常见的tcp拥塞控制有哪几种算法
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了常见的tcp拥塞控制有哪几种算法相关的知识,希望对你有一定的参考价值。
慢启动:最初的TCP在连接建立成功后会向网络中发送大量的数据包,这样很容易导致网络中路由器缓存空间耗尽,从而发生拥塞。因此新建立的连接不能够一开始就大量发送数据包,而只能根据网络情况逐步增加每次发送的数据量,以避免上述现象的发生。具体来说,当新建连接时,cwnd初始化为1个最大报文段(MSS)大小,发送端开始按照拥塞窗口大小发送数据,每当有一个报文段被确认,cwnd就增加1个MSS大小。这样cwnd的值就随着网络往返时间(Round Trip Time,RTT)呈指数级增长,事实上,慢启动的速度一点也不慢,只是它的起点比较低一点而已。我们可以简单计算下:开始 ---> cwnd = 1
经过1个RTT后 ---> cwnd = 2*1 = 2
经过2个RTT后 ---> cwnd = 2*2= 4
经过3个RTT后 ---> cwnd = 4*2 = 8
如果带宽为W,那么经过RTT*log2W时间就可以占满带宽。
拥塞避免:从慢启动可以看到,cwnd可以很快的增长上来,从而最大程度利用网络带宽资源,但是cwnd不能一直这样无限增长下去,一定需要某个限制。TCP使用了一个叫慢启动门限(ssthresh)的变量,当cwnd超过该值后,慢启动过程结束,进入拥塞避免阶段。对于大多数TCP实现来说,ssthresh的值是65536(同样以字节计算)。拥塞避免的主要思想是加法增大,也就是cwnd的值不再指数级往上升,开始加法增加。此时当窗口中所有的报文段都被确认时,cwnd的大小加1,cwnd的值就随着RTT开始线性增加,这样就可以避免增长过快导致网络拥塞,慢慢的增加调整到网络的最佳值。
上面讨论的两个机制都是没有检测到拥塞的情况下的行为,那么当发现拥塞了cwnd又该怎样去调整呢?
首先来看TCP是如何确定网络进入了拥塞状态的,TCP认为网络拥塞的主要依据是它重传了一个报文段。上面提到过,TCP对每一个报文段都有一个定时器,称为重传定时器(RTO),当RTO超时且还没有得到数据确认,那么TCP就会对该报文段进行重传,当发生超时时,那么出现拥塞的可能性就很大,某个报文段可能在网络中某处丢失,并且后续的报文段也没有了消息,在这种情况下,TCP反应比较“强烈”:
1.把ssthresh降低为cwnd值的一半
2.把cwnd重新设置为1
3.重新进入慢启动过程。
从整体上来讲,TCP拥塞控制窗口变化的原则是AIMD原则,即加法增大、乘法减小。可以看出TCP的该原则可以较好地保证流之间的公平性,因为一旦出现丢包,那么立即减半退避,可以给其他新建的流留有足够的空间,从而保证整个的公平性。
其实TCP还有一种情况会进行重传:那就是收到3个相同的ACK。TCP在收到乱序到达包时就会立即发送ACK,TCP利用3个相同的ACK来判定数据包的丢失,此时进行快速重传,快速重传做的事情有:
1.把ssthresh设置为cwnd的一半
2.把cwnd再设置为ssthresh的值(具体实现有些为ssthresh+3)
3.重新进入拥塞避免阶段。
后来的“快速恢复”算法是在上述的“快速重传”算法后添加的,当收到3个重复ACK时,TCP最后进入的不是拥塞避免阶段,而是快速恢复阶段。快速重传和快速恢复算法一般同时使用。快速恢复的思想是“数据包守恒”原则,即同一个时刻在网络中的数据包数量是恒定的,只有当“老”数据包离开了网络后,才能向网络中发送一个“新”的数据包,如果发送方收到一个重复的ACK,那么根据TCP的ACK机制就表明有一个数据包离开了网络,于是cwnd加1。如果能够严格按照该原则那么网络中很少会发生拥塞,事实上拥塞控制的目的也就在修正违反该原则的地方。
具体来说快速恢复的主要步骤是:
1.当收到3个重复ACK时,把ssthresh设置为cwnd的一半,把cwnd设置为ssthresh的值加3,然后重传丢失的报文段,加3的原因是因为收到3个重复的ACK,表明有3个“老”的数据包离开了网络。
2.再收到重复的ACK时,拥塞窗口增加1。
3.当收到新的数据包的ACK时,把cwnd设置为第一步中的ssthresh的值。原因是因为该ACK确认了新的数据,说明从重复ACK时的数据都已收到,该恢复过程已经结束,可以回到恢复之前的状态了,也即再次进入拥塞避免状态。
快速重传算法首次出现在4.3BSD的Tahoe版本,快速恢复首次出现在4.3BSD的Reno版本,也称之为Reno版的TCP拥塞控制算法。
可以看出Reno的快速重传算法是针对一个包的重传情况的,然而在实际中,一个重传超时可能导致许多的数据包的重传,因此当多个数据包从一个数据窗口中丢失时并且触发快速重传和快速恢复算法时,问题就产生了。因此NewReno出现了,它在Reno快速恢复的基础上稍加了修改,可以恢复一个窗口内多个包丢失的情况。具体来讲就是:Reno在收到一个新的数据的ACK时就退出了快速恢复状态了,而NewReno需要收到该窗口内所有数据包的确认后才会退出快速恢复状态,从而更一步提高吞吐量。
SACK就是改变TCP的确认机制,最初的TCP只确认当前已连续收到的数据,SACK则把乱序等信息会全部告诉对方,从而减少数据发送方重传的盲目性。比如说序号1,2,3,5,7的数据收到了,那么普通的ACK只会确认序列号4,而SACK会把当前的5,7已经收到的信息在SACK选项里面告知对端,从而提高性能,当使用SACK的时候,NewReno算法可以不使用,因为SACK本身携带的信息就可以使得发送方有足够的信息来知道需要重传哪些包,而不需要重传哪些包。 参考技术A 为
了防止网络的拥塞现象,TCP提出了一系列的拥塞控制机制。最初由V. Jacobson在1988年的论文中提出的TCP的拥塞控制由“慢启动
(Slow start)”和“拥塞避免(Congestion avoidance)”组成,后来TCP Reno版本中又针对性的加入了“快速重传
(Fast retransmit)”、“快速恢复(Fast Recovery)”算法,再后来在TCP NewReno中又对“快速恢复”算法进行了
改进,近些年又出现了选择性应答( selective acknowledgement,SACK)算法,还有其他方面的大大小小的改进,成为网络研究
的一个热点。
TCP的
拥塞控制主要原理依赖于一个拥塞窗口(cwnd)来控制,在之前我们还讨论过TCP还有一个对端通告的接收窗口(rwnd)用于流量控制。窗口值的大小就
代表能够发送出去的但还没有收到ACK的最大数据报文段,显然窗口越大那么数据发送的速度也就越快,但是也有越可能使得网络出现拥塞,如果窗口值为1,那
么就简化为一个停等协议,每发送一个数据,都要等到对方的确认才能发送第二个数据包,显然数据传输效率低下。TCP的拥塞控制算法就是要在这两者之间权
衡,选取最好的cwnd值,从而使得网络吞吐量最大化且不产生拥塞。
由
于需要考虑拥塞控制和流量控制两个方面的内容,因此TCP的真正的发送窗口=min(rwnd, cwnd)。但是rwnd是由对端确定的,网络环境对其
没有影响,所以在考虑拥塞的时候我们一般不考虑rwnd的值,我们暂时只讨论如何确定cwnd值的大小。关于cwnd的单位,在TCP中是以字节来做单位
的,我们假设TCP每次传输都是按照MSS大小来发送数据的,因此你可以认为cwnd按照数据包个数来做单位也可以理解,所以有时我们说cwnd增加1也
就是相当于字节数增加1个MSS大小。
慢
启动:最初的TCP在连接建立成功后会向网络中发送大量的数据包,这样很容易导致网络中路由器缓存空间耗尽,从而发生拥塞。因此新建立的连接不能够一开始
就大量发送数据包,而只能根据网络情况逐步增加每次发送的数据量,以避免上述现象的发生。具体来说,当新建连接时,cwnd初始化为1个最大报文段
(MSS)大小,发送端开始按照拥塞窗口大小发送数据,每当有一个报文段被确认,cwnd就增加1个MSS大小。这样cwnd的值就随着网络往返时间
(Round Trip Time,RTT)呈指数级增长,事实上,慢启动的速度一点也不慢,只是它的起点比较低一点而已。我们可以简单计算下:
开始 ---> cwnd = 1
经过1个RTT后 ---> cwnd = 2*1 = 2
经过2个RTT后 ---> cwnd = 2*2= 4
经过3个RTT后 ---> cwnd = 4*2 = 8
如果带宽为W,那么经过RTT*log2W时间就可以占满带宽。
拥
塞避免:从慢启动可以看到,cwnd可以很快的增长上来,从而最大程度利用网络带宽资源,但是cwnd不能一直这样无限增长下去,一定需要某个限制。
TCP使用了一个叫慢启动门限(ssthresh)的变量,当cwnd超过该值后,慢启动过程结束,进入拥塞避免阶段。对于大多数TCP实现来
说,ssthresh的值是65536(同样以字节计算)。拥塞避免的主要思想是加法增大,也就是cwnd的值不再指数级往上升,开始加法增加。此时当窗
口中所有的报文段都被确认时,cwnd的大小加1,cwnd的值就随着RTT开始线性增加,这样就可以避免增长过快导致网络拥塞,慢慢的增加调整到网络的
最佳值。
上面讨论的两个机制都是没有检测到拥塞的情况下的行为,那么当发现拥塞了cwnd又该怎样去调整呢?
首
先来看TCP是如何确定网络进入了拥塞状态的,TCP认为网络拥塞的主要依据是它重传了一个报文段。上面提到过,TCP对每一个报文段都有一个定时器,称
为重传定时器(RTO),当RTO超时且还没有得到数据确认,那么TCP就会对该报文段进行重传,当发生超时时,那么出现拥塞的可能性就很大,某个报文段
可能在网络中某处丢失,并且后续的报文段也没有了消息,在这种情况下,TCP反应比较“强烈”:
1.把ssthresh降低为cwnd值的一半
2.把cwnd重新设置为1
3.重新进入慢启动过程。
从整体上来讲,TCP拥塞控制窗口变化的原则是AIMD原则,即加法增大、乘法减小。可以看出TCP的该原则可以较好地保证流之间的公平性,因为一旦出现丢包,那么立即减半退避,可以给其他新建的流留有足够的空间,从而保证整个的公平性。
其实TCP还有一种情况会进行重传:那就是收到3个相同的ACK。TCP在收到乱序到达包时就会立即发送ACK,TCP利用3个相同的ACK来判定数据包的丢失,此时进行快速重传,快速重传做的事情有:
1.把ssthresh设置为cwnd的一半
2.把cwnd再设置为ssthresh的值(具体实现有些为ssthresh+3)
3.重新进入拥塞避免阶段。
后
来的“快速恢复”算法是在上述的“快速重传”算法后添加的,当收到3个重复ACK时,TCP最后进入的不是拥塞避免阶段,而是快速恢复阶段。快速重传和快
速恢复算法一般同时使用。快速恢复的思想是“数据包守恒”原则,即同一个时刻在网络中的数据包数量是恒定的,只有当“老”数据包离开了网络后,才能向网络
中发送一个“新”的数据包,如果发送方收到一个重复的ACK,那么根据TCP的ACK机制就表明有一个数据包离开了网络,于是cwnd加1。如果能够严格
按照该原则那么网络中很少会发生拥塞,事实上拥塞控制的目的也就在修正违反该原则的地方。
具体来说快速恢复的主要步骤是:
1.当收到3个重复ACK时,把ssthresh设置为cwnd的一半,把cwnd设置为ssthresh的值加3,然后重传丢失的报文段,加3的原因是因为收到3个重复的ACK,表明有3个“老”的数据包离开了网络。
2.再收到重复的ACK时,拥塞窗口增加1。
3.当收到新的数据包的ACK时,把cwnd设置为第一步中的ssthresh的值。原因是因为该ACK确认了新的数据,说明从重复ACK时的数据都已收到,该恢复过程已经结束,可以回到恢复之前的状态了,也即再次进入拥塞避免状态。
快速重传算法首次出现在4.3BSD的Tahoe版本,快速恢复首次出现在4.3BSD的Reno版本,也称之为Reno版的TCP拥塞控制算法。
可
以看出Reno的快速重传算法是针对一个包的重传情况的,然而在实际中,一个重传超时可能导致许多的数据包的重传,因此当多个数据包从一个数据窗口中丢失
时并且触发快速重传和快速恢复算法时,问题就产生了。因此NewReno出现了,它在Reno快速恢复的基础上稍加了修改,可以恢复一个窗口内多个包丢失
的情况。具体来讲就是:Reno在收到一个新的数据的ACK时就退出了快速恢复状态了,而NewReno需要收到该窗口内所有数据包的确认后才会退出快速
恢复状态,从而更一步提高吞吐量。
SACK就
是改变TCP的确认机制,最初的TCP只确认当前已连续收到的数据,SACK则把乱序等信息会全部告诉对方,从而减少数据发送方重传的盲目性。比如说序号
1,2,3,5,7的数据收到了,那么普通的ACK只会确认序列号4,而SACK会把当前的5,7已经收到的信息在SACK选项里面告知对端,从而提高性
能,当使用SACK的时候,NewReno算法可以不使用,因为SACK本身携带的信息就可以使得发送方有足够的信息来知道需要重传哪些包,而不需要重传
哪些包。本回答被提问者和网友采纳
TCP拥塞控制算法
本篇文章介绍了几种经典的TCP拥塞控制算法,包括算法原理及各自适用场景。
回顾上篇文章:浅谈 redis 延迟
前言
TCP 通过维护一个拥塞窗口来进行拥塞控制,拥塞控制的原则是,只要网络中没有出现拥塞,拥塞窗口的值就可以再增大一些,以便把更多的数据包发送出去,但只要网络出现拥塞,拥塞窗口的值就应该减小一些,以减少注入到网络中的数据包数。
TCP 拥塞控制算法发展的过程中出现了如下几种不同的思路:
-
基于丢包的拥塞控制:将丢包视为出现拥塞,采取缓慢探测的方式,逐渐增大拥塞窗口,当出现丢包时,将拥塞窗口减小,如 Reno、Cubic 等。
-
基于时延的拥塞控制:将时延增加视为出现拥塞,延时增加时增大拥塞窗口,延时减小时减小拥塞窗口,如 Vegas、FastTCP 等。
-
基于链路容量的拥塞控制:实时测量网络带宽和时延,认为网络上报文总量大于带宽时延乘积时出现了拥塞,如 BBR。
-
基于学习的拥塞控制:没有特定的拥塞信号,而是借助评价函数,基于训练数据,使用机器学习的方法形成一个控制策略,如 Remy。
拥塞控制算法的核心是选择一个有效的策略来控制拥塞窗口的变化,下面介绍几种经典的拥塞控制算法。
Vegas
Vegas[1] 将时延 RTT 的增加作为网络出现拥塞的信号,RTT 增加,拥塞窗口减小,RTT 减小,拥塞窗口增加。具体来说,Vegas 通过比较实际吞吐量和期望吞吐量来调节拥塞窗口的大小,
期望吞吐量:Expected = cwnd / BaseRTT,
实际吞吐量:Actual = cwnd / RTT,
diff = (Expected-Actual) * BaseRTT,
BaseRTT 是所有观测来回响应时间的最小值,一般是建立连接后所发的第一个数据包的 RTT,cwnd 是目前的拥塞窗口的大小。Vegas 定义了两个阈值 a,b,当 diff > b 时,拥塞窗口减小,当 a <= diff <=b 时,拥塞窗口不变,当 diff < a 时,拥塞窗口增加。
Vegas 算法采用 RTT 的改变来判断网络的可用带宽,能精确地测量网络的可用带宽,效率比较好。但是,网络中 Vegas 与其它算法共存的情况下,基于丢包的拥塞控制算法会尝试填满网络中的缓冲区,导致 Vegas 计算的 RTT 增大,进而降低拥塞窗口,使得传输速度越来越慢,因此 Vegas 未能在 Internet 上普遍采用。
适用场景:
适用于网络中只存在 Vegas 一种拥塞控制算法,竞争公平的情况。
Reno
Reno[2] 将拥塞控制的过程分为四个阶段:慢启动、拥塞避免、快重传和快恢复,是现有的众多拥塞控制算法的基础,下面详细说明这几个阶段。
慢启动阶段,在没有出现丢包时每收到一个 ACK 就将拥塞窗口大小加一(单位是 MSS,最大单个报文段长度),每轮次发送窗口增加一倍,呈指数增长,若出现丢包,则将拥塞窗口减半,进入拥塞避免阶段;当窗口达到慢启动阈值或出现丢包时,进入拥塞避免阶段,窗口每轮次加一,呈线性增长;当收到对一个报文的三个重复的 ACK 时,认为这个报文的下一个报文丢失了,进入快重传阶段,立即重传丢失的报文,而不是等待超时重传;快重传完成后进入快恢复阶段,将慢启动阈值修改为当前拥塞窗口值的一半,同时拥塞窗口值等于慢启动阈值,然后进入拥塞避免阶段,重复上诉过程。Reno 拥塞控制过程如图 1 所示。
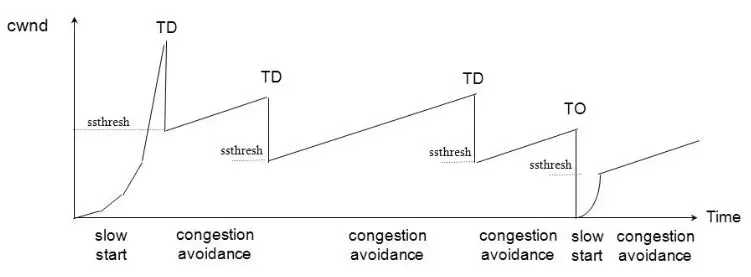
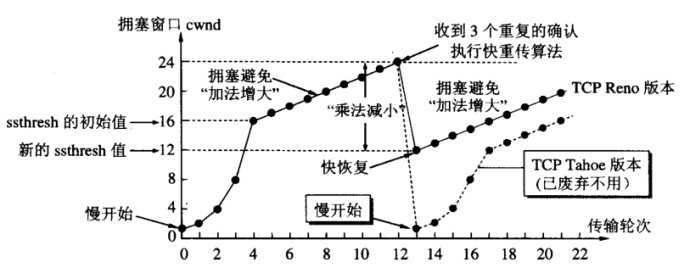
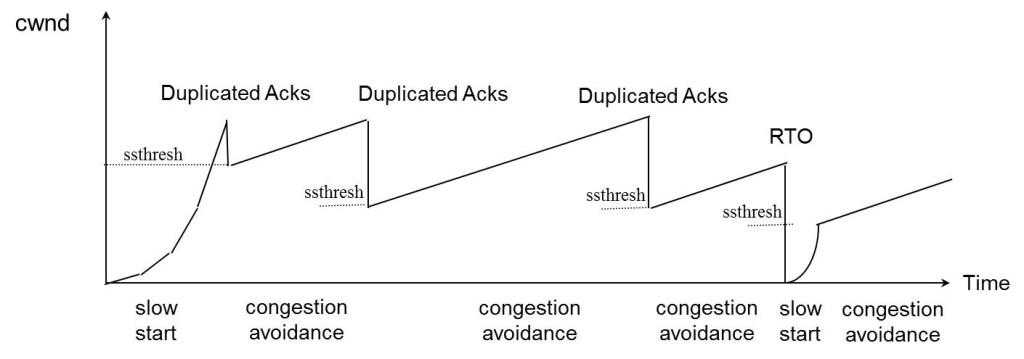
图 1、TCP Reno 拥塞控制过程
Reno 算法将收到 ACK 这一信号作为拥塞窗口增长的依据,在早期低带宽、低时延的网络中能够很好的发挥作用,但是随着网络带宽和延时的增加,Reno 的缺点就渐渐体现出来了,发送端从发送报文到收到 ACK 经历一个 RTT,在高带宽延时(High Bandwidth-Delay Product,BDP)网络中,RTT 很大,导致拥塞窗口增长很慢,传输速度需要经过很长时间才能达到最大带宽,导致带宽利用率将低。
适用场景:
适用于低延时、低带宽的网络。
Cubic
Cubic[3] 是 Linux 内核 2.6 之后的默认 TCP 拥塞控制算法,使用一个立方函数(cubic function)
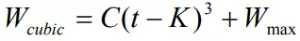
作为拥塞窗口的增长函数,其中,C 是调节因子,t 是从上一次缩小拥塞窗口经过的时间,Wmax 是上一次发生拥塞时的窗口大小,
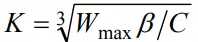
β是乘法减小因子。从函数中可以看出拥塞窗口的增长不再与 RTT 有关,而仅仅取决上次发生拥塞时的最大窗口和距离上次发生拥塞的时间间隔值。
Cubic 拥塞窗口增长曲线如下,凸曲线部分为稳定增长阶段,凹曲线部分为最大带宽探测阶段。如图 2 所示,在刚开始时,拥塞窗口增长很快,在接近 Wmax 口时,增长速度变的平缓,避免流量突增而导致丢包;在 Wmax 附近,拥塞窗口不再增加;之后开始缓慢地探测网络最大吞吐量,保证稳定性(在 Wmax 附近容易出现拥塞),在远离 Wmax 后,增大窗口增长的速度,保证了带宽的利用率。
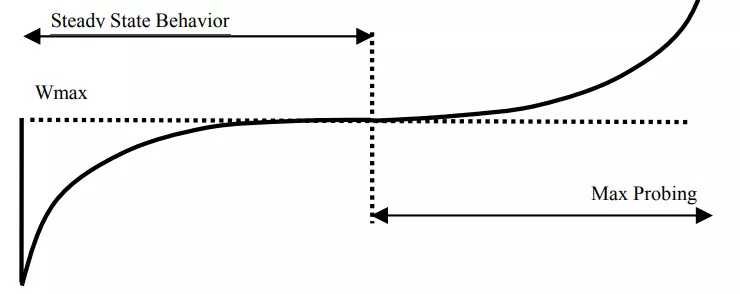
图 2、TCP Cubic 拥塞窗口增长函数
当出现丢包时,将拥塞窗口进行乘法减小,再继续开始上述增长过程。此方式可以使得拥塞窗口一直维持在 Wmax 附近,从而保证了带宽的利用率。Cubic 的拥塞控制过程如图 3 所示:
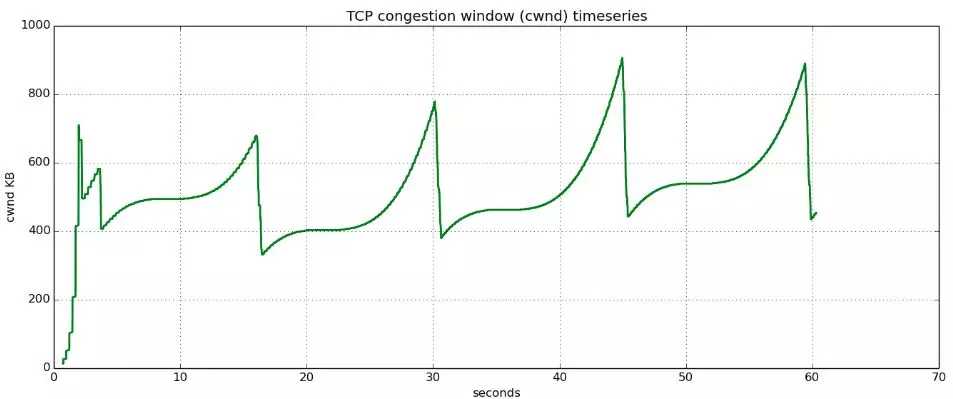
图 3、TCP Cubic 拥塞控制过程
Cubic 算法的优点在于只要没有出现丢包,就不会主动降低自己的发送速度,可以最大程度的利用网络剩余带宽,提高吞吐量,在高带宽、低丢包率的网络中可以发挥较好的性能。
但是,Cubic 同之前的拥塞控制算法一样,无法区分拥塞丢包和传输错误丢包,只要发现丢包,就会减小拥塞窗口,降低发送速率,而事实上传输错误丢包时网络不一定发生了拥塞,但是传输错误丢包的概率很低,所以对 Cubic 算法的性能影响不是很大。
Cubic 算法的另一个不足之处是过于激进,在没有出现丢包时会不停地增加拥塞窗口的大小,向网络注入流量,将网络设备的缓冲区填满,出现 Bufferbloat(缓冲区膨胀)。由于缓冲区长期趋于饱和状态,新进入网络的的数据包会在缓冲区里排队,增加无谓的排队时延,缓冲区越大,时延就越高。另外 Cubic 算法在高带宽利用率的同时依然在增加拥塞窗口,间接增加了丢包率,造成网络抖动加剧。
适用场景:
适用于高带宽、低丢包率网络,能够有效利用带宽。
BBR
BBR[4] 是谷歌在 2016 年提出的一种新的拥塞控制算法,已经在 Youtube 服务器和谷歌跨数据中心广域网上部署,据 Youtube 官方数据称,部署 BBR 后,在全球范围内访问 Youtube 的延迟降低了 53%,在时延较高的发展中国家,延迟降低了 80%。目前 BBR 已经集成到 Linux 4.9 以上版本的内核中。
BBR 算法不将出现丢包或时延增加作为拥塞的信号,而是认为当网络上的数据包总量大于瓶颈链路带宽和时延的乘积时才出现了拥塞,所以 BBR 也称为基于拥塞的拥塞控制算法(Congestion-Based Congestion Control)。BBR 算法周期性地探测网络的容量,交替测量一段时间内的带宽极大值和时延极小值,将其乘积作为作为拥塞窗口大小(交替测量的原因是极大带宽和极小时延不可能同时得到,带宽极大时网络被填满造成排队,时延必然极大,时延极小时需要数据包不被排队直接转发,带宽必然极小),使得拥塞窗口始的值始终与网络的容量保持一致。
由于 BBR 的拥塞窗口是精确测量出来的,不会无限的增加拥塞窗口,也就不会将网络设备的缓冲区填满,避免了出现 Bufferbloat 问题,使得时延大大降低。如图 4 所示,网络缓冲区被填满时时延为 250ms,Cubic 算法会继续增加拥塞窗口,使得时延持续增加到 500ms 并出现丢包,整个过程 Cubic 一直处于高时延状态,而 BBR 由于不会填满网络缓冲区,时延一直处于较低状态。
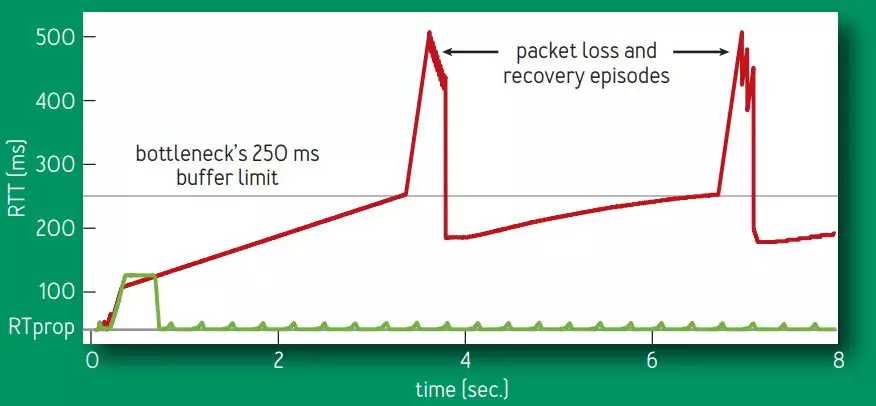
图 4、Cubic 和 BBR RTT 对比
由于 BBR 算法不将丢包作为拥塞信号,所以在丢包率较高的网络中,BBR 依然有极高的吞吐量,如图 5 所示,在 1% 丢包率的网络环境下,Cubic 的吞吐量已经降低 90% 以上,而 BBR 的吞吐量几乎没有受到影响,当丢包率大于 15% 时,BBR 的吞吐量才大幅下降。
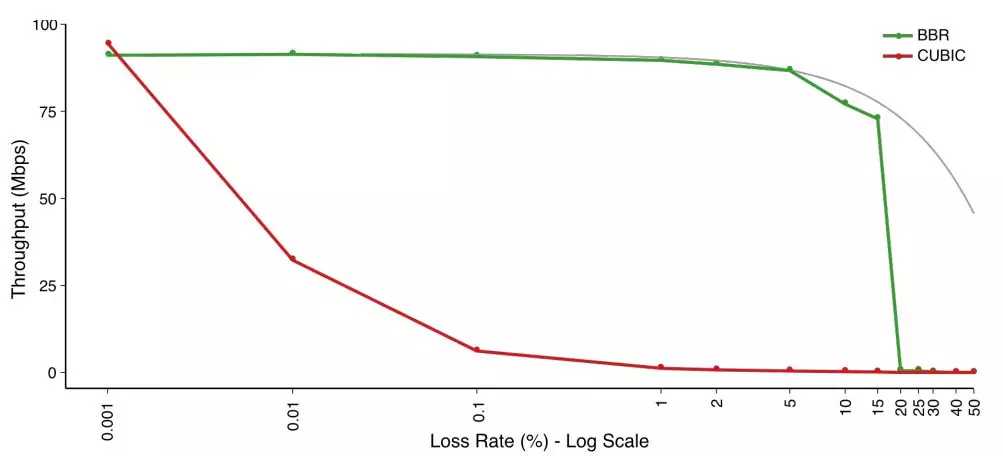
图 5、Cubic 和 BBR 传输速率与丢包率关系对比
BBR 算法是反馈驱动的,有自主调节机制,不受 TCP 拥塞控制状态机的控制,通过测量网络容量来调整拥塞窗口,发送速率由自己掌控,而传统的拥塞控制算法只负责计算拥塞窗口,而不管发送速率(pacing rate),怎么发由 TCP 自己决定,这样会在瓶颈带宽附近因发送速率的激增导致数据包排队或出现丢包。
经过测试,在高延时、高丢包率的环境下,BBR 相对于 Cubic 算法在传输速度上有较大的提升,具体的测试结果表 1 所示:
表1 200ms 延时下 Cubic 与 BBR 传输速度对比

BBR 算法的不足之处在于设备队列缓存较大时,BBR 可能会竞争不过 Cubic 等比较激进算法,原因是 BBR 不主动去占据队列缓存,如果 Cubic 的流量长期占据队列缓存,会使得 BBR 在多个周期内测量的极小 RTT 增大,进而使 BBR 的带宽减小。
适用场景:
适用于高带宽、高时延、有一定丢包率的长肥网络,可以有效降低传输时延,并保证较高的吞吐量。
Remy
Remy[5] 也称为计算机生成的拥塞控制算法(computer-generated congestion-control algorithm),采用机器学习的方式生成拥塞控制算法模型。通过输入各种参数模型(如瓶颈链路速率、时延、瓶颈链路上的发送者数量等),使用一个目标函数定量判断算法的优劣程度,在生成算法的过程中,针对不同的网络状态采用不同的方式调整拥塞窗口,反复修改调节方式,直到目标函数最优,最终会生成一个网络状态到调节方式的映射表,在真实的网络中,根据特定的网络环境从映射表直接选取拥塞窗口的调节方式。
Remy 试图屏蔽底层网络环境的差异,采用一个通用的拥塞控制算法模型来处理不同的网络环境。这种方式比较依赖输入的训练集(历史网络模型),如果训练集能够全面覆盖所有可能出现的网络环境及拥塞调节算法,Remy 算法在应用到真实的网络环境中时能够表现的很好,但是如果真实网络与训练网络差异较大,Remy 算法的性能会比较差。
适用场景:网络环境为复杂的异构网络,希望计算机能够针对不同网络场景自动选择合适的拥塞控制方式,要求现有的网络模型能够覆盖所有可能出现情况。
总结
每一种拥塞控制算法都是在一定的网络环境下诞生的,适合特定的场景,没有一种一劳永逸的算法。网络环境越来越复杂,拥塞控制算法也在不断地演进。本文不是要去选择一个最好的算法,只是简单介绍了几种典型算法的设计思路、优缺点以及适用场景,希望能给大家带来一些启发。
参考论文
[1] S.O. L. Brakmo and L. Peterson. TCP Vegas: New techniques for congestiondetection and avoidance. In SIGCOMM, 1994. Proceedings. 1994 InternationalConference on. ACM, 1994.
[2] V.Jacobson, “Congestion avoidance and control,” in ACM SIGCOMM ComputerCommunication Review, vol. 18. ACM, 1988, pp. 314–329.
[3] L. X. I. R. Sangtae Ha. Cubic: A new TCP -friendlyhigh-speed TCP variant. In SIGOPS-OSR, July 2008. ACM, 2008.
[4] C.S. G. S. H. Y. Neal Cardwell, Yuchung Cheng and V. Jacobson. BBR:congestion-based congestion control. ACM Queue, 14(5):20{53, 2016.
[5] K.Winstein and H. Balakrishnan. TCP Ex Machina: Computer-generated Congestion Control.In Proceedings of the ACM SIGCOMM 2013 Conference, 2013.
以上是关于常见的tcp拥塞控制有哪几种算法的主要内容,如果未能解决你的问题,请参考以下文章