如何给 8000 人开一张报表的权限?苏宁多维报表平台应用实践!
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何给 8000 人开一张报表的权限?苏宁多维报表平台应用实践!相关的知识,希望对你有一定的参考价值。
伴随“大数据”浪潮的来临,数据决定成败的观念已波及社会的各行各业,深刻影响和改变着人们的思维。在工业界,数据已成为企业核心竞争力之一,越来越多的企业已经开始不满足于单纯的收集存储数据,都开始尝试通过不同的途径发掘数据宝藏。

假设数据有 10 个维度,每个维度有 10 种取值,如何做到任意组合、任意视角的分析?这正是多维分析平台要解决的问题。
这两年,涌现了不少的优秀开源产品:如 kylin、druid 等,linkedin 今年也开源了自家解决方案 pinot,多维分析平台的热度可见一斑。本文将与大家分享苏宁多维报表平台的探索之路。
多维报表分析的发展史
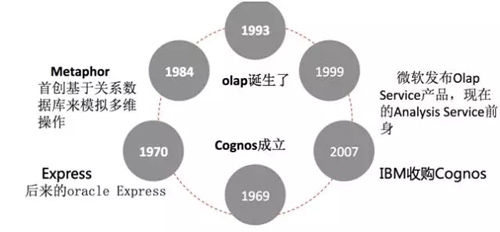
如下图是多维报表的发展历史。1969 年,Congnos 成立,专门做多维报表。1970 年,Express 成立,于 2000 年被 Oracle 收购,变成甲骨文的多维报表方案。1984 年,Metaphor 成立,首创了基于关系数据库来模拟多维操作。1993 年,Olap 诞生。1999 年,微软推出 OlapService 产品。2007 年,IBM 收购了 Cognos。
为什么苏宁要自研多维报表平台?
苏宁是一家传统企业,早期使用 Saas 系统做报表、ERP 管理和财务数据的管理,后来采购了 WEBI 系统,来配合 SAP 系统的使用,其中 WEBI 系统于 2016 年停止维护。2013 年,苏宁采购了 Cognos8 版本系统,目前 Cognos 上面有 2-3 千张报表,每天定时生成。
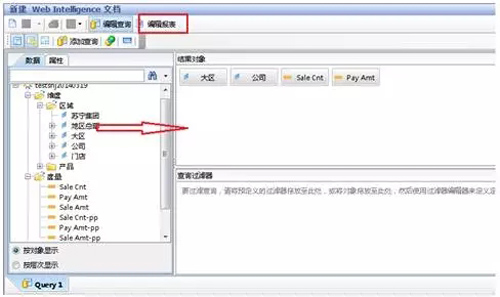
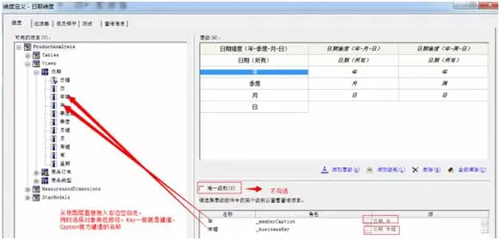
上图是 WEBI 系统界面,下图是 Cognos 界面,多维分析软件的界面大多雷同,一般基于一些维度、指标,进行选项勾选,做出报表,进行可视化图形分析等。
从苏宁的角度来看,自研多维报表平台,主要因为以下四点:
商业费用。
性能过慢。性能不能满足使用需求,跟不上业务场景变化。
技术驱动。苏宁在去 IOE,技术驱动,全面积累。
维护困难。
苏宁多维报表平台方案概述
苏宁多维报表平台设计理念
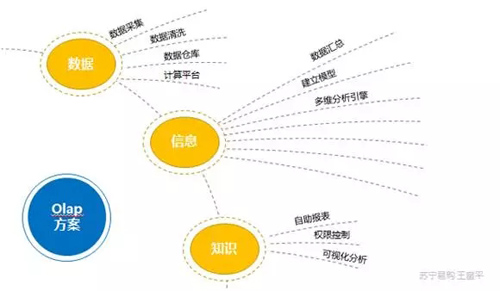
Olap 方案的最终理念归结于数据、信息、知识三部分,首先要拿到原始数据,进行信息的提炼,再根据信息,进一步提炼出知识。
数据部分,涉及到采集、清洗、仓库以及算法平台等细节。
信息部分,通过数据汇总、建立模型,多维分析引擎等一系列步骤而成。
知识部分,包含自助报表、权限控制、可视化分析,是通过信息进一步提炼的结果。
苏宁多维报表平台的架构
如下图是整个平台的架构,最底层是业务系统,主要功能是采集数据,如用户日志,各种业务系统日志。数据仓库层,做建模汇总,通过数据服务对外开放。报表工具制定一个报表,来做定制化报表分析等等。蓝色部分依赖于云计算平台。

苏宁多维报表平台架构的整体流程
把整体流程提炼成数据采集、数据建模、Olap 加速和报表分析四个部分。数据采集不用多说,数据建模方面,可大可小,最简单就是提炼出所需的信息。
建模更广泛的讲,可以做标签、算法、模型。建模的目的是为了做报表使用。只有通过 Olap 加速才能产出一个可用的报表分析。最后,是报表分析,这四步是紧密结合的一个流程。
Olap 引擎的技术选型
Olap 引擎选择理念
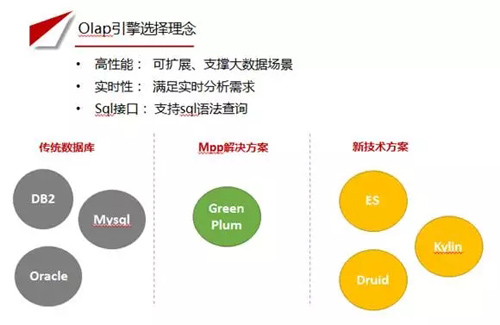
市面上 Olap 种类很多,包含传统数据库,如 DB2,mysql,Oracle 等。MPP 解决方案,主要涉及 Green Plum。还有一些新的技术方案,如 ES、Druid、Kylin 等。
那这么多的加速引擎,要如何选择呢?苏宁的做法是适配所有方案,也就是说没必要限制在某一个引擎上,调用那个引擎,由场景来决定,符合需求即可。
Olap 引擎之 Druid
目前,Druid 是苏宁比较重头的引擎,像用户流量日志,订单数据,这些数据都在使用 Druid。Druid 的特点有很多,这里主要介绍四点:
实时计算。从 kafka 实时把数据写到集,支持实时索引和实时查询。
时间分区。数据一定要有时间字段,就是 Log 类。
列式存储。通过位置索引来操作。
聚合计算。像 count、distinct、sum、max、min 等等操作,已经满足绝大部分场景。
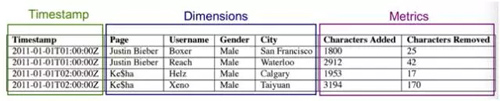
如上图,是 Druid 一个应用结构,可以看到必须有时间字段,以及定义维字段和指标字段。指标字段就是聚合,聚合方式是用近似算法。这里应用到了基于 Druid 做的聚合插件,但是没有做开源。
Olap 引擎之 Druid 高效的原因
列式存储,快速维度过滤。列式存储就是一行只存一列。例如,有一列肯定是姓名,这是姓名的维度。
Rollup 压缩。在数字上,定指标。
高效的聚合算法。聚合是把多条数据聚合到一起,可以节省空间,提升效率。
Olap 引擎之 Druid 的 SQL 支持
这里值得一提的是选用引擎标准有 SQL 接口,但 Druid 本身却没有 SQL 接口。这里用到的解决方案就是 Calcite,可通过 SQL 来操作 Druid,也就是通过 SQL 定义某个指标或维度。Calcite 并不是通过任何改造都可以用。
Olap 引擎之 ES
ES 的功能主要有数据分片,高效索引和聚合计算。索引选用的是目前索引开源方案中比较不错的 Lucence。它本身也没有官方 SQL 接口。
ES 设计的目的是做搜索,储存一些明细数据,而不需要时间字段。如用户画像数据,要快速做报表和监控之类,数据量非常大,就比较适合用 ES。而像日志这样的就适合用 Druid。
苏宁多维报表平台的性能优化
针对性能优化,我们的主要策略就是缓存。首先分几个场景:
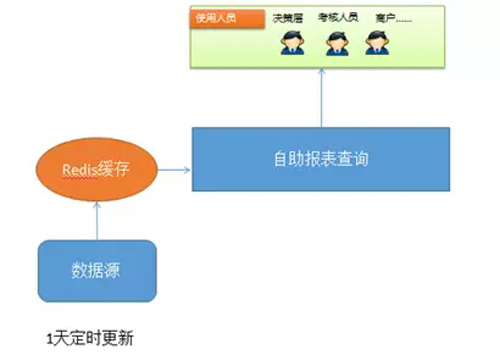
非日志类数据,定时更新(典型的是用户画像)。
日志类数据(append only,时间分区):定时更新。
日志类数据(append only,时间分区):实时更新。
场景一:非日志类数据,定时更新(典型的:用户画像)
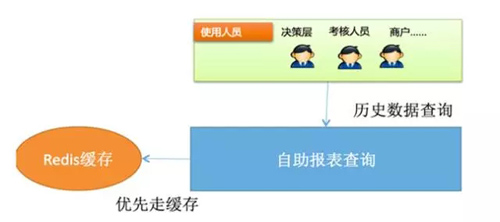
日志类数据(appendonly,时间分区):定时更新、实时更新
日志类数据的特点是:历史数据一旦存储好,就不会变动,针对历史数据的查询,可以进行加速优化:
缓存。
预计算。
针对热门报表,如销售,用户经常使用的维度组合可以提前做预计算,来加速。
苏宁多维报表平台的业务策略与架构选择
权限控制
苏宁有 30+大区,500+城市公司,1500+门店,1300+易购服务站,如何给 8000 人开一张报表的权限?方法有二:
维护报表权限维度:大区、城市公司、门店等。
抽取 ERP 中人员身份信息,进行权限自动匹配。
衍生指标计算-同比、环比、占比
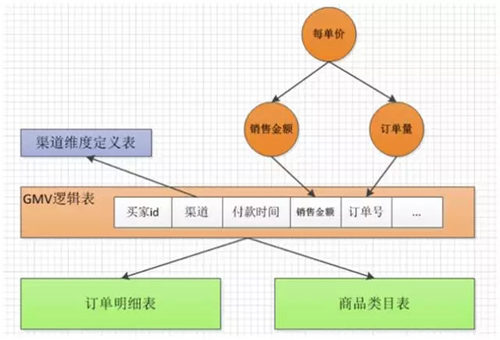
基础指标:由当前数据直接计算得出,无需其他数据。
衍生指标:一般由多个基础指标数据(不同指标或不同维度)计算得出,甚至需要第三方数据确定。
逻辑:如判断哪一天是同比天,需要第三方逻辑数据。
衍生指标计算
复购率。
财务指标:(xx产品结构实际进销差率- 其他产品结构进销差额/ 其他产品结构付款金额)*变动比例(销售占比平均值-销售占比实际值)*产品总付。
苏宁多维报表平台的未来展望
未来,苏宁平台的 SQL 统一由 Calcite 支撑,还有多模型组合。目前,苏宁还是单模型组合,因为用户希望在一张报表既能看到流量,又能看到销售数据,后期会进行多模型组合,还会做一些可视化方面的建设。

王富平
苏宁大数据中心高级架构师
历任百度大数据部高级工程师、 1 号店搜索与精准化部门架构师,一直从事大数据方向的研发工作,对大数据工具、机器学习有深刻的认知,在实时计算领域经验丰富。2013 年,基于公司实时处理平台设计开发了 SQL on Stream 解决方案。热爱分享和技术传播。目前关注方向为数据分析平台建设,旨在提供一个平台级别的数据服务,打造“数据即服务”的一站式解决方案。
以上内容根据王富平老师在 WOTA2017 “大数据应用创新”专场的演讲内容整理。

本文出自 “12562290” 博客,请务必保留此出处http://12572290.blog.51cto.com/12562290/1946618
以上是关于如何给 8000 人开一张报表的权限?苏宁多维报表平台应用实践!的主要内容,如果未能解决你的问题,请参考以下文章