在Elasticsearch中实现统计异常检测器——第一部分
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了在Elasticsearch中实现统计异常检测器——第一部分相关的知识,希望对你有一定的参考价值。
Implementing a Statistical Anomaly Detector in Elasticsearch - Part 1
该图显示了4500万个数据点的最小/最大/平均值(超过600小时的75,000个单独时间序列)。这个图表中有八个大型的模拟中断,你能发现吗?
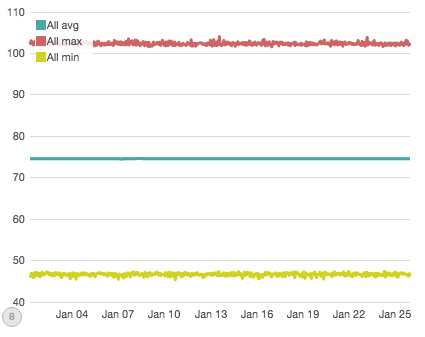
没有? 没关系,我也不行。当你将所有数据汇总到一个图表中时,你所有的数据变化往往可以平滑表示,除了最明显的变化。相比之下,这是从组成第一个图形的75,000系列中随机选择的:
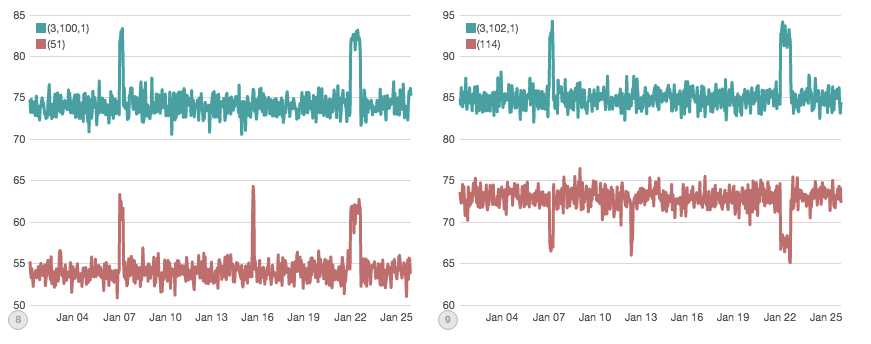
这些单独的图表明确的显示可能发生中断的地方。但现在我们有一个新的问题:有75,000这样的图标需要关注,并且由于每个图标都有自己的动态范围和噪音剖面(noise profile),所以你如何设置所有的阈值?
很多公司都遇到这个难题。随着数据集合的增加,我们需要新的方式以动态筛选数据和发现异常。这正式eBay使用新的Atlas异常检测算法所做的。
该算法的作者认识到,任何独立的序列可能看起来都是异常的,因为机会简单(simple due to chance),所以简单的阈值将不起作用,然而同时集合所有的数据在一起使数据处理的过于平滑。
相反,Atlas将基础数据方差的变化汇总在一起。这意味着它对于噪音是稳健的,但是当由于中断导致基础分布发生真实的,相关联的变化时,它们仍保留足够的敏感去警告。
在阅读该篇之后,我想看看它在Elasticsearch中是否能实现。通过本文的另外三部分,我们将探索Atlas的工作原理以及如何通过Pipeline聚合,TimeLion图和Watcher预警来组合来构建它的。为了让你先睹为快,我们最终的图标看起来像这样:
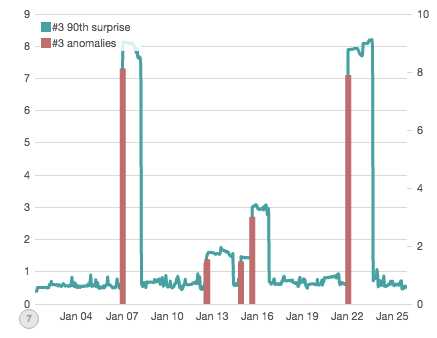
“异常条”准确位置在位于子集数据生成的每一个模拟中断之上。Let’s get to it!
模拟生产集群(Simulating a production cluster)
第一业务是生成一些数据。因为我们不是eBay,我们必须解决模拟数据。我在Rust中写了一个快速的“生产集群模拟器”,它生成我们的数据集。在高层次上,模拟是非常简单的:
- 有n个节点在集群中
- 针对此集群有q个查询被执行(想像他们在查询项目,等等)
- 针对每个查询结果,计算出m个权值(metrics)。
- 为每个(节点,查询,权值)元组每小时记录一个数据点。
为使模拟真实,每个(节点,查询,权值)都有唯一的高斯分布,它用于数据的生成。例如,(1,1,1)元组可以从以58为中心的正太分布和2的标准差(a width of 2 std)获取值,而元组(2,1,1)可以从以70为中心的分布和1的标准差获取值。
这个设置很重要,原因有几个。第一,相同的查询和权值组合在每个节点上将会有不同的分布,引入大量的自然变化性。其次,由于这个分布是正太高斯分布,它们没有限制硬性值的范围,但是理论上可以抛出异常(仅仅统计学上不可能)。最后,虽然元组之间存在大量的变异性,个体(节点,查询,权值)元组是非常一致的,他们总是从自己的分布中获取。
模拟器中的最后一块是模拟中断。每一个(node,query,metric)元组也有中断分布。在时间轴的随机点,模拟器将触发1/3的中断。
- 节点中断:在集群中单个节点将被视为中断。这意味着所有的query/metric将改变到节点中断分布上。例如,节点1中断,所有元组(1,query ,metric)被影响.
- 查询中断:集群中最多十分之一的查询将切换到其中断分布,而不考虑metric或node。假如查询1中断,所有元组(node,1.metric)被影响。
- Metric中断:集群中一个或多个metrics将切换到其中断分布,而不考虑query或node。假如metric1中断,所有元组(node,query,1)被影响。
随机中断持续2到24小时,并且可能重叠。这些中断的目标是模拟各种各样的错误,一些可能是微妙的(少量查询显示异常结果),而其它更为明显(整个节点显示异常结果)。重要的是,这些中断从相同动态范围采集,以作为“good”分布:他们不是极大的数量级,或具有更广泛的传播(这将是相当容易发现的)。相反,分布是非常类似的,只是不同于稳态“good”分布,使它们相当微妙的发现。
发现中断:
OK ,说的足够多了,让我们看一些我们数据的图表。我们早期看的图表,它是模拟一个月时间所有数据的最小/最大/平均值。我模拟了30个节点,500个查询以及5个指标,每个小时轮询600点钟。那将每小时生成75,000个数据点,总共45万个。
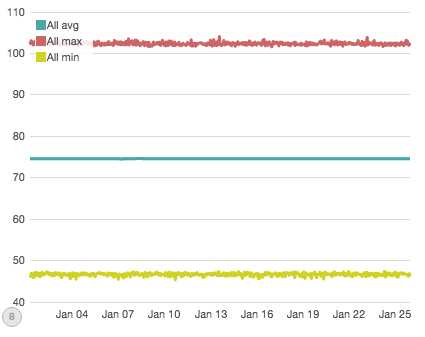
我们已经知道这个图不是超级有用,所以让我们尝试对数据进行分区,以获得更多洞察力。下一个图表展示了Metric #0,它经历了两次直接中断(例如,涉及到Metric #0的所有节点/查询部分都受影响,每小时总共15K中断数据点,每次中断持续几小时)。
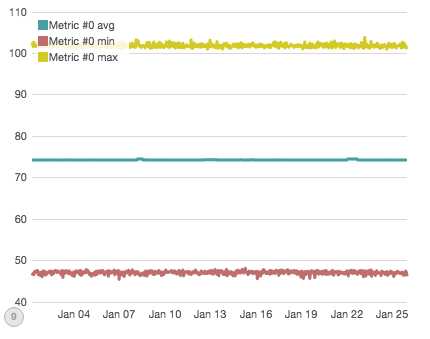
假如你眯起眼睛,在平均值上你可以看到两个颠簸。这两个颠簸确实有模拟中断造成的,但是仅仅第二个颠簸实际上由于Metric #0直接中断(outage)。第一个颠簸是由于不同的中断导致的。我们正在寻找的另一个直接中断Metric #0在这里是不可见的。
OK,让我们尝试最后一次,假如我告诉你查询#204会有一个直接中断,所有涉及到#204的节点/指标都会受到影响?你能在这张图标中发现它吗?
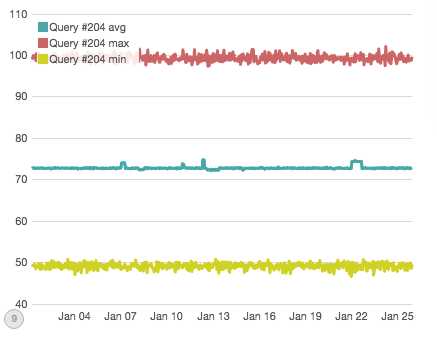
嗯,你可以看到一些中断平均值,但是这些没有一个是直接中断(他们与其它中断个别节点或指标有关)。
OK,所以在这个点上,我想你可以领会到这些中断的微妙之处。他们非常小,即使有时你已经预知要查看那个图标,可能也很难确定错误。假如你知道一个中断正在发生,你必须监视所有个别的时间序列(这在eBay的刻度上是不可行的)。
Implementing Atlas in Elasticsearch
第一步是设计一组聚合,这是最终查询,我们将逐步介绍:
{
"query": {
"filtered": {
"filter": {
"range": {
"hour": {
"gte": "{{start}}",
"lte": "{{end}}"
}
}
}
}
},
"size": 0,
"aggs": {
"metrics": {
"terms": {
"field": "metric",
“size”: 5
},
"aggs": {
"queries": {
"terms": {
"field": "query",
"size": 500
},
"aggs": {
"series": {
"date_histogram": {
"field": "hour",
"interval": "hour"
},
"aggs": {
"avg": {
"avg": {
"field": "value"
}
},
"movavg": {
"moving_avg": {
"buckets_path": "avg",
"window": 24,
"model": "simple"
}
},
"surprise": {
"bucket_script": {
"buckets_path": {
"avg": "avg",
"movavg": "movavg"
},
"script": "(avg - movavg).abs()"
}
}
}
},
"largest_surprise": {
"max_bucket": {
"buckets_path": "series.surprise"
}
}
}
},
"ninetieth_surprise": {
"percentiles_bucket": {
"buckets_path": "queries>largest_surprise",
"percents": [
90.0
]
}
}
}
}
}
}
它很长,但不是特别复杂。让我们开始独立查看组件。首先,在一个时间范围内我们通过一个简单的过滤查询设定了查询的范围(或在2.0版本可以使用bool+filter)。我们将使用它在我们数据中的每一个24小时窗口生成数据点:
"query": {
"filtered": {
"filter": {
"range": {
"hour": {
"gte": "{{start}}",
"lte": "{{end}}"
}
}
}
}
},
下一个是聚合,它是所有大量的举措发生的地方(all the heavy lifting takes place)。该聚合在指标和查询上采用两层项(terms)聚合:
"aggs": {
"metrics": {
"terms": {
"field": "metric"
},
"aggs": {
"queries": {
"terms": {
"field": "query",
"size": 500
},
"aggs": {
"series": {
"date_histogram": {
"field": "hour",
"interval": "hour"
},
我们希望每一个指标都有单一的“surprise值”。所以我们第一个聚合是一个“指标”上的terms。其次,通过查询我们需要区分每一个term(并且询问所有500个查询)。最后,对于每个查询,我们需要为过去24生成一个数据窗口,它意味着我们需要一个小时日期柱状图。
在这个点上,对于我们查询中定义的任何给定日期范围,我们每一个指标都有一个每个查询的时间序列。这将生成60,000个buckets(5 指标 * 500 查询 * 24 小时),这些将被用来计算我们实际的统计。
在完成bucketing之后,我们可以统计计算嵌入到日期柱状图内。
"avg": {
"avg": {
"field": "value"
}
},
"movavg": {
"moving_avg": {
"buckets_path": "avg",
"window": 24,
"model": "simple"
}
},
"surprise": {
"bucket_script": {
"buckets_path": {
"avg": "avg",
"movavg": "movavg"
},
"script": "(avg - movavg).abs()"
}
}
在这里我们计算每个bucket的平均值,它将执行折叠(“collapse”)所有数据到我们可以使用的单独小时值。然后,我们定义一个移动平均管道组合(Moving Average Pipeline aggregation)。该移动平局值采用bucket值的平均值(因为buckets_path指向"avg")并且使用24小时周期的简单平均值。
在Atlas paper中,eBay实际使用移动中值替代平均值。我们没有移动中值(yet!)。但我发现简单平均值工作非常好。这里使用simple平均值替代加权变化,因为我们不希望任何时间基数的加权,我们实际仅仅希望窗口的平均值。
下一步,我们定义“surprice”聚合,它计算每一个bucket偏差的平均值。它通过使用从移动平均值中减去平均值的Bucket Script pipeline聚合,然后获取绝对值(这允许我们检测正的和负的意外)。
该surprise metric是每个时间序列的最后目标。因为surprise是平均值的偏差,当某些事情改变的时候,它是一个好的指标。如果一个系列的平均值是10 +/-5,并且值突然开始记录为15 +/-5,该surpise会有一个高峰,因为它偏离了之前的平均值。在短暂的异常值中,这将很快被平滑了。但是当一个实际的中断发生并且趋势改变的时候,该surprise将提醒我们。
Collecting the relevant data
Atlas paper并不在乎所有的surpise值,它仅仅想要高位第90个百分位数。高位第90个百分位数代表了“最surprising”的surprise。所以我们需要从我们巨大的计算suprise列表中提取出来。
Atlas设计从每个序列获取最近的surprise值,找到第90个百分位数的surprise并记录他们。不幸的是,这对于pipeline聚合来说还不太可能。我们还没有一种方式在一个序列中指定“最”bucket(虽然我将来打开了一个标签来包含这个功能)。
相反,我们从序列“骗取”并记录最大的surprise,它作为一个可接受的代理来工作。然后我们可以累积所有最大值并找到第90个百分位数。
"largest_surprise": {
"max_bucket": {
"buckets_path": "series.surprise"
}
}
}
},
"ninetieth_surprise": {
"percentiles_bucket": {
"buckets_path": "queries>largest_surprise",
"percents": [
90.0
]
}
}
}
}
}
}
总结结论,最后的结果是,对于每个指标,我们将有单个"ninetieth_surprise”值,它代表每个指标中查询中最大的surprise值的第90个百分位数。该聚合通过60,000个bucket来计算5个聚合值。
这5个聚合值是我们将在下一步中使用到的数据。
To be continued
这篇文章已经很长了,所以我们将在下周恢复。这个聚合使我们实现了80%的Atlas。下一步是采用这些计算的第90个百分点指标,并绘制图标,以及当他们“超出界限”时提醒。
Footnotes
- Rust Simulator code (a very fast‘n‘dirty Rust program, please don‘t judge it too harshly!)
- Statistical Anomaly Detection — eBay‘s Atlas Anomaly Detector
- Goldberg, David, and Yinan Shan. "The importance of features for statistical anomaly detection." Proceedings of the 7th USENIX Conference on Hot Topics in Cloud Computing. USENIX Association, 2015.
原文地址:https://www.elastic.co/blog/implementing-a-statistical-anomaly-detector-part-1
以上是关于在Elasticsearch中实现统计异常检测器——第一部分的主要内容,如果未能解决你的问题,请参考以下文章