Paper Reading 4:Massively Parallel Methods for Deep Reinforcement Learning
Posted songrotek
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Paper Reading 4:Massively Parallel Methods for Deep Reinforcement Learning相关的知识,希望对你有一定的参考价值。
来源:ICML 2015 Deep Learning Workshop
作者:Google DeepMind
创新点:构建第一个用于深度增强学习的大规模分布式结构
该结构由四部分组成:
- 并行的行动器:用于产生新的行为
- 并行的学习器:用于从存储的经验中训练
- 分布式的神经网络:用于表示value function或者policy
- 分布式的经验存储
实验结果:
将DQN应用在该体系结构上,训练的水平在49个游戏中有41个游戏超过没有分布式DQN的水平,并且减少了训练时间
优点:
- 训练效果更好
- 训练时间更短
缺点:
- 并行分布式主要缺点恐怕是能耗高,造价昂贵,门槛高了。一般人没办法搞这个
可改进之处:
主要需要改进的是算法层面。比如DQN一次只训练一个游戏,能不能同时训练多个同一个游戏来提升速度?
详细分析:
Introduction 介绍
再看这些介绍,就有点废话了:Deep Learning 在视觉和语音上取得了巨大的进展,归因于能够自动的提取高level的特征。当前增强学习成功地结合了深度学习的成果,也就是DQN,在Atari 游戏上取得breakthrough。
但是,问题来了(引出动机Motivation)
之前的DQN只是在单个机器上训练,需要消耗大量的训练时间,因此,目标出来了:建立一个分布式的结构从而能够充分利用当前的计算资源提升计算速度。
深度学习本身就比较容易并行处理。采用GPU加速。这一方面主要研究的就是如何使用大规模的并行计算来训练巨量的数据,从而取得更好的训练效果。这方面不管Google还是Baidu都在做。
机会在于:还没有人做增强学习系统,所以,把DQN并行化显然值得一做!
增强学习的一个特点是agent会因为和环境交互导致训练的数据分布不一样。所以,依然是很自然的想法:弄多个agent并行的训练 每个agent各种存储自己的经验到经验池,那么就是分布式的经验池了。这将使整个经验池的容量大大增加!并且不同的agent还可以用不同的policy来获取不同的经验。想想都兴奋呀!
接下来就是分布式的学习器(好多个)从不同经验池中学习,更新网络的参数。所以,连参数都是分布式的。那么,问题是最终的参数的如何合并的??
这就是Google DeepMind的成果了:Gorila(General Reinforcement Learning Architecture)也就是通用增强学习结构。更快更强!
个人思考:不管是那一个研究,都是循序渐进,一步一步走。那么对于之前的外行只是因为热爱才进入这个领域,又没有指导,自能自己摸索的人,到底应该怎么做才能赶上并找到好的切入点并做出好的成果呢?当然了,DRL这个领域有太多能做的,随便一个和决策及控制相关的问题都可以结合。But we want to make it general!!
Related Work相关工作
这部分就是查查资料看看以前有没有并行RL的工作,显然也是会有的。介绍一下他们的工作罗:
- Distributed multi-agent systems:就是多个agent共同作用在一个环境中,通过协作来获取共同的目标。所以,他们的算法更多关注的是有效的teamwork及整体行为
- Concurrent reinforcement learning:并发增强学习。就是一个agent作用在多个分布环境中(平行宇宙呀)
这里的方法和上面不一样,只是想通过使用并行计算来提升single-agent problem的效率。
- MapReduce Framework:不知道是神马得看论文,主要局限于linear function approximation。
最后是最接近的工作:
- 并行的Sarsa算法。每个计算机有单独的agent和环境,运行简单的linear sarsa算法。参数周期性的互相通信,聚焦与那些改变最多的参数。
对比本文的方法,就是允许客户端-服务器的通信,并且将动作,学习和参数更新三部分分开。当然,最重要的就是应用深度学习。
Background
DistBelief
Google 的分布式深度学习系统,主要体现在
1. Model parallelism 模型并行。不同的机器训练模型的不同部分
2. Data parallelism 数据并行。同一个模型训练数据的不同部分。
DQN
在之前的文章中已分析,不再重复。
Gorila (General Reinforcement Learning)
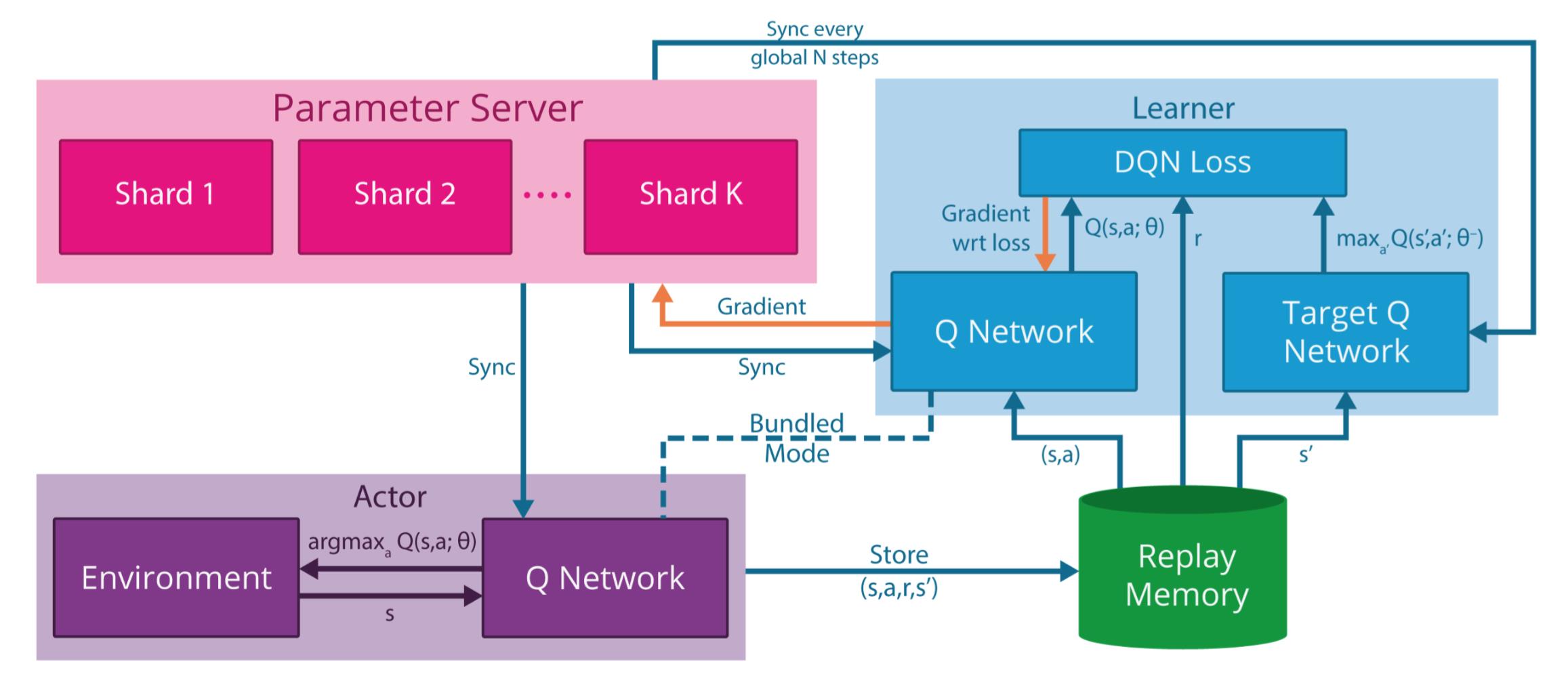
上图即为Gorila的结构图,分成以下几部分:
- Actors 行为器。就是选择动作执行。Gorila里面有N个不同的动作进程,每个actor在相同的环境中产生各自不同的动作系列。当然,也因此,得到的状态空间state space也是不同的。每个actor都复制一份Q-network用于生成动作,Q-network的参数周期性的从参数服务器中同步。
- Experience replay memory 经验池。把每个actor的状态动作系列都存起来。总的replay memory就可以根据需要进行裁剪。
- Learners 学习器。Gorila包含N个学习器进程。每一个也都复制一个Q-network。每一个学习器从经验池中采样数据。学习器应用off-policy增强学习算法比如DQN。然后获得的梯度传送给parameter server进行参数更新。
- Parameter server 参数服务器。参数服务器存储N个版本的Q-network在不同的机器上。每个机器只应用梯度更新部分参数。采用异步随机梯度下降asynchronous stochastic gradient descent算法。
Gorila DQN

上面的描述看起来会比较长,实际上就仅仅是将分布式加入到算法当中。对于DQN没有任何改变。主要需要考虑的就是不同机器上的参数如何协调更新的问题,要保证系统的稳定性。
实验
很显然的,分布式版本会比单机版的效果更好,两个原因:
- 训练时间相对单机有巨大提升。
- 参数更新上和单机版本的不同,是部分更新,每个机器上更新的参数不一样。这种异步更新对结果会有一定影响。而且这里采用AdaGra而不是RMSProp
所以,结果上看虽然大部分的游戏效果都更好,但也有一些游戏效果反而差了。
这也说明不同探索游戏空间的方式对游戏会产生较大的变化。
事实上DQN之后的一些版本都没能做到对每个游戏的水平都提升。这也是个值得深入探讨的问题。
小结
Gorila是第一个大规模的分布式深度增强学习框架,当然了并没有开源。Gorila的学习和动作执行都是并行的,采用分布式的经验池和分布式的神经网络。采用Gorila说明了在加大计算力的情况下,算法水平能够得到大的提升,这印证了深度学习在增加计算力和时间的情况下看不到上限的情况。
以上是关于Paper Reading 4:Massively Parallel Methods for Deep Reinforcement Learning的主要内容,如果未能解决你的问题,请参考以下文章
Testing & Paper reading——Sketchvisor