你可能不知道的字符比较中的“秘密”
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了你可能不知道的字符比较中的“秘密”相关的知识,希望对你有一定的参考价值。
原文:你可能不知道的字符比较中的“秘密”有时候,一个简单的字符比较,你可能也会被弄得晕头转向。为什么这样说呢?请看下面这个例子(代码就不贴了,因为后来发现页面不支持这两个字符的显示)。猜测一下,会是什么结果?是1还是0? 回答这个问题之前,请再继续向下看。先创建几个不同排序规则的数据库(见数据库名可知)。
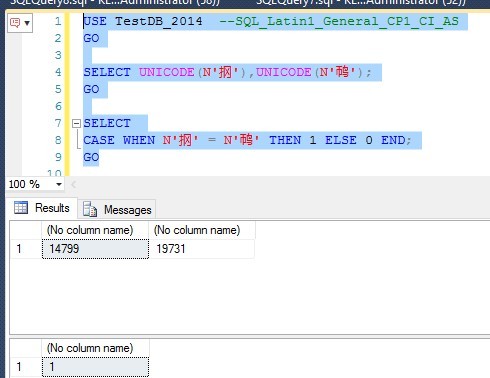
Figure-1: 在SQL_Latin1_General_CP1_CI_AS排序规则下的比较
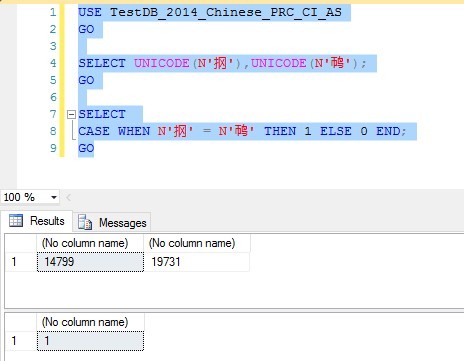
Figure-2: 在Chinese_PRC_CI_AS排序规则下的比较
在SQL_Latin1_General_CP1_CI_AS或是Chinese_PRC_CI_AS两不同的排序规则下,这两个字符竟然是相等的!!很明显看起来就是不相等嘛!使用了UNICODE函数转换也无效。怎么回事呢?!下面就是这个问题的解答。原文是英文,我已经翻译成中文(英语水平有限,错漏难免,最好还是看原文哈)。
附上原文地址:
http://blogs.msdn.com/b/sqlprogrammability/archive/2006/04/07/570397.aspx
未定义的字符在Unicode或Windows排序规则中的排序问题
当在非二进制排序规则中比较两个Unicode字符串时,SQL Server使用一个跟Windows API CompareStringW基本相同的库。这个库为每个已经辨识的字符定义了一个权重值(Weight),并以这个权重值进行字符的比较。然而,并不是所有代码点(code point)都已经在排序库中进行了定义。它们可能被未定义的原因是:
-
代码点在Unicode标准中未进行定义。
-
代码点在Unicode标准中已进行了定义,但在Windows中却未进行定义。这需要花费时间和精力为新的字符定义语言语义的排序。Windows团队通常需要与当时标准组织和/或地区项目经理合作,为新的字符定义排序规则。他们在每个版本中添加新字符的支持,并试图迎头赶上。有些字符也许已经具有字体的定义,因此可能会正常地显示,但仍然没有对比较进行定义。比如NCHAR(13144) - NCHAR(13174)。
-
代码点在Windows进行了定义,但未在SQL Server中定义。
Windows NLS团队已经决定,未定义的字符进行比较时将被忽略,部分原因是没有一个好的办法将未定义的字符和其他已经定义的字符进行比较。SQL Server继承了这一语义。这确实导致了一些令人感觉困惑的行为。看看下面的例子。
declare @undefined_char1 nvarchar(10), @undefined_char2 nvarchar(10) set @undefined_char1 = nchar(0x0000) set @undefined_char2 = nchar(13144) select ‘Undefine characters compare equal to empty string‘ where @undefined_char1 = ‘‘ select ‘All undefine characters compare equal‘ where @undefined_char1 = @undefined_char2 go
create table t (c nvarchar(10)) go create unique index it on t(c) go -- first insert succeeds, but second insert fails with duplicate key error. insert t values (nchar(0x0000)) insert t values (nchar(13144)) go
正如你所见,由于所有未定义的字符比较都为相等的,他们会导致重复键的错误。同理,如果你创建一张未定义字符为表名的表,然后尝试创建另一个未定义字符为表名的表,第二张表会因为表名重复而创建失败,即使这两个未定义字符的代码点是不同的。这也可能导致混淆的结果出现在如CHARINDEX, PATINDEX或LIKE等内置的字符串匹配(功能)中。
虽然这些结果似乎令人迷惑不解,但基本规则其实很简单。即未定义字符和字符串的比较将被忽略。一旦你明白并记住这个规则,这个行为就很容易理解了。
只要有未定义字符的参数将被忽略。由于这是在Windows平台上的行为,没有一个绝对的更好的方法对它们进行排序,并且向右兼容,我们要保持这种行为。
如果你的应用程序要使用到这些未定义的字符,并且把它们当成常规字符处理,你可以使用二进制的排序规则(binary collation)。在二进制排序规则中,比较完全是根据代码点,不是语言规则,因此也没有所谓的已定义和未定义的概念了。(完)
读完这篇博客,你应该明白怎么回事了吧。原因就是:跟未进行定义的字符作比较时,SQL Server视为相等的。如果实际应用中要视为常规字符,转为二进制比较即可。因为二进制的比较就单纯的按照字符的代码点比较了。所以解决最开始的问题不难,如下:
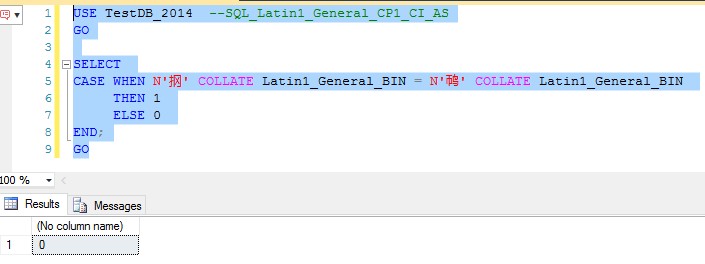
Figure-3: 在Latin1_General_BIN排序规则下的比较
不难推导出,在二进制排序规则下的数据库中,默认下,这两个字符是不相等的。
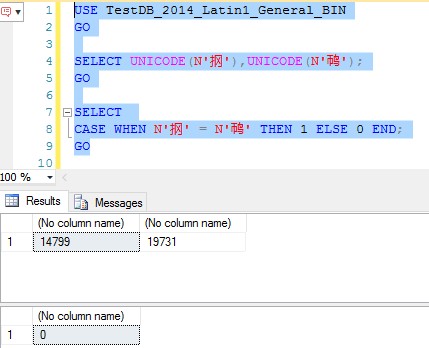
Figure-4: 在Latin1_General_BIN排序规则下的比较
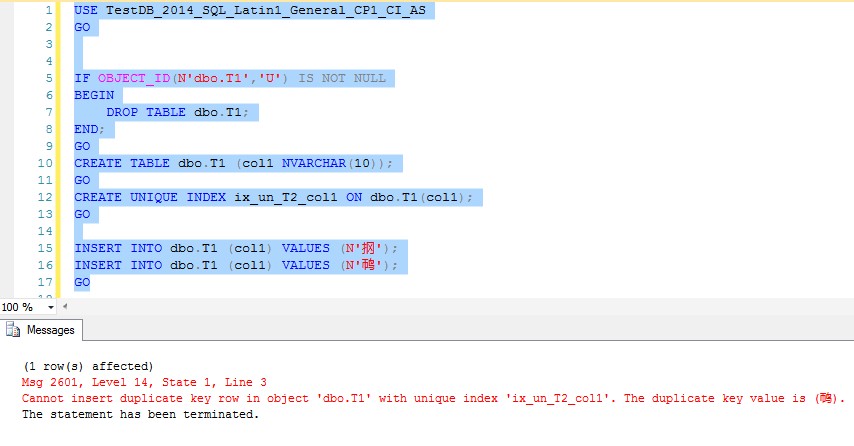
Figure-5: 在SQL_Latin1_General_CP1_CI_AS排序规则下无法插入两行记录
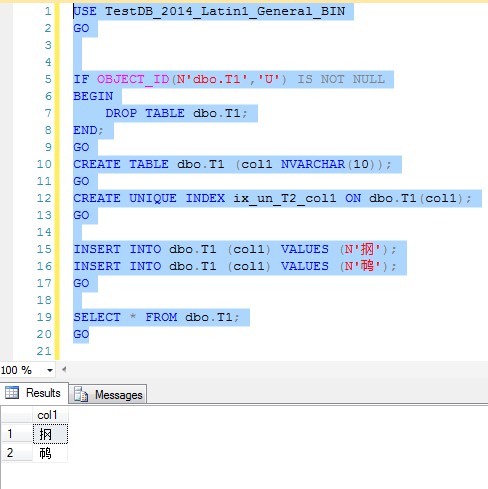
Figure-6: 在Latin1_General_BIN排序规则下,成功插入这两行记录。
以上是关于你可能不知道的字符比较中的“秘密”的主要内容,如果未能解决你的问题,请参考以下文章
关于nginx你可能不知道的秘密----nginx地址重写以及错误页面配置