127. Word Ladder
Posted Premiumlab
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了127. Word Ladder相关的知识,希望对你有一定的参考价值。
https://leetcode.com/problems/word-ladder/#/description
Given two words (beginWord and endWord), and a dictionary\'s word list, find the length of shortest transformation sequence from beginWord to endWord, such that:
- Only one letter can be changed at a time.
- Each transformed word must exist in the word list. Note that beginWord is not a transformed word.
For example,
Given:
beginWord = "hit"
endWord = "cog"
wordList = ["hot","dot","dog","lot","log","cog"]
As one shortest transformation is "hit" -> "hot" -> "dot" -> "dog" -> "cog",
return its length 5.
Note:
- Return 0 if there is no such transformation sequence.
- All words have the same length.
- All words contain only lowercase alphabetic characters.
- You may assume no duplicates in the word list.
- You may assume beginWord and endWord are non-empty and are not the same.
UPDATE (2017/1/20):
The wordList parameter had been changed to a list of strings (instead of a set of strings). Please reload the code definition to get the latest changes.
Sol :
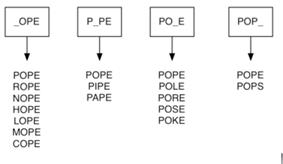
from collections import deque class Solution(object): def ladderLength(self, beginWord, endWord, wordList): """ :type beginWord: str :type endWord: str :type wordList: List[str] :rtype: int """ # Time O(n) Space O(n) # Suppose that we have a huge number of buckets, each of them with a four-letter word on the outside, except that one of the letters in the label has been replaced by an underscore. # See Figure 1 # We can implement the scheme we have just described by using a dictionary. # The labels on the buckets we have just described are the keys in our dictionary. # The value stored for that key is a list of words. def construct_dict(word_list): d = {} for word in word_list: for char in range(len(word)): # s is the label of buckets, i,e, key of the dictionary s = word[:char] + "_" + word[char+1:] # d[s] is the content of busckets, list of words. i.e. value of the dictinoary. d[s] = d.get(s, []) + [word] # after the outer for loop, d is like: # e.x. d[_ope] = ["pope", "rope", "lope"] # d[p_pe] = ["pope", \'pipe\'] # ... return d # the input dict_words is in the format of the ouput if previous method # e.x. dict_words[_ope] = ["pope", "rope", "lope"] # dict_words[p_pe] = ["pope", \'pipe\'] # ... # the reason why the input dictinoary is in the "buscket" format is to save time... btw, tried the "non buscket " way, time exceeds limit... def bfs_words(begin, end, dict_words): queue, visited = deque([(begin, 1)]), set() # the queue stores the final path while queue: # initiate word and steps; restore queue to empty when first come in # advance to examining the word just added to the queue in second and the following while loops word, steps = queue.popleft() if word not in visited: visited.add(word) if word == end: return steps for i in range(len(word)): s = word[:i] + "_" + word[i+1:] neigh_words = dict_words.get(s, []) for neigh in neigh_words: if neigh not in visited: queue.append((neigh, steps + 1)) return 0 d = construct_dict(wordList) return bfs_words(beginWord, endWord, d)
Similar to :
以上是关于127. Word Ladder的主要内容,如果未能解决你的问题,请参考以下文章