架设在智能手机这样小的设备上,甚至仅一块电路板上,更灵活; TensorFlow 可以被使用在很多计算平台,无论是智能手机还是大型计算机、单个 CPU / GPU 计算机还是成百上千 GPU 卡组成的分布式系统,ARM 的还是 X86 的构架,更通用;TensorFlow 支持多种编程语言,提供了很多深度学习模型库,易使用;在很多指标上,TensorFlow 要比 DistBelief 要快一倍,更快。但是,学术界和工程界的一些朋友并不喜欢这个 “刚刚闯入” 开源界的 “小伙子”,判了它 “意义不大” 的死刑。“TensorFlow” 之所以 “开源” 却不讨好,是因为 TensorFlow 不是第一个被开源的深度学习系统,并且目前只开源了 “单机版”,而非能够识别猫的 “分布式版本”。除了并非第一以及只开源了单机版代码这两点外,Google 开源 TensorFlow 这件事最被人诟病的地方在于,在 “用事实”、“用数据” 说话的学术界、工程界,Google 并未用 “数据对比” 证明 TensorFlow 的 “灵活、更通用、易使用”。
对于 TensorFlow,出门问问的看法是,TensorFlow 对学术界意义不大,但是对工程界意义挺大。
深度 | 谷歌I/O走进TensorFlow开源模型世界:从图像识别到语义理解
机器之心原创
参与:吴攀、QW
一年一度的谷歌开发者大会 Google I/O 在山景城成功举行,在首日的,谷歌宣布了一系列新的硬件、应用、基础研究等。而作为 AI First 的开发者大会,Google I/O 也自然安排了许多有关机器学习开发的内容,比如《》。当然毋庸置疑,TensorFlow 也是本届 I/O 大会的关键核心之一。当地时间 18 日下午,谷歌 TensorFlow 开发者支持 Josh Gordon 带来了一场主题为《开源 TensorFlow 模型(Open Source TensorFlow Models)》的 Session,介绍了一些最流行的 TensorFlow 模型,并鼓励了开源。机器之心在本文中对这一 Session 进行了整理介绍,其中部分内容也提供了机器之心文章的参考链接,希望能为你的扩展阅读提供帮助。
演讲主题:你知道你可以使用 TensorFlow 来描述图像、理解文本和生成艺术作品吗?来这个演讲,你体验到 TensorFlow 在计算机视觉、自然语言处理和计算机艺术生成上的最新项目。我将分享每个领域内我最偏爱的项目、展示你可以在家尝试的实时演示以及分享你可以进一步学习的教育资源。这个演讲不需要特定的机器学习背景。
在进入正题之前,Gordon 先谈了谈他对可复现的研究(reproducible research)的看法。他说我们现在理所当然地认为我们可以使用深度学习做到很多事情。在 2005 年的时候,他用了 6 个月时间试图使用神经网络来做基本的图像分类——识别分辨细胞是否感染了疾病。虽然那时候已经有很多不错的软件库可用了,但他们仍然还是要手动编写许多神经网络代码。最后,六个月时间过去了,这些优秀工程师打造的网络才开始在二元分类任务上表现得足够好一点。
而今天,你再也不需要这么苦恼了。今天,一个优秀的 Python 开发者加一点 TensorFlow 背景知识,并且愿意使用开源的模型,那么仅需要几天时间就能实现远远超过之前 6 个月所能达到的效果。当然,这要归功于大学、公司、开发者等慷慨的分享,这也已经为我们的社会带来了很大的价值。
Gordon 举了一个例子说明。他说过去 8 个月有三种新的医学图像应用都依赖于一种被称为 Inception 的深度学习神经网络模型,这些应用都实现了非常卓越的表现,有望在人类的生命健康方面提供方便实用的帮助。机器之心对这三种应用都进行过深度报道,参阅:
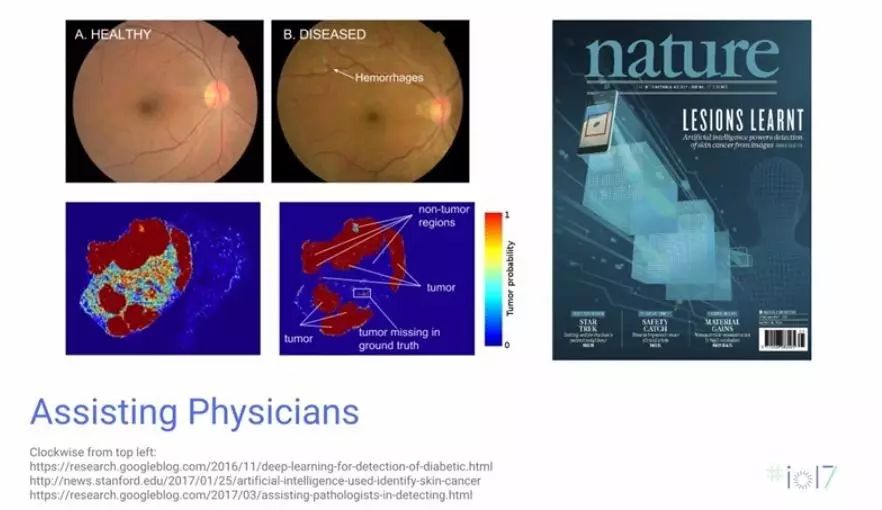
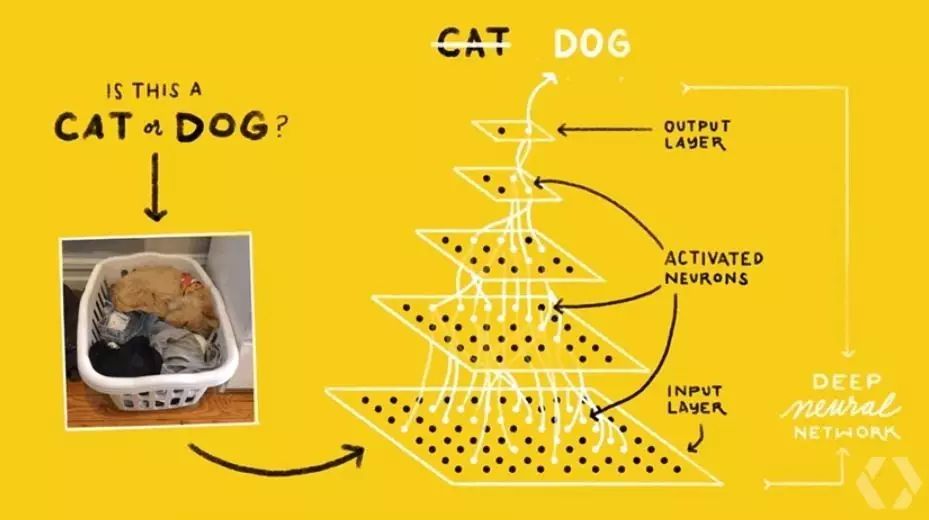
既然深度学习这么有用?那么深度学习是怎么工作的呢?首先我们先来看看一个可以将图像分类为「猫」或「狗」的模型。通过这个模型,我们可以看到深度学习与 Gordon 在 2005 年的工作有什么不同。
Gordon 解释说,在 2005 年时,为了开发图像分类器,他编写了 Python 代码来提取图像的特征。首先他需要构思这个图像分类器需要怎样的特征(比如:线、形状、颜色),甚至还可能需要 OpenCV 这样的库来做人脸检测。
而使用深度学习时,可以直接为模型输入原始像素,让模型自己去寻找分类所需的特征。「深度学习」之所以被称为「深度」,是因为它具有多个层,数据在这些层中进行处理,最后得到分类结果,更多介绍可参阅《》
TensorFlow 是由谷歌设计的一个深度学习框架,拥有很多优点,包括快速灵活可扩展的开源机器学习库、可用于研究和生产、可以运行在 CPU、GPU、TPU、安卓、iOS 和树莓派等硬件和系统上。

Gordon 将在这个演讲中为我们主要解读以下 4 个重要研究:

当然,一直关注深度学习研究前沿的机器之心也已经对这些研究进行过完整报道:
此外,Gordon 还提到了一些其它使用 TensorFlow 实现的研究成果;

你想的没错,机器之心依然报道过这些研究:
谷歌的这些研究中有一些仍然是当前最佳的,但他们仍然开源了相关的代码,任何人都可以免费尝试复现这些结果。那谷歌为什么还要开源呢?毕竟有的研究是非常具有商业价值的。Gordon 说:「一个重要的理由是可以激励别人继续推进你的想法。」同时,这也能帮助降低开发者的进入门槛,能让更多人参与进来。
要实现可复现的(reproducible)开源,你需要共享你的代码和数据集。代码方面,要做到可复现,你应该共享你所有的代码,包括训练、推理和验证的代码。数据集方面,你应该说明你所用的数据集,你对数据集的处理方式等等。最好能提供一个试用数据集(toy dataset),让人们可以轻松验证你的模型。
预训练的检查点(pretrained checkpoint)也很重要。pretrained checkpoint 是为了保存模型训练过程中一些列状态,这样其他研究者就可以完全复制之前的研究过程,从而避免被随机化(在深度学习中极为常见)等其他因素干扰。
Gordon 还谈到了 Docker。很多时候,你的开发环境需要大量的依赖包。通过共享一个 Docker 容器,你可以让其他人快速尝试你的想法。
开发深度学习模型,当然可以选择自己写代码。在 TensorFlow 中,你可以轻松编写代码,实现模型。这里给出了两个示例:
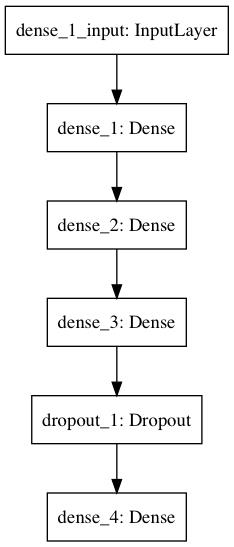
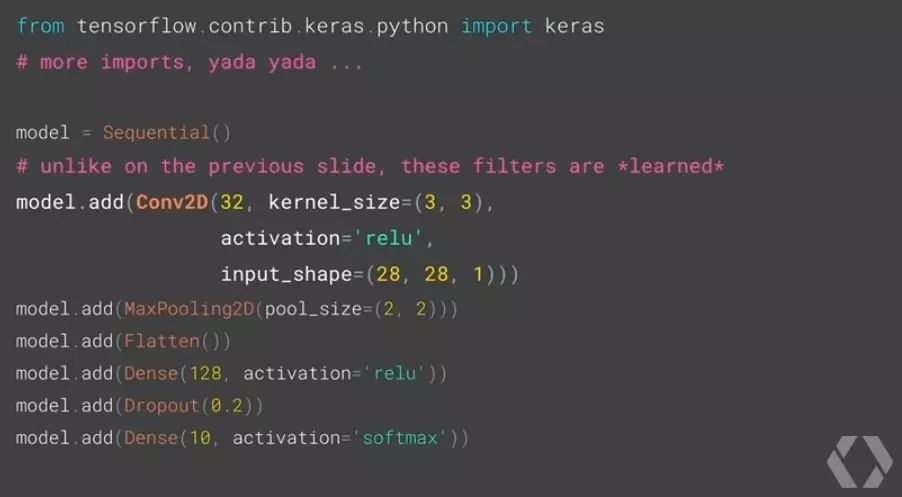
这段代码使用 Keras + TensorFlow 的组合。Keras 是用来构建神经网络的 API,它具有简单高效的特性,允许初学者轻松地建立神经网络模型;同时,Keras 也可以使用 TensorFlow 作为运行的后端,极大地加速了开发与训练的过程。
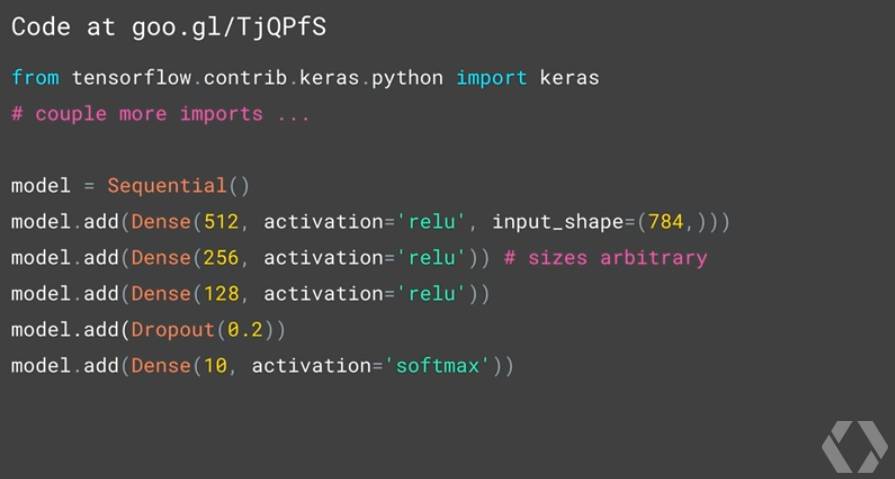
首先我们使用 Keras 中的 Sequential 类初始化一个用于存放任意层网络的模型,我们可以简单地认为这个类创建了一个杯子,我们的任务就是用适当的内容将这个杯子填满。接着在代码中不断地调用 add 方法按照顺序添加我们需要的神经网络层 (layer)。我们可以看到短短的几行代码便可以创建一个 MNIST 神经网络分类器。你只需要专注于以下几个方面:将数据按照神经网络的输入(代码中为一行 model.add(Dense(512, activation='relu', input_shape=(784,)))格式处理好,选择适当的激活函数(不仅是 relu,你也可以尝试 tanh 或是 softmax 来快速比较不同激活函数对神经网络结果的影响),是否添加 Dropout 层来减轻学习过程中的过拟合现象。
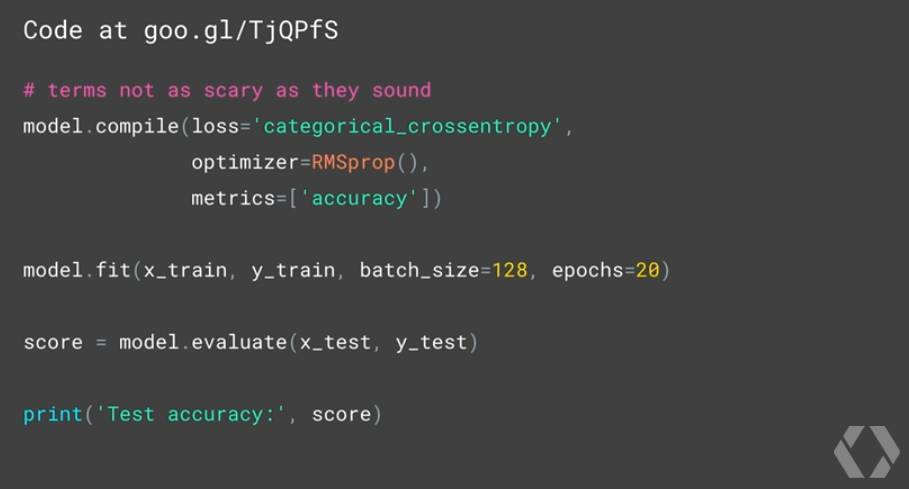
当模型构建好之后,我们便可以快速地使用 compile 方法来编译模型,其中的损失函数 loss、优化方法 optimizer 均可以自由选择。最后,使用类似于 sklearn 机器学习工具包中的 fit 方法即可开始训练我们的模型。
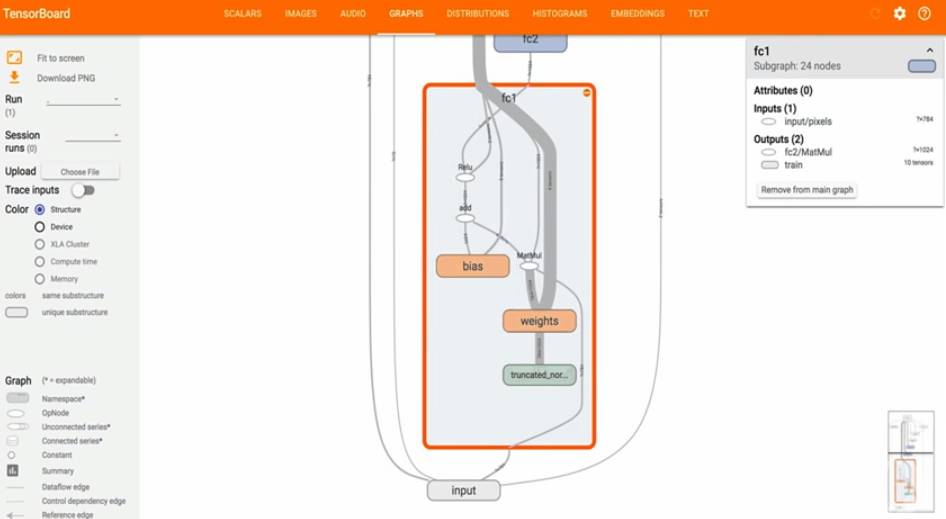
TensorFlow 有一个非常出色可视化工具 TensorBoard,可以协助你的开发。
除了自己动手开发,你也可以利用别人写好的代码,这也是开源的好处,也是本演讲所关注的重点。
Inception
Gordon 首先介绍的模型是 Inception。

Inception 的结构
比如如果你想识别一张照片,你可以直接在谷歌的云平台上直接调用该模型的 API 来帮你完成。当然,你可以通过使用开源模型的方式来实现:
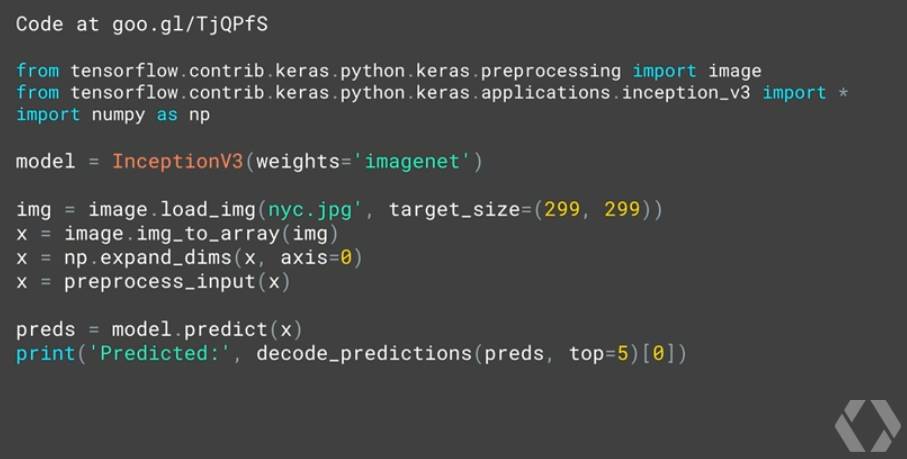
上面的这一点代码就实现了前面幻灯片上的 Inception 模型,可以看到,代码量非常少。

这是该模型在 Gordon 自己拍摄的一张照片上所得到的结果。效果不好,主要是因为这个模型所预训练的数据集来自于 ImageNet。ImageNet 中包含了大量的图像,但其中大部分都是猫、狗、花、艺术品等等,对上图照片的场景经验不足。

而有了合适的数据集,Inception 能得到非常好的表现,甚至能够分辨出狗的品种。
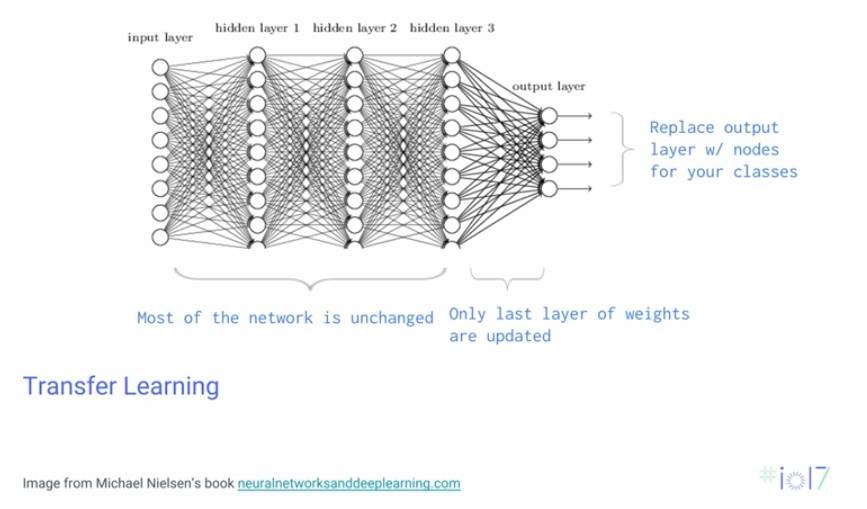
也许你对识别狗不感兴趣,但你也可以用深度学习做其它事情,比如迁移学习。迁移学习的概念很简单。举个例子,假如你已经训练好了一个可以识别狗的模型,但你想要识别上面照片中的城市。如果有迁移学习,你就不需要从头开始在新数据集上训练你的模型,你可以去掉你原来模型的最后一层,然后换上新的一层再训练。这样就能将原来需要数周的训练时间减省到了几十秒。
TensorFlow for Poets 展示这样实现图像模型的方式。希望在更多领域看到这样的例子。实际上,在 https://github.com/tensorflow/models 中,有很多模型公开可用。
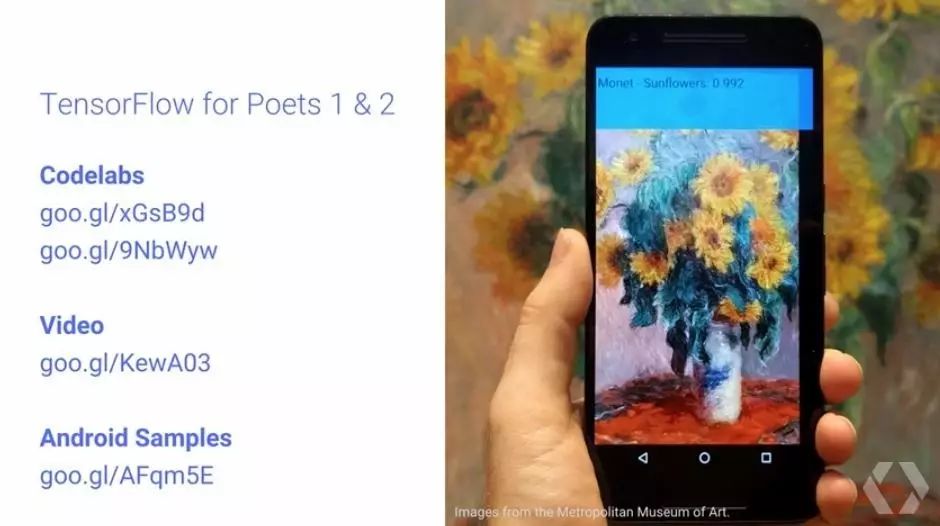
你也可以设计你自己的实验:

接下来,Gordon 对大名鼎鼎的 Deep Dream 进行了介绍。参阅机器之心文章《》。

Deep Dream 何以成为可能。Gordon 解释说,一是因为数据和计算机计算能力的极大增长,而是因为人们设计出了更加有效的算法,三是这些算法能自动学习到合适的特征(feature)。
要提取出图像的特征,我们需要用到卷积。卷积就像是一个滤波器。比如下图,左边是一张曼哈顿的照片,中间是一个 3×3 的滤波器,右边是处理后的图像,只能大概看到一些建筑的边。
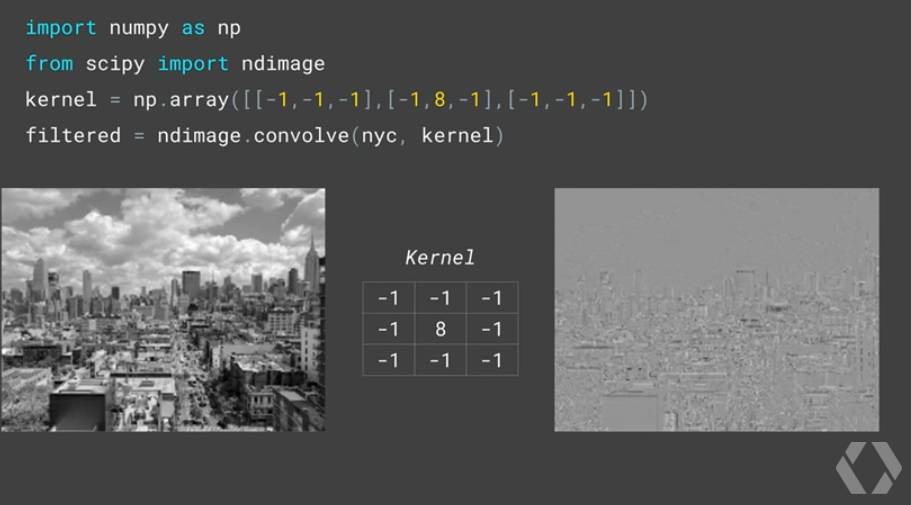
随着层数的增多,模型识别出的特征会越来越高级:

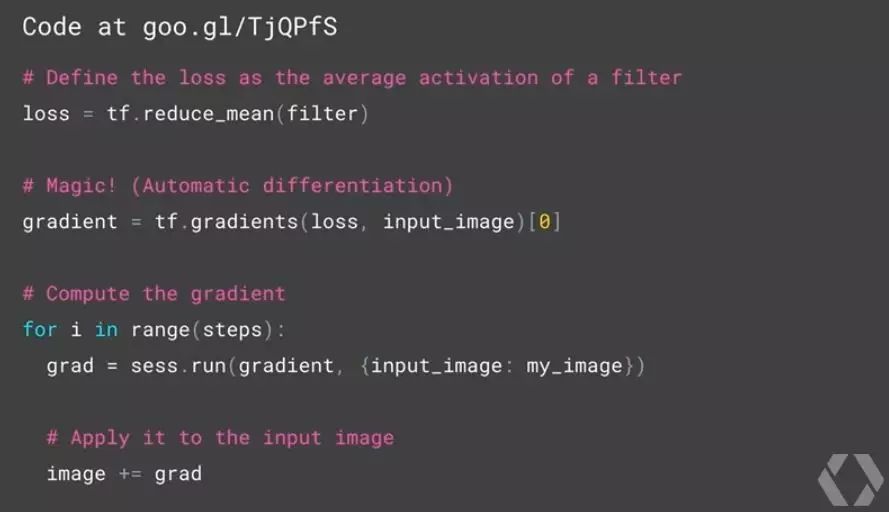
如果你查看 Deep Dream 的代码,你会看到很多,下面给出了其中一些关键的代码:首先我们从卷积神经网络中的某一层中选出一些列 filter(不同的 filter 会包含是分不同的特征:如猫、狗、甚至是梵高的向日葵,这取决于你用什么内容来训练),接着利用这些 filter 定义好损失函数,不断地利用 TensorFlow 中自动求导的功能更新原先的图片。通过这几行代码,我们委托 TensorFlow 不断地找出原始图片中的一些区域(这些区域的特征恰好与某些 filter 匹配),接着 TensorFlow 利用 filter 的信息来修改原始的图片从而生成 DeepDream 的效果。
使用深度学习,你还能做风格迁移。对此 Gordon 并未做太多介绍,感兴趣的读者可参阅《》。在这里,Gordon 顺带提及了一下 Magenta,参阅《
风格迁移即是将一张艺术画作的风格应用到一张照片的内容上,处理流程如下所示:
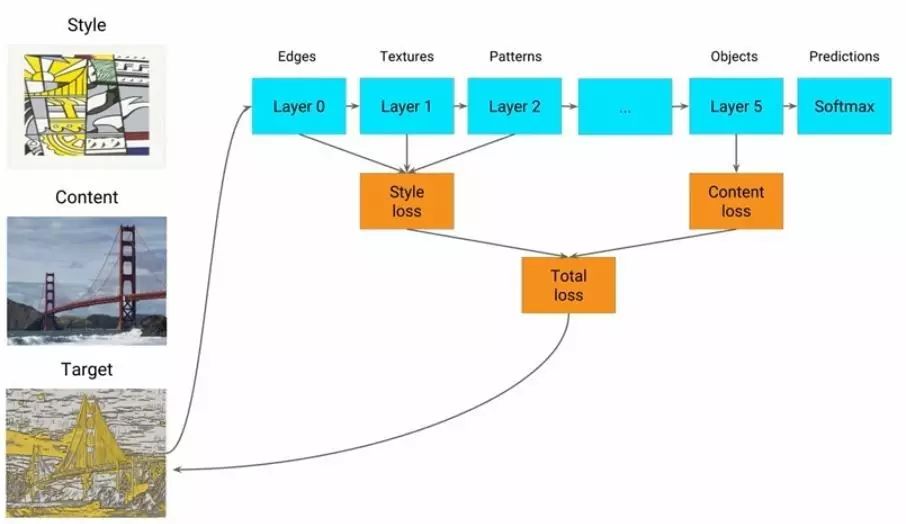
而且值得注意的是,现在你已经可以实时地给视频执行风格迁移了!
语言
语言也是一个非常重要的领域。Gordon 将为我们讲解 SyntaxNet 系列,其中最新的是 Parsey Saurus,这也是目前最准确的文本处理器之一。同样,这也是开源的,可以通过 TensorFlow 使用。那么模型是怎么处理文本的呢?Gordon 用例子进行了说明。
假设有一个句子「I love NYC.」你可以使用谷歌云的自然语言 API 来对这个句子进行处理,可以拖拽式地操作。
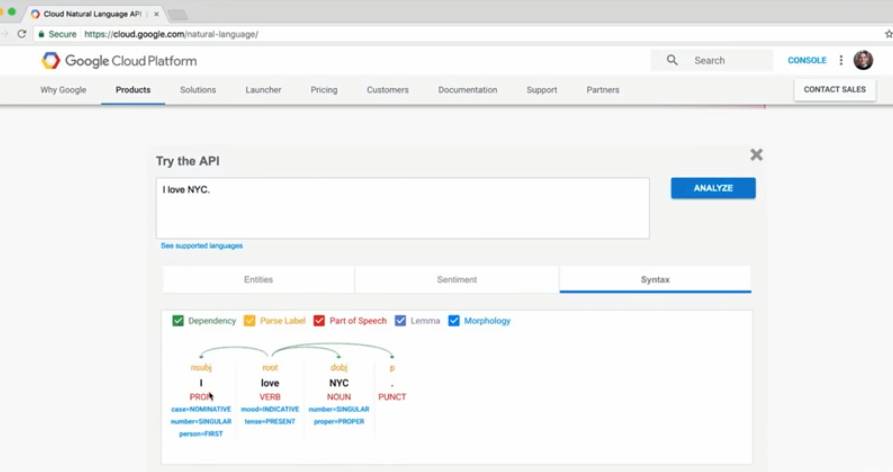
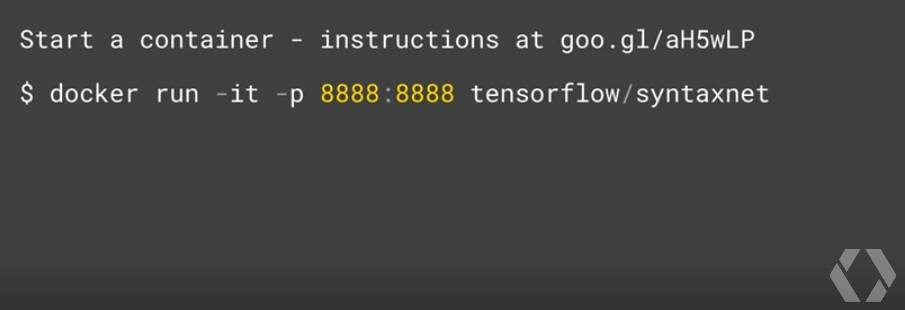
当然,你也可以在 TensorFlow 中使用 Docker 安装环境,快速地尝试 SyntaxNet:
还记得去年的 Parsey McParseface,那是当时最先进的自然语言处理模型,而现在 Parsey Saurus 已经超越了它。这两者的区别在于 Parsey McParseface 是在词层面上工作的,而 Parsey Saurus 则是工作在字符的层面上。在字符层面上的学习允许模型更加精细的处理文字,例如可以学习到词素这样最小单位的语言信息或是更好地处理生僻的字词。
使用这些模型,你甚至可以像人一样分析没有实际意义语句的结构,比如:「The gostak distims the doshes.」这个句子是毫无意义的,但我们却能够理解这个句子的结构。比如说,我们能够轻松理解其中各个词的词性,比如我们知道 distims 是动词,而 gostak 和 doshes 则是名词。
在 syntaxnet container 中,使用 Interactive Text Analyzer 也能得到同样的结论。
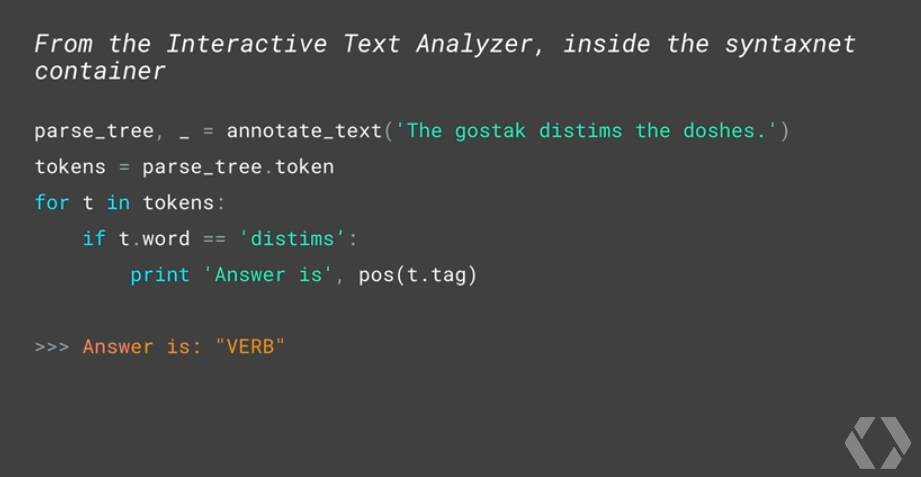
你也可以询问 distims 这个动作的执行者是什么?
Parsey Saurus 还能告诉你更多:
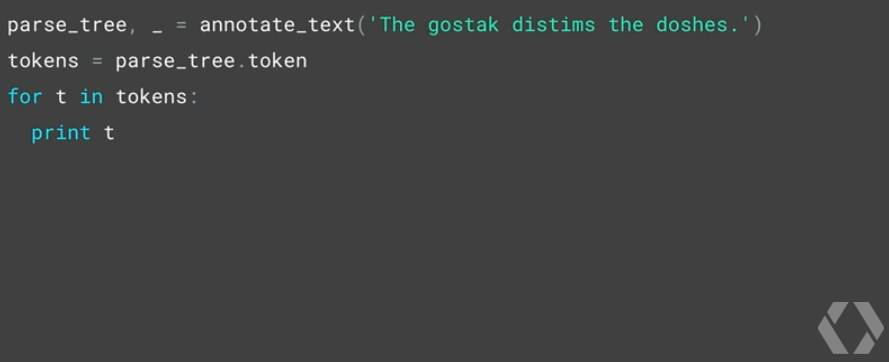
下面列出了对该句子的一些分析结果:

也可以得到该句子的依存树:
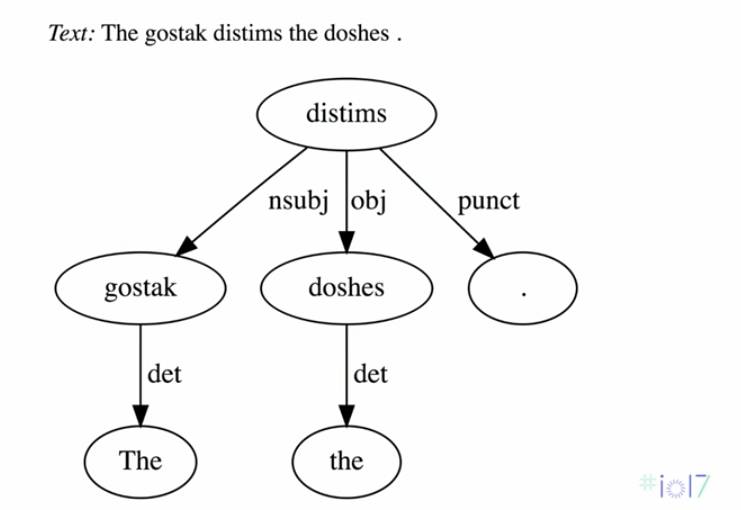
除此之外,你还可以下载在不同语言(40 多种)上预训练过的模型。这正是开源的价值。
这个有很多非常好的用例。

如果有一个已有的系统,你可以更轻松地在这之上实现提升。
你可以将其用作一个新系统的基础。让你不需要再重头开始训练,就能获得已有的词性标注等功能。
然后,Gordon 又简单介绍了 Release++ 的概念。这个概念来自 Magenta 的博客,表示他们不仅共享了自己的代码,还提供了预训练的模型和 Docker 容器。也就是说,你可以直接使用他们的模型达到同样的效果。

开源为 TensorFlow 带来的一大优势是其具有非常多的学习资源,包括许多课程、博客、教程,你可以访问其官网查阅。另外,这里 Gordon 推荐了几个值得关注的:
点击阅读原文,查看全部嘉宾阵容并报名参与机器之心 GMIS 2017 ↓↓↓
以上是关于谷歌开源了TensorFlow,世界就要马上被改变了吗的主要内容,如果未能解决你的问题,请参考以下文章
业界 | 谷歌正式发布TensorFlow 1.5:终于支持CUDA 9和cuDNN 7
谷歌正式发布 TensorFlow 1.5,终于支持 CUDA9 和 cuDNN7