K8S基础概念
Posted MKY-技术驿站
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了K8S基础概念相关的知识,希望对你有一定的参考价值。
一、核心概念
1、Node
Node作为集群中的工作节点,运行真正的应用程序,在Node上Kubernetes管理的最小运行单元是Pod。Node上运行着Kubernetes的Kubelet、kube-proxy服务进程,这些服务进程负责Pod的创建、启动、监控、重启、销毁、以及实现软件模式的负载均衡。
Node包含的信息:
- Node地址:主机的IP地址,或Node ID。
- Node的运行状态:Pending、Running、Terminated三种状态。
- Node Condition:…
- Node系统容量:描述Node可用的系统资源,包括CPU、内存、最大可调度Pod数量等。
- 其他:内核版本号、Kubernetes版本等。
查看Node信息:
kubectl describe node
2、Pod
Pod是Kubernetes最基本的操作单元,包含一个或多个紧密相关的容器,一个Pod可以被一个容器化的环境看作应用层的“逻辑宿主机”;一个Pod中的多个容器应用通常是紧密耦合的,Pod在Node上被创建、启动或者销毁;每个Pod里运行着一个特殊的被称之为Pause的容器,其他容器则为业务容器,这些业务容器共享Pause容器的网络栈和Volume挂载卷,因此他们之间通信和数据交换更为高效,在设计时我们可以充分利用这一特性将一组密切相关的服务进程放入同一个Pod中。
同一个Pod里的容器之间仅需通过localhost就能互相通信。

一个Pod中的应用容器共享同一组资源:
- PID命名空间:Pod中的不同应用程序可以看到其他应用程序的进程ID;
- 网络命名空间:Pod中的多个容器能够访问同一个IP和端口范围;
- IPC命名空间:Pod中的多个容器能够使用SystemV IPC或POSIX消息队列进行通信;
- UTS命名空间:Pod中的多个容器共享一个主机名;
- Volumes(共享存储卷):Pod中的各个容器可以访问在Pod级别定义的Volumes;
Pod的生命周期通过Replication Controller来管理;通过模板进行定义,然后分配到一个Node上运行,在Pod所包含容器运行结束后,Pod结束。
Kubernetes为Pod设计了一套独特的网络配置,包括:为每个Pod分配一个IP地址,使用Pod名作为容器间通信的主机名等。
3、Service
在Kubernetes的世界里,虽然每个Pod都会被分配一个单独的IP地址,但这个IP地址会随着Pod的销毁而消失,这就引出一个问题:如果有一组Pod组成一个集群来提供服务,那么如何来访问它呢?Service!
一个Service可以看作一组提供相同服务的Pod的对外访问接口,Service作用于哪些Pod是通过Label Selector来定义的。
- 拥有一个指定的名字(比如my-mysql-server);
- 拥有一个虚拟IP(Cluster IP、Service IP或VIP)和端口号,销毁之前不会改变,只能内网访问;
- 能够提供某种远程服务能力;
- 被映射到了提供这种服务能力的一组容器应用上;
如果Service要提供外网服务,需指定公共IP和NodePort,或外部负载均衡器;
NodePort
系统会在Kubernetes集群中的每个Node上打开一个主机的真实端口,这样,能够访问Node的客户端就能通过这个端口访问到内部的Service了
4、Volume
Volume是Pod中能够被多个容器访问的共享目录。
5、Label
Label以key/value的形式附加到各种对象上,如Pod、Service、RC、Node等,以识别这些对象,管理关联关系等,如Service和Pod的关联关系。
6、RC(Replication Controller)
- 目标Pod的定义;
- 目标Pod需要运行的副本数量;
- 要监控的目标Pod标签(Lable);
Kubernetes通过RC中定义的Lable筛选出对应的Pod实例,并实时监控其状态和数量,如果实例数量少于定义的副本数量(Replicas),则会根据RC中定义的Pod模板来创建一个新的Pod,然后将此Pod调度到合适的Node上启动运行,直到Pod实例数量达到预定目标。
二、Kubernetes总体架构
Master和Node
Kubernetes将集群中的机器划分为一个Master节点和一群工作节点(Node)。其中,Master节点上运行着集群管理相关的一组进程etcd、API Server、Controller Manager、Scheduler,后三个组件构成了Kubernetes的总控中心,这些进程实现了整个集群的资源管理、Pod调度、弹性伸缩、安全控制、系统监控和纠错等管理功能,并且全都是自动完成。在每个Node上运行Kubelet、Proxy、Docker daemon三个组件,负责对本节点上的Pod的生命周期进行管理,以及实现服务代理的功能。
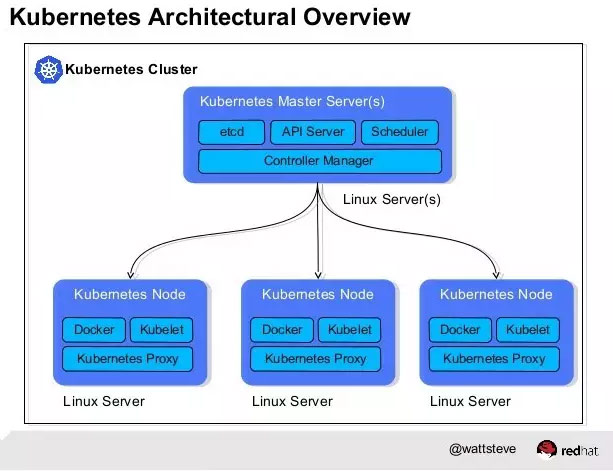
流程
通过Kubectl提交一个创建RC的请求,该请求通过API Server被写入etcd中,此时Controller Manager通过API Server的监听资源变化的接口监听到这个RC事件,分析之后,发现当前集群中还没有它所对应的Pod实例,于是根据RC里的Pod模板定义生成一个Pod对象,通过API Server写入etcd,接下来,此事件被Scheduler发现,它立即执行一个复杂的调度流程,为这个新Pod选定一个落户的Node,然后通过API Server讲这一结果写入到etcd中,随后,目标Node上运行的Kubelet进程通过API Server监测到这个“新生的”Pod,并按照它的定义,启动该Pod并任劳任怨地负责它的下半生,直到Pod的生命结束。
随后,我们通过Kubectl提交一个新的映射到该Pod的Service的创建请求,Controller Manager会通过Label标签查询到相关联的Pod实例,然后生成Service的Endpoints信息,并通过API Server写入到etcd中,接下来,所有Node上运行的Proxy进程通过API Server查询并监听Service对象与其对应的Endpoints信息,建立一个软件方式的负载均衡器来实现Service访问到后端Pod的流量转发功能。
-
etcd
用于持久化存储集群中所有的资源对象,如Node、Service、Pod、RC、Namespace等;API Server提供了操作etcd的封装接口API,这些API基本上都是集群中资源对象的增删改查及监听资源变化的接口。 -
API Server
提供了资源对象的唯一操作入口,其他所有组件都必须通过它提供的API来操作资源数据,通过对相关的资源数据“全量查询”+“变化监听”,这些组件可以很“实时”地完成相关的业务功能。 -
Controller Manager
集群内部的管理控制中心,其主要目的是实现Kubernetes集群的故障检测和恢复的自动化工作,比如根据RC的定义完成Pod的复制或移除,以确保Pod实例数符合RC副本的定义;根据Service与Pod的管理关系,完成服务的Endpoints对象的创建和更新;其他诸如Node的发现、管理和状态监控、死亡容器所占磁盘空间及本地缓存的镜像文件的清理等工作也是由Controller Manager完成的。 -
Scheduler
集群中的调度器,负责Pod在集群节点中的调度分配。 -
Kubelet
负责本Node节点上的Pod的创建、修改、监控、删除等全生命周期管理,同时Kubelet定时“上报”本Node的状态信息到API Server里。 -
Proxy
实现了Service的代理与软件模式的负载均衡器。
客户端通过Kubectl命令行工具或Kubectl Proxy来访问Kubernetes系统,在Kubernetes集群内部的客户端可以直接使用Kuberctl命令管理集群。Kubectl Proxy是API Server的一个反向代理,在Kubernetes集群外部的客户端可以通过Kubernetes Proxy来访问API Server。
API Server内部有一套完备的安全机制,包括认证、授权和准入控制等相关模块。
以上是关于K8S基础概念的主要内容,如果未能解决你的问题,请参考以下文章