培训第二周 20170708
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了培训第二周 20170708相关的知识,希望对你有一定的参考价值。
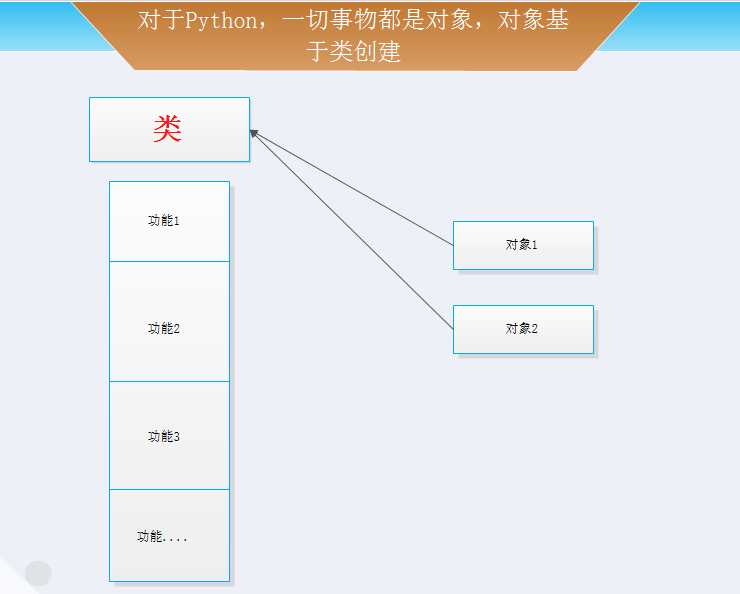
学会查看帮助
type(类型名) 查看对象的类型
dir(类型名) 查看类中提供的所有功能
help(类型名) 查看类中所有详细的功能
help( 类型名.功能名) 查看类中某功能的详细
内置方法,非内置方法:
带下划线的标识私有方法,他们通常拥有不止一种调用方 法。如下,我定义了两个字符串,__add__的+的效果是相同的。这里有一个内置方法很特殊:__init__,它是类中的构造方法,会在调用其所在类的时候自动执行。
二、整型(int)
整型类:
|
1
2
3
|
dir(int)[‘__abs__‘, ‘__add__‘, ‘__and__‘, ‘__bool__‘, ‘__ceil__‘, ‘__class__‘, ‘__delattr__‘, ‘__dir__‘, ‘__divmod__‘, ‘__doc__‘, ‘__eq__‘, ‘__float__‘, ‘__floor__‘, ‘__floordiv__‘, ‘__format__‘, ‘__ge__‘, ‘__getattribute__‘, ‘__getnewargs__‘, ‘__gt__‘, ‘__hash__‘, ‘__index__‘, ‘__init__‘, ‘__int__‘, ‘__invert__‘, ‘__le__‘, ‘__lshift__‘, ‘__lt__‘, ‘__mod__‘, ‘__mul__‘, ‘__ne__‘, ‘__neg__‘, ‘__new__‘, ‘__or__‘, ‘__pos__‘, ‘__pow__‘, ‘__radd__‘, ‘__rand__‘, ‘__rdivmod__‘, ‘__reduce__‘, ‘__reduce_ex__‘, ‘__repr__‘, ‘__rfloordiv__‘, ‘__rlshift__‘, ‘__rmod__‘, ‘__rmul__‘, ‘__ror__‘, ‘__round__‘, ‘__rpow__‘, ‘__rrshift__‘, ‘__rshift__‘, ‘__rsub__‘, ‘__rtruediv__‘, ‘__rxor__‘, ‘__setattr__‘, ‘__sizeof__‘, ‘__str__‘, ‘__sub__‘, ‘__subclasshook__‘, ‘__truediv__‘, ‘__trunc__‘, ‘__xor__‘, ‘bit_length‘, ‘conjugate‘, ‘denominator‘, ‘from_bytes‘, ‘imag‘, ‘numerator‘, ‘real‘, ‘to_bytes‘] |
整型的一些方法示例:
add:求和
|
1
2
3
4
5
|
>>> n2 = 2>>> n1 + n23>>> n1.__add__(n2)3 |
abs 求绝对值
|
1
2
3
4
5
|
>>> n1 = -8>>> n1.__abs__()返回绝对值8>>> abs(-9) 9 |
int:整型转换
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
>>> i = 10>>> i = int(10)>>> i10>>> i = int("10",base=2)>>> i2>>> i = int("11",base=2) (2代表二进制)>>> i3>>> i = int("F",base=16)>>> i15 |
cmp:两个数比较
|
1
2
3
4
5
6
7
8
9
10
|
>>> age = 20>>> age.__cmp__(18) 比较两个数大小1>>> age.__cmp__(22)-1>>> cmp(18,20)-1>>> cmp(22,20)1 |
coerce:商和余数,强制生成一个元组
|
1
2
3
|
>>> i1 = 10>>> i1.__coerce__(2)(10, 2) (强制生成一个元组) |
divmod:分页,相除,得到商和余数组成的元组
|
1
2
3
|
>>> a = 98>>> a.__divmod__(10)(9, 8) #相除,得到商和余数组成的数组,这个一定要会 |
float:转换为浮点类型
|
1
2
3
4
5
6
|
>>> type(a)<type ‘int‘>>>> float(a) 转换为浮点类型98.0>>> a.__float__()98.0 |
int:转换为整型
|
1
2
3
4
5
6
|
>>> a = "2">>> type(a)<type ‘str‘>>>> a = int(a)>>> type(a)<type ‘int‘> |
三、长整型(long)
四、浮点型(float)
浮点类:
|
1
2
3
|
dir(float)[‘__abs__‘, ‘__add__‘, ‘__bool__‘, ‘__class__‘, ‘__delattr__‘, ‘__dir__‘, ‘__divmod__‘, ‘__doc__‘, ‘__eq__‘, ‘__float__‘, ‘__floordiv__‘, ‘__format__‘, ‘__ge__‘, ‘__getattribute__‘, ‘__getformat__‘, ‘__getnewargs__‘, ‘__gt__‘, ‘__hash__‘, ‘__init__‘, ‘__int__‘, ‘__le__‘, ‘__lt__‘, ‘__mod__‘, ‘__mul__‘, ‘__ne__‘, ‘__neg__‘, ‘__new__‘, ‘__pos__‘, ‘__pow__‘, ‘__radd__‘, ‘__rdivmod__‘, ‘__reduce__‘, ‘__reduce_ex__‘, ‘__repr__‘, ‘__rfloordiv__‘, ‘__rmod__‘, ‘__rmul__‘, ‘__round__‘, ‘__rpow__‘, ‘__rsub__‘, ‘__rtruediv__‘, ‘__setattr__‘, ‘__setformat__‘, ‘__sizeof__‘, ‘__str__‘, ‘__sub__‘, ‘__subclasshook__‘, ‘__truediv__‘, ‘__trunc__‘, ‘as_integer_ratio‘, ‘conjugate‘, ‘fromhex‘, ‘hex‘, ‘imag‘, ‘is_integer‘, ‘real‘] |
我们在创建对象的时候,python也会很聪明的识别出float类型,在计算的时候也是这样,不管表达式中有多少整形多少浮点型,只要存在浮点型,那么所有计算都按照浮点型计算,得出的结果也会是float类型。其余方法和整形并没有太大差别,在这里也不做详细总结了。
字符类:
|
1
2
3
|
dir(str)[‘__add__‘, ‘__class__‘, ‘__contains__‘, ‘__delattr__‘, ‘__dir__‘, ‘__doc__‘, ‘__eq__‘, ‘__format__‘, ‘__ge__‘, ‘__getattribute__‘, ‘__getitem__‘, ‘__getnewargs__‘, ‘__gt__‘, ‘__hash__‘, ‘__init__‘, ‘__iter__‘, ‘__le__‘, ‘__len__‘, ‘__lt__‘, ‘__mod__‘, ‘__mul__‘, ‘__ne__‘, ‘__new__‘, ‘__reduce__‘, ‘__reduce_ex__‘, ‘__repr__‘, ‘__rmod__‘, ‘__rmul__‘, ‘__setattr__‘, ‘__sizeof__‘, ‘__str__‘, ‘__subclasshook__‘, ‘capitalize‘, ‘casefold‘, ‘center‘, ‘count‘, ‘encode‘, ‘endswith‘, ‘expandtabs‘, ‘find‘, ‘format‘, ‘format_map‘, ‘index‘, ‘isalnum‘, ‘isalpha‘, ‘isdecimal‘, ‘isdigit‘, ‘isidentifier‘, ‘islower‘, ‘isnumeric‘, ‘isprintable‘, ‘isspace‘, ‘istitle‘, ‘isupper‘, ‘join‘, ‘ljust‘, ‘lower‘, ‘lstrip‘, ‘maketrans‘, ‘partition‘, ‘replace‘, ‘rfind‘, ‘rindex‘, ‘rjust‘, ‘rpartition‘, ‘rsplit‘, ‘rstrip‘, ‘split‘, ‘splitlines‘, ‘startswith‘, ‘strip‘, ‘swapcase‘, ‘title‘, ‘translate‘, ‘upper‘, ‘zfill‘] |
字符串的一些方法示例:
str:转换成str类型:
|
1
|
>>> s = str("abc") |
capitalize:将首字母大写
|
1
2
3
|
>>> name = ‘bruce‘>>> name.capitalize()‘Bruce‘ |
center/ljust/rjst:固定字符串长度,居中/居左/居右 ,下面是使用示例,当然没有正常人会上来就这么用,一般用在打印列表和字典的时候整理格式
|
1
2
3
4
5
6
|
>>> str1.ljust(20,) #设置格式左对齐,其余部分默认情况下,以空格填充‘hello,bruce*********‘ ‘>>> str1.center(20,‘*‘) #设置格式左对齐,剩余部分已“*”填充‘****hello,bruce*****‘>>> str1.rjust(20,‘*‘) #设置格式左对齐,剩余部分已“&”填充‘*********hello,bruce‘ |
count:子序列个数,用来统计一个字符串中包含指定子序列的个数。这个子序列可以是一个字符,也可以是多个字符
|
1
2
3
4
5
|
>>> str1 = ‘hello,I‘m a good man‘>>> str1.count(‘a‘)2>>> str1.count(‘an‘)1 |
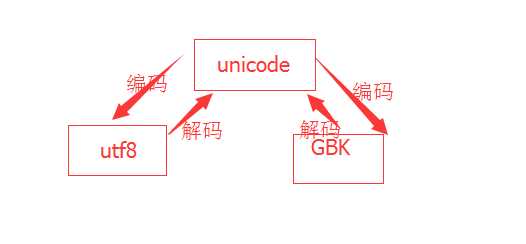
encode/decode:编码/解码,如下左图,各个编码之间是不能直接转换的,计算机内存中默认存储的编码格式是unicode,所以当我们需要将编码在utf8和gbk之间转换的时候,都需要和unicode做操作。
我的终端编码是gbk编码的,当我创建一个string = ‘景‘时,string就被存储成gbk格式。此时我想把gbk格式转换成utf8格式,就要先将原gbk格式的string转换成unicode格式,然后再将unicode转换成utf8格式。如下右图,老师说,把这个字整乱码了我们的目的就达到了
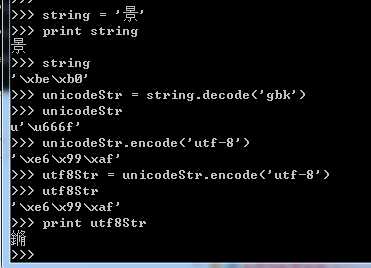
endswith:是否以...(子串)结尾。这里的子串依然可以是一个或多个字符。
|
1
2
3
|
str1 = ‘>>> str1.endswith(‘man‘)True |
expandtabs:将tab转换成空格,默认一个tab转换成8个空格。当然这里也可以自行指定转换成多少个空格
|
1
2
3
4
5
|
>>> name = ‘ bruce‘>>> name.expandtabs()‘ bruce‘>>> name.expandtabs(20)‘ bruce‘ |
find:返回字符串中第一个子序列的下标。
rfind:和find用法一样,只是它是从右向左查找
index:和find的左右一致,只是find找不到的时候会返回-1,而index找不到的时候会报错
值得注意的是,当我们在一个字符串中查找某一个子序列的时候,如果这个字符串中含有多个子序列,只会返回第一个找到的下标,不会返回其他的。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
str1 = "hello,my,world">>> str1.find("m")6>>> str1.find("y")7>>> str1.find("g")-1>>> str1.index("y")7>>> str1.index("g")Traceback (most recent call last): File "<stdin>", line 1, in <module>ValueError: substring not found |
format:各种格式化,动态参数。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
>>> name = ‘I am {0},age {1}’>>> name‘I am {0},age {1}‘传入字符串:>>> name.format(‘bruce‘,18) """ 字符串格式化 “”"‘I am bruce,age 18‘>>> name = ‘I am {ss},age {dd}‘>>> name.format(ss="bruce",dd=18)‘I am bruce,age 18’传入一个列表:>>> li = ["bruce",18]>>> name = ‘I am {0},age {1}’>>> name.format(*li) (传列表加一个“*”)‘I am bruce,age 18’传入一个字典:name = ‘I am {ss},age {dd}’>>> dic = {‘ss‘:"bruce",‘dd‘:18}>>> name.format(**dic)‘I am bruce,age 18’ |
isalnum/isalpha/isdigit/isspace/islower/istitle/isupper:是否是字母或数字/是否字母/是否数字/是否空格/是否小写/是否标题/是否全大写,总之都是一些判断的方法,返回的不是True就是False。。。
isalnum:是否是字母和数字
|
1
2
3
4
5
6
7
8
9
10
|
>>> a‘howareyou’>>> a.isalnum() True>>> a = "__">>> a.isalnum()False>>> a = ‘123‘>>> a.isalnum()True |
isalpha:是否是字母
|
1
2
3
4
5
6
7
|
>>> a‘123‘>>> a.isalpha() False>>> a = ‘allen‘>>> a.isalpha()True |
isdigit:是否是数字
|
1
2
3
4
5
6
7
|
>>> a = ‘123‘>>> a.isdigit() True>>> a = ‘allen‘>>> a.isdigit()False |
islower:是否小写
|
1
2
3
4
5
6
|
>>> a = ‘allen‘>>> a.islower() True>>> a = ‘Allen‘>>> a.islower()False |
istitle:是否是标题
|
1
2
3
4
5
6
|
>>> name = "Hello Allen">>> name.istitle() True>>> name = "Hello allen">>> name.istitle()False |
partition/split:这两个方法都用来分割。
partition会将指定的子串串提取并将子串两侧内容分割,只匹配一次,并返回元祖;
split会根据指定子串,将整个字符串所有匹配的子串匹配到并剔除,将其他内容分割,返回数组。
|
1
2
3
4
5
|
>>> food = ‘apple,banana,chocolate‘>>> food.split(‘,‘)[‘apple‘, ‘banana‘, ‘chocolate‘]>>> food.partition(‘,‘)(‘apple‘, ‘,‘, ‘banana,chocolate‘) |
replace:替换。会替换字符串中所有符合条件的子串。
|
1
2
3
|
str1 = "one two one two">>> str1.replace(‘one‘,‘five‘)five two five two |
swapcase:大写变小写,小写变大写
|
1
2
3
|
str1 = "one two one two"str1.swapcase()ONE TWO ONE TWO |
translate:替换,删除字符串。这个方法的使用比较麻烦,在使用前需要引入string类,并调用其中的maketrans方法建立映射关系。这样,在translate方法中,加入映射参数,就可以看到效果了。如下‘aeiou’分别和‘12345’建立了映射关系,于是在最后,aeiou都被12345相应的替换掉了,translate第二个参数是删除,它删除了所有的‘.’
|
1
2
3
4
5
6
7
8
|
>>> in_tab = ‘aeiou‘>>> out_tab = ‘12345‘>>> import string>>> transtab = string.maketrans(in_tab,out_tab)>>> str = ‘this is a translate example...wow!‘>>> str1 = ‘this is a translate example...wow!‘>>> print str1.translate(transtab,‘..‘)th3s 3s 1 tr1nsl1t2 2x1mpl2w4w! |
六、列表(list)
列表类:
|
1
2
|
dir(list)[‘__add__‘, ‘__class__‘, ‘__contains__‘, ‘__delattr__‘, ‘__delitem__‘, ‘__dir__‘, ‘__doc__‘, ‘__eq__‘, ‘__format__‘, ‘__ge__‘, ‘__getattribute__‘, ‘__getitem__‘, ‘__gt__‘, ‘__hash__‘, ‘__iadd__‘, ‘__imul__‘, ‘__init__‘, ‘__iter__‘, ‘__le__‘, ‘__len__‘, ‘__lt__‘, ‘__mul__‘, ‘__ne__‘, ‘__new__‘, ‘__reduce__‘, ‘__reduce_ex__‘, ‘__repr__‘, ‘__reversed__‘, ‘__rmul__‘, ‘__setattr__‘, ‘__setitem__‘, ‘__sizeof__‘, ‘__str__‘, ‘__subclasshook__‘, ‘append‘, ‘clear‘, ‘copy‘, ‘count‘, ‘extend‘, ‘index‘, ‘insert‘, ‘pop‘, ‘remove‘, ‘reverse‘, ‘sort‘] |
列表的一些方法示例:
append:向列表中添加项
insert:在列表的指定位置加入值
extend:列表的扩展;那么列表可以自己扩展自己么???当然是可以的啦!
|
1
2
3
4
5
6
7
8
9
10
11
12
|
>>> >>> a = [1,2,3,4]>>> a.append(5)>>> a[1, 2, 3, 4, 5]>>> b = [6,7]>>> a.extend(b)>>> a[1, 2, 3, 4, 5, 6, 7]>>> a.insert(2,0)>>> a[1, 2, 0, 3, 4, 5, 6, 7] |
index:返回列表中第一个匹配项的下标
__contain__:查看列表中是否包含某一项
count:查看列表中某一项出现的次数
|
1
2
3
4
5
6
7
8
9
10
|
>>> a[1, 2, 0, 3, 4, 5, 6, 7]>>> a.index(0)2>>> a.__contains__(7)True>>> a.__contains__(8)False>>> a.count(5)1 |
pop:删除并返回指定下标的值,默认为列表的最后一个值
remove:删除列表中与指定值匹配的第一个值
__delitem__:删除指定下标的值
__delslice__:删除指定下标区域内的所有值,下标向下包含
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
>>> a[1, 2, 0, 3, 4, 5, 6, 7]>>> a.pop()7>>> a[1, 2, 0, 3, 4, 5, 6]>>> a.pop(2)0>>> a[1, 2, 3, 4, 5, 6]>>> a.remove(2)>>> a[1, 3, 4, 5, 6]>>> a.__delitem__(0)>>> a[3, 4, 5, 6]>>> a.__delslice__(0,2)>>> a[5, 6] |
reverse:列表反转,这个反转并没有什么编码顺序,就是单纯的把原来的列表从头到尾调转过来而已。。。
sort:排序,数字、字符串按照ASCII,中文按照unicode从小到大排序。
|
1
2
3
4
5
6
7
|
>>> a = [5,4,6,8,2,6,9]>>> a.sort()>>> a[2, 4, 5, 6, 6, 8, 9]>>> a.reverse()>>> a[9, 8, 6, 6, 5, 4, 2] |
元组类:
|
1
2
|
dir(tuple)[‘__add__‘, ‘__class__‘, ‘__contains__‘, ‘__delattr__‘, ‘__dir__‘, ‘__doc__‘, ‘__eq__‘, ‘__format__‘, ‘__ge__‘, ‘__getattribute__‘, ‘__getitem__‘, ‘__getnewargs__‘, ‘__gt__‘, ‘__hash__‘, ‘__init__‘, ‘__iter__‘, ‘__le__‘, ‘__len__‘, ‘__lt__‘, ‘__mul__‘, ‘__ne__‘, ‘__new__‘, ‘__reduce__‘, ‘__reduce_ex__‘, ‘__repr__‘, ‘__rmul__‘, ‘__setattr__‘, ‘__sizeof__‘, ‘__str__‘, ‘__subclasshook__‘, ‘count‘, ‘index‘] |
八、字典(dict)
字典类:
|
1
2
|
dir(dict)[‘__class__‘, ‘__contains__‘, ‘__delattr__‘, ‘__delitem__‘, ‘__dir__‘, ‘__doc__‘, ‘__eq__‘, ‘__format__‘, ‘__ge__‘, ‘__getattribute__‘, ‘__getitem__‘, ‘__gt__‘, ‘__hash__‘, ‘__init__‘, ‘__iter__‘, ‘__le__‘, ‘__len__‘, ‘__lt__‘, ‘__ne__‘, ‘__new__‘, ‘__reduce__‘, ‘__reduce_ex__‘, ‘__repr__‘, ‘__setattr__‘, ‘__setitem__‘, ‘__sizeof__‘, ‘__str__‘, ‘__subclasshook__‘, ‘clear‘, ‘copy‘, ‘fromkeys‘, ‘get‘, ‘items‘, ‘keys‘, ‘pop‘, ‘popitem‘, ‘setdefault‘, ‘update‘, ‘values‘] |
字典的一些方法示例:
字典取值:
|
1
2
3
4
5
|
>>> dic = {‘allen‘:1234,‘yyh‘:123}>>> dic{‘allen‘: 1234, ‘yyh‘: 123}>>> dic[‘allen‘]1234 |
get:get方法得到value,不存在返回None
|
1
2
3
4
5
6
7
|
>>> dic.get(‘kk‘)>>> print dic.get(‘kk’) None>>> print dic.get(‘kk‘,‘OK’) #写上OK,则返回OKOK>>> print dic.get(‘kk‘,‘TT‘)TT |
clear:清空字典
|
1
2
3
|
dic = {"aaa":123,"bbb":321}dic.clear()None |
pop:根据指定的key删除一组数据
popitem:随机的删除一组数据
|
1
2
3
4
5
6
7
8
9
10
11
|
dic = {"aaa":123,"bbb":321,"ccc":333}dic.popitem()(‘aaa‘, 123)dic{‘bbb‘: 321, ‘ccc‘: 333}dic = {"aaa":123,"bbb":321,"ccc":333}dic.pop("aaa")123dic{‘bbb‘: 321, ‘ccc‘: 333} |
setdefault:dic.setdefault[key1],key1存在,则返回value1,不存在,则自动创建value = ‘None‘
|
1
2
3
4
5
6
7
|
dic = {"aaa":123,"bbb":321,"ccc":333} dic.setdefault("aaa")123dic.setdefault("ddd")Nonedic{‘aaa‘: 123, ‘bbb‘: 321, ‘ddd‘: None, ‘ccc‘: 333} |
update:dict1.update(dict2),判断dict2中的每一个key在dict1中是否存在,存在:就将dict1中的value更新成dict2中的,不存在:将key和value都复制过去
|
1
2
3
4
5
|
dic1 = {"aaa":None,"bbb":321,"ccc":333}dic2 = {"aaa":123,"bbb":222,"ccc":555}dic1.update(dic2)dic1{‘ccc‘: 555, ‘aaa‘: 123, ‘bbb‘: 222} |
fromkeys:可以通过list创建一个字典
|
1
2
3
4
5
6
7
8
|
seq = (‘name‘, ‘age‘, ‘sex‘)dict = dict.fromkeys(seq)print("New Dictionary : %s" % str(dict))New Dictionary : {‘age‘: None, ‘sex‘: None, ‘name‘: None}dict = dict.fromkeys(seq, 10)print("New Dictionary : %s" % str(dict))New Dictionary : {‘age‘: 10, ‘sex‘: 10, ‘name‘: 10} |
copy:浅拷贝,只是第一层独立了,第二层及以下还是跟着母字典一样
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
dic1 = {‘name‘: ‘sky‘, ‘otherInfo‘: {‘hobby‘: [‘read‘, ‘sport‘]}, ‘gender‘: ‘man‘, ‘age‘: 18}# print(dic1)dic2 = dic1.copy()dic1["name"]="bruce"print(dic1){‘age‘: 18, ‘gender‘: ‘man‘, ‘name‘: ‘bruce‘, ‘otherInfo‘: {‘hobby‘: [‘read‘, ‘sport‘]}}print(dic2){‘age‘: 18, ‘gender‘: ‘man‘, ‘name‘: ‘sky‘, ‘otherInfo‘: {‘hobby‘: [‘read‘, ‘sport‘]}} #dic2这一层没有随着dic1一起更改dic2 = dic1.copy()dic1["otherInfo"][0]="bruce"print(dic1)print(dic2){‘name‘: ‘sky‘, ‘otherInfo‘: {‘hobby‘: [‘read‘, ‘sport‘], 0: ‘bruce‘}, ‘gender‘: ‘man‘, ‘age‘: 18}#这次dic1和dic2的输出一样了,因为copy只是独立复制第一层,再深的就不管了。 |
以上是关于培训第二周 20170708的主要内容,如果未能解决你的问题,请参考以下文章