python读取较大数据文件
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python读取较大数据文件相关的知识,希望对你有一定的参考价值。
参考技术A常用方式一:
上述方式不会一次性读取整个文件,类似buffer机制。
对可迭代对象 f,进行迭代遍历: for line in f ,会自动地使用缓冲IO(buffered IO)以及内存管理。
方式二:
自己实现类似于buffer:
== 不适合的方法 ==
python读取16G文件CSV数据。
😢今天应大家的需求,给大家演示一下python读取较大的文件数据。
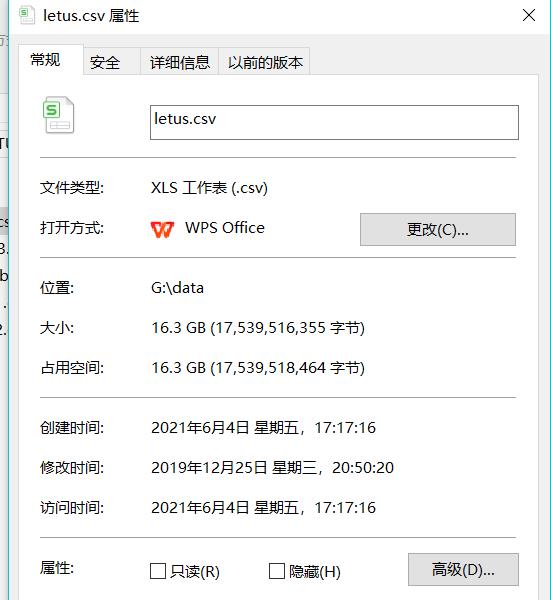
1.文件大小
给大家看看文件大小。
2.环境准备
2.1 你需要准备一个至少40G的空间
我们知道pandas无法一次性读取这么大的文件,但是sqlite3可以,并且python自带sqlites3,我们只需将其转化为 . d b .db .db结尾的文件。切记将下载的sqlite3和你的数据放在同一个文件夹里
- 点击sqlite3数据库
链接: sqlite3数据库文件.
提取码:a8oz

- 创建一个数据库
输入以下代码创建一个数据库。
.open test.db --前面要加点,名字随便
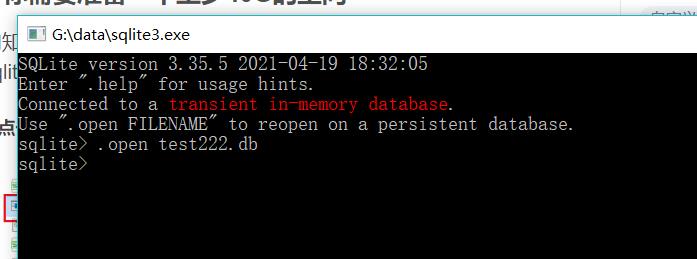
在你的文件下面就会出现一个test222.db文件,这个是数据库文件。
2.2 转换数据
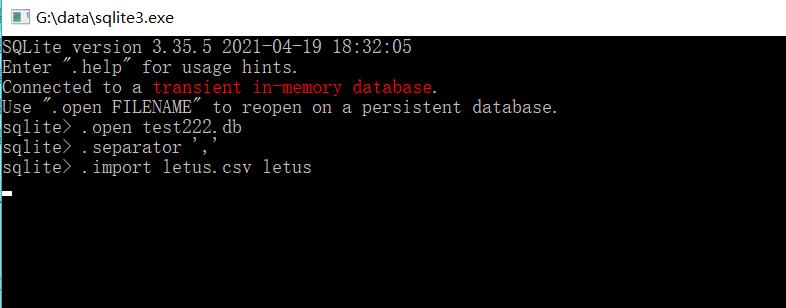
我们上一步创建了数据库后,还需要在数据库中创建table这样数据才能导入tabel ,但是在导入数据之前,需要说明一下数据的切割方式。
--以逗号为分割符切割数据
.separator ','
--将数据导入table
.import letus.csv letus
敲完这些,就等待20分钟吧,程序会将数据读取到letus的表中。
我这里就不读了,太大了,已经读过一次啦,大家等他读完就行!
3.python读取数据
import sqlite3
import pandas as pd
#创建数据库连接 (你们刚才生成db文件的地方)
conn=sqlite3.connect("G:\\\\data\\\\test02.db")
a=conn.execute("select * from letus limit 5")#我这里只展示5条数据
for row in a:#依次展示
print(row)
读出来的效果如下:

4.总结
也就是说,我们操作这么大的数据只能用SQL语句了😢,千万不要selelct*!!! 显示结果一定要加limit!
以上是关于python读取较大数据文件的主要内容,如果未能解决你的问题,请参考以下文章