Spark机器学习:KMenas算法
Posted 代码空间
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark机器学习:KMenas算法相关的知识,希望对你有一定的参考价值。
KMenas算法比较简单,不详细介绍了,直接上代码。
import org.apache.log4j.{Level, Logger} import org.apache.spark.{SparkConf, SparkContext} import org.apache.spark.mllib.linalg.Vectors import org.apache.spark.mllib.clustering._ /** * Created by Administrator on 2017/7/11. */ object Kmenas { def main(args:Array[String]): Unit ={ // 设置运行环境 val conf = new SparkConf().setAppName("KMeans Test") .setMaster("spark://master:7077").setJars(Seq("E:\\\\Intellij\\\\Projects\\\\MachineLearning\\\\MachineLearning.jar")) val sc = new SparkContext(conf) Logger.getRootLogger.setLevel(Level.WARN) // 读取样本数据并解析 val data = sc.textFile("hdfs://master:9000/ml/data/kmeans_data.txt") val parsedData = data.map(s => Vectors.dense(s.split(\' \').map(_.toDouble))).cache() // 新建KMeans聚类模型并训练 val initMode = "k-means||" val numClusters = 2 val numIterations = 500 val model = new KMeans(). setInitializationMode(initMode). setK(numClusters). setMaxIterations(numIterations). run(parsedData) val centers = model.clusterCenters println("Centers:") for (i <- 0 to centers.length - 1) { println(centers(i)(0) + "\\t" + centers(i)(1)) } // 误差计算 val Error = model.computeCost(parsedData) println("Errors = " + Error) } }
运行结果:
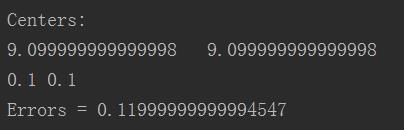
以上是关于Spark机器学习:KMenas算法的主要内容,如果未能解决你的问题,请参考以下文章