Apache流处理框架对比
Posted Emma
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Apache流处理框架对比相关的知识,希望对你有一定的参考价值。
分布式流处理,类似于MapReduce这样的通用计算模型,但是却要求它能够在毫秒级别或者秒级别完成响应。这些系统可以用DAG表示流处理的拓扑。
Points of Interest
在比较不同系统是,可以参照如下几点
- Runtime and Programming model(运行与编程模型)
一个平台提供的编程模型往往会决定很多它的特性,并且这个编程模型应该足够处理所有可能的用户案例。
- Functional Primitives(函数式单元)
一个合格的处理平台应该能够提供丰富的能够在独立信息级别进行处理的函数,像map、filter这样易于实现与扩展的一些函数。同样也应提供像aggregation这样的跨信息处理函数以及像join这样的跨流进行操作的函数,虽然这样的操作会难以扩展。
- State Management(状态管理)
- Message Delivery Guarantees(消息投递的可达性保证)
- at most once
- at least once
- exactly once
一般来说,对于消息投递而言,我们有至多一次(at most once)、至少一次(at least once)以及恰好一次(exactly once)这三种方案。
- Failures Handling
在一个流处理系统中,错误可能经常在不同的层级发生,譬如网络分割、磁盘错误或者某个节点莫名其妙挂掉了。平台要能够从这些故障中顺利恢复,并且能够从最后一个正常的状态继续处理而不会损害结果。
除此之外,我们也应该考虑到平台的生态系统、社区的完备程度,以及是否易于开发或者是否易于运维等等。
Runtime and Programming Model
运行环境和编程模型确定了系统的能力和使用的用户案例。因为它定义了整个系统的呈现特性、可能支持的操作以及未来的一些限制等等。
目前,主要有两种不同的方法来构建流处理系统
1) 其中一个叫Native Streaming,意味着所有输入的记录或者事件都会根据它们进入的顺序一个接着一个的处理。
优点:响应延迟较短
缺点:吞吐量较低;因为需要去持久化所以容错代价更高;负载均衡也是不容忽视的问题
2)另一种方法叫做Micro-Batching。大量短的Batches会从输入的记录中创建出然后经过整个系统的处理,这些Batches会根据预设好的时间常量进行创建,通常是每隔几秒创建一批。
优点:容错和负载均衡更易实现
缺点:一些类似于状态管理的或者joins、splits这些操作也会更加难以实现,因为系统必须去处理整个Batch
而就编程模型而言,又可以分为Compositional(组合式)与Declarative(声明式)。
1)组合式会提供一系列的基础构件,类似于源读取与操作符等等,开发人员需要将这些基础构件组合在一起然后形成一个期望的拓扑结构。新的构件往往可以通过继承与实现某个接口来创建。
2)另一方面,声明式API中的操作符往往会被定义为高阶函数。声明式编程模型允许我们利用抽象类型和所有其他的精选的材料来编写函数式的代码以及优化整个拓扑图。同时,声明式API也提供了一些开箱即用的高等级的类似于窗口管理、状态管理这样的操作符。
Apache Streaming Landscape
目前已经有了各种各样的流处理框架,自然也无法在本文中全部攘括。所以我必须将讨论限定在某些范围内,本文中是选择了所有Apache旗下的流处理的框架进行讨论,并且这些框架都已经提供了Scala的语法接口。主要的话就是Storm以及它的一个改进Trident Storm,还有就是当下正火的Spark。最后还会讨论下来自LinkedIn的Samza以及比较有希望的Apache Flink。笔者个人觉得这是一个非常不错的选择,因为虽然这些框架都是出于流处理的范畴,但是他们的实现手段千差万别。
-
Apache Storm 最初由Nathan Marz以及他的BackType的团队在2010年创建。后来它被Twitter收购并且开源出来,并且在2014年变成了Apache的顶层项目。毫无疑问,Storm是大规模流处理中的先行者并且逐渐成为了行业标准。Storm是一个典型的Native Streaming系统并且提供了大量底层的操作接口。另外,Storm使用了Thrift来进行拓扑的定义,并且提供了大量其他语言的接口。
-
Trident 是一个基于Storm构建的上层的Micro-Batching系统,它简化了Storm的拓扑构建过程并且提供了类似于窗口、聚合以及状态管理等等没有被Storm原生支持的功能。另外,Storm是实现了至多一次的投递原则,而Trident实现了恰巧一次的投递原则。Trident 提供了 Java, Clojure 以及 Scala 接口。
-
众所周知,Spark是一个非常流行的提供了类似于SparkSQL、Mlib这样内建的批处理框架的库,并且它也提供了Spark Streaming这样优秀地流处理框架。Spark的运行环境提供了批处理功能,因此,Spark Streaming毫无疑问是实现了Micro-Batching机制。输入的数据流会被接收者分割创建为Micro-Batches,然后像其他Spark任务一样进行处理。Spark 提供了 Java, Python 以及 Scala 接口。
-
Samza最早是由LinkedIn提出的与Kafka协同工作的优秀地流解决方案,Samza已经是LinkedIn内部关键的基础设施之一。Samza重负依赖于Kafaka的基于日志的机制,二者结合地非常好。Samza提供了Compositional接口,并且也支持Scala。
-
最后聊聊Flink. Flink可谓一个非常老的项目了,最早在2008年就启动了,不过目前正在吸引越来越多的关注。Flink也是一个Native Streaming的系统,并且提供了大量高级别的API。Flink也像Spark一样提供了批处理的功能,可以作为流处理的一个特殊案例来看。Flink强调万物皆流,这是一个绝对的更好地抽象,毕竟确实是这样。
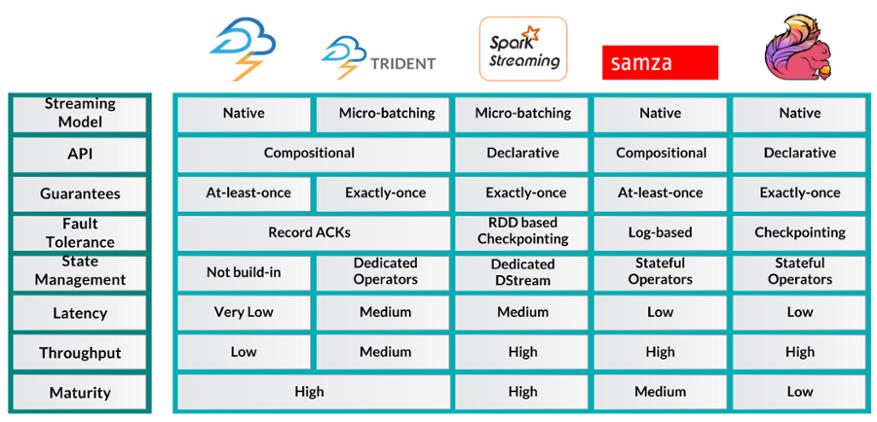
下表就简单列举了上述几个框架之间的特性:
Reference
Rhttps://segmentfault.com/a/1190000004593949?_ea=665564
以上是关于Apache流处理框架对比的主要内容,如果未能解决你的问题,请参考以下文章