python3网络爬虫实现有道词典翻译功能
Posted 心有琳系
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python3网络爬虫实现有道词典翻译功能相关的知识,希望对你有一定的参考价值。
首先,在谷歌浏览器搜索有道词典,进入有道词典,点击页面顶端的翻译。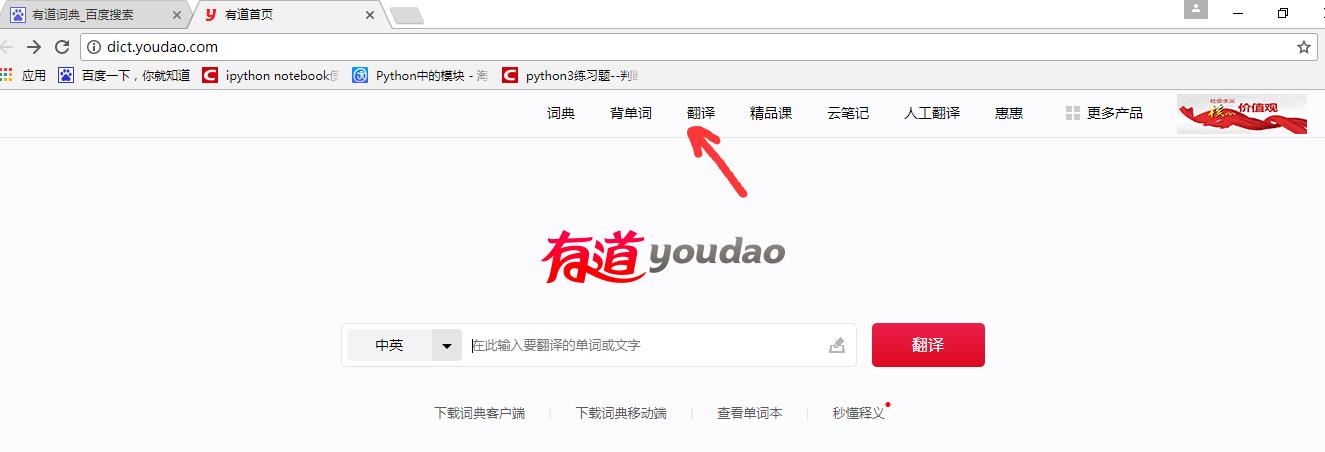
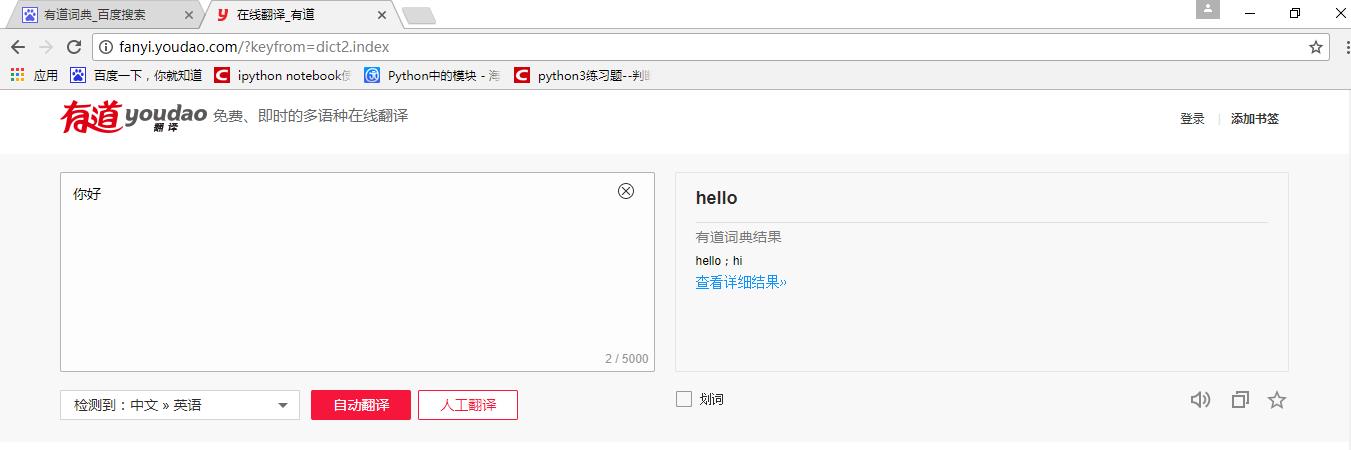
进入翻译界面,在翻译界面输入你好:
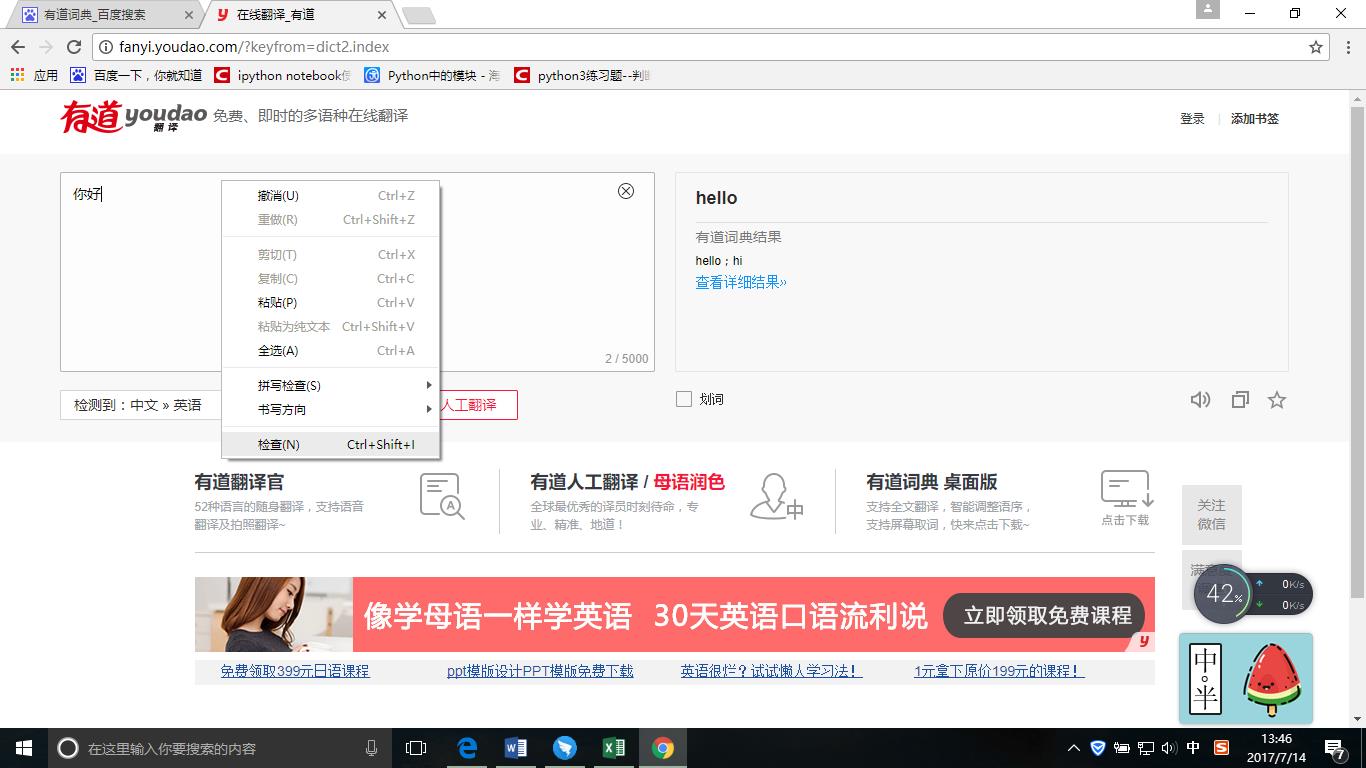
接着,鼠标右键选择检查:
进入页面,找到下面这个表
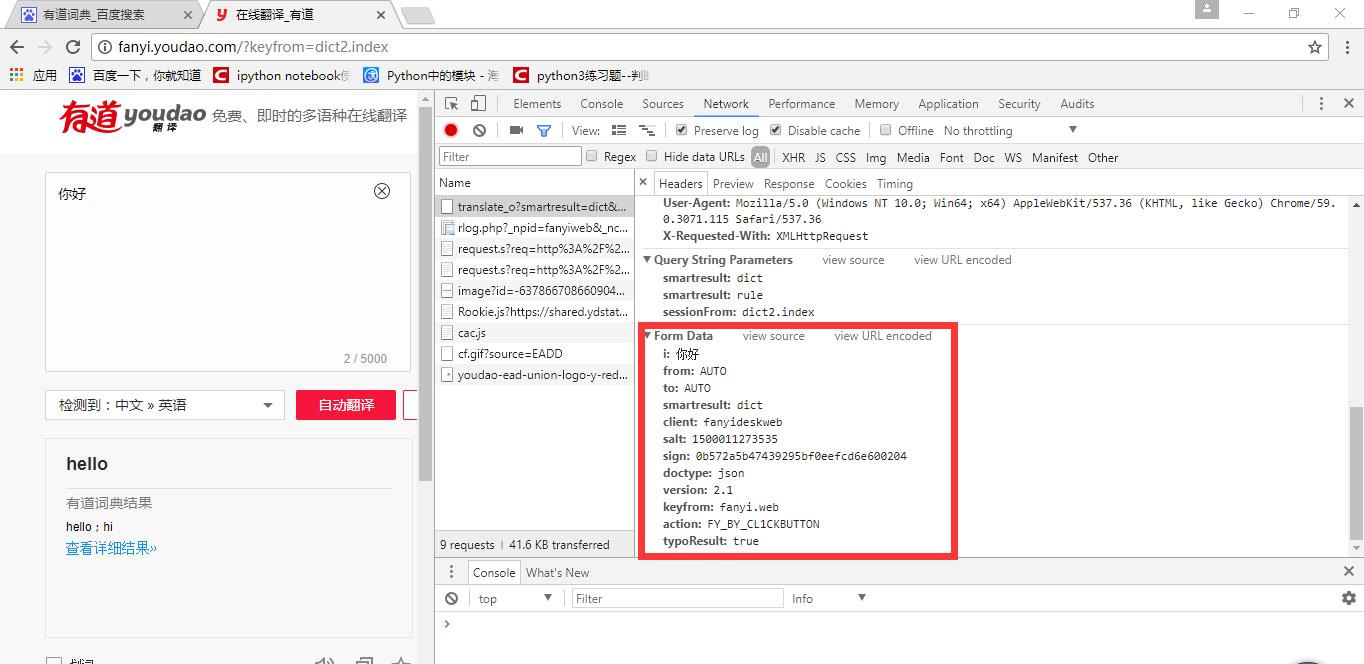
接下来引入urllib包中的request和parse模块:
URL:全球资源定位器(Uniform Resource Locator)
urllib.request: for opening and reading URLs
urllib.parse: for parsing URLs
json:用字符串的格式把python的数据结构封装起来
Form data: post提交的主要内容
data = { }
实现过程中主要用到的几个函数:
data = urllib.parse.urlencode(data).encode(\'utf-8\') (utf-8是python的编码形式)
response = urllib.request.urlopen(url, data)
html = response.read().decode(\'utf-8\')
target = json.loads(html)
实现过程如下:
1 import urllib.request 2 import urllib.parse 3 import json 4 5 url = \'http://fanyi.youdao.com/translate_o?smartresult=dict&smartresult=rule&sessionFrom=https://www.baidu.com/link\' 6 data = {} 7 data[\'i\'] = \'你好\' 8 data[\'from\'] = \'AUTO\' 9 data[\'to\'] = \'AUTO\' 10 data[\'smartresult\'] = \'dict\' 11 data[\'client\'] = \'fanyideskweb\' 12 data[\'salt\'] = \'1499958412421\' 13 data[\'sign\'] = \'68ccf3c733cabfa095ee5dffc9dc56f9\' 14 data[\'doctype\'] = \'json\' 15 data[\'version\'] = \'2.1\' 16 data[\'keyfrom\'] = \'fanyi.web\' 17 data[\'action\'] = \'FY_BY_CL1CKBUTTON\' 18 data[\'typoResult\'] = \'true\' 19 data = urllib.parse.urlencode(data).encode(\'utf-8\') 20 21 response = urllib.request.urlopen(url, data) 22 html = response.read().decode(\'utf-8\') 23 #print(html) 24 target = json.loads(html) 25 26 tmp = target[\'translateResult\'][0][0][\'tgt\'] 27 print(tmp)
以上是关于python3网络爬虫实现有道词典翻译功能的主要内容,如果未能解决你的问题,请参考以下文章