关于图论的若干巴拉巴拉
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了关于图论的若干巴拉巴拉相关的知识,希望对你有一定的参考价值。
最近课堂上正在讲图论
先安利MIT课程:http://open.163.com/special/opencourse/algorithms.html
因为本人对图论的概念并不是很清楚,所以还是整理一下吧。
1.图论的基本概念
几种常见的图的分类:
| 类型 | 边 | 允许多重边 | 允许环 |
| 简单图 | 无向 | 否 | 否 |
| 多重图 | 无向 | 是 | 否 |
| 伪图 | 无向 | 是 | 是 |
| 有向图 | 有向 | 否 | 是 |
| 有向多重图 | 有向 | 是 | 是 |
完全图:n个顶点上的完全图是在每对不同顶点之间都恰有一条边的简单图。
二分图:若把简单图G的顶点集合分为两个不相交的非空集合V1和V2,使得图里的每一条边都连接着V1里的一个顶点和V2里的一个顶点(因此G里面没有边是连接着V1里的两个顶点或V2里的两个顶点),则G称为二分图(从定义中可以看出,二分图必无环,但可以有多重边)。
用标号法可以方便地判断一个图是否是二分图:
首先给任意一个顶点标上A,与标记A的顶点邻接的顶点标上B,再将标记为B的顶点邻接的顶点标记上A,续行此法,如果这个过程可以完成,使得没有相邻的顶点标上相同的字母,则该图是二分图,否则它就不是二分图。
另:如果标记成功,可以将两个顶点子集X与Y中的顶点分开画,与原图形形成一个同构图,这样可以直接地看出它是一个二分图。
完全二分图:设G是一个二分图,若G是一个简单图,并且X中的每个顶点与Y中的每个顶点均邻接,则称G为完全二分图。
易知,完全二分图中共有|X|·|Y|条边。
图的表示和图的同构:
常见的图的表示方式:边表、相邻矩阵(简单图的相邻矩阵是对称的0-1矩阵,当出现环或多重边时,矩阵对称但不是0-1矩阵,此时第(i, j)项是与{vi, vj}关联的边数。另外,有向图的相邻矩阵不必是对称的)、关联矩阵(顶点与边的n*m矩阵,用相等项的列来表示多重边,恰有一项等于1的列来表示环)。
同构:当两个简单图同构时,两个图的顶点之间具有保持相邻关系的一一对应(注意:同构的图是等价的图,只是画的方式不同而已)。
容易看出,两图同构的必要条件有:顶点数相等、边数相等、度数相同的顶点数相等(总的顶点度更得相等)。遗憾的是,目前尚没有用来判定简单图是否同构的不变量集。
连通性:
通路:在无向图里从顶点u到v的路径。
回路:若一条通路在相同的顶点上开始和结束,则它是一条回路。
简单通路(回路):若一条通路(或回路)不重复地包含相同的边,则它是简单的。
无向图连通性:若无向图里每一对不同的顶点之间都有通路,则该图称为连通的。
有向图连通性:根据是否考虑边的方向:有向图里由两种连通性概念。
强连通:每当a和b都是一个有向图里的顶点时,就有从a到b和从b到a的通路。
弱连通:在有向图的底图(底图:有向图忽略边的方向后得出的无向图)里,任何两个顶点之间都有通路。
显然,任何强连通的有向图也是弱连通的。
连通分支:不连通的图是两个或两个以上连通子图之并,每一对子图都没有公共顶点,这些不相交的连通子图称为图的连通分支。
由连通性引发的几个概念:
割点:如果删除一个顶点和它所关联的边,该图的连通分支增加,这样的顶点就叫做割点。
割边:把一旦删除就产生比原图更多的连通分支的子图的边称为割边(或桥)。
参考博客:http://www.cnblogs.com/xpjiang/p/4401426.html
2.详细讲述一下这星期学的知识点
①图的表示
1 邻接矩阵 ,对于N个点的图,需要N×N的矩阵表示点与点之间是否有边的存在。这种表示法的缺点是浪费空间,尤其是对于N×N的矩阵是稀疏矩阵,即边的数目远远小于N×N的时候,浪费了巨大的存储空间。

2 邻接链表,对于任何一个node A,外挂一个邻接链表,如果存在 A->X这样的边,就将X链入链表。 这种表示方法的优点是节省空间,缺点是所有链表都存在的缺点,地址空间的不连续造成缓存命中降低,性能有不如临界矩阵这样的数组。

②图的DFS遍历
基本思想:
从图中某顶点V0出发,访问此顶点,然后依次从V0的各个未被访问的邻接点出发深度优先搜索遍历图,直至图中所有和V0有路径相通的顶点都被访问到;
若此时图中尚有顶点未被访问,则另选图中一个未曾被访问的顶点作起始点;
重复上述过程,直至图中所有顶点都被访问到为止。
分析:
在遍历图时,对图中每个顶点至多调用一次DFS函数,因为一旦某个顶点被标志成已被访问,就不再从它出发进行搜索。
因此,遍历图的过程实质上是对每个顶点查找其邻接点的过程。其耗费的时间则取决于所采用的存储结构。 当使用二维数组表示邻接矩阵作图的存储结构时,查找每个顶点的邻接点所需时间为O(n^2),其中n为顶点数。而当以邻接表作图的存储结构时,找邻接点所需时间为O(e),其中e为无向图中边的数目或有向图中弧的数目。由此,当以邻接表作存储结构时,深度优先搜遍遍历图的时间复杂度为O(n+e)。
1 int v[N]={0}; 2 void dfs(int k) 3 { 4 v[k]=1; 5 for(i=0;i<N;i++) 6 if(a[k][i]==1&&!v[i]) 7 dfs(i); 8 }
3.有根树的LCA(Tarjan)
这边有几个较为详细解释的链接(叫我安利小天使):
http://blog.csdn.net/ywcpig/article/details/52336496
http://blog.csdn.net/u014679804/article/details/48000523
解法一:暴力
1 int query(Node t, Node u, Node v) 2 { 3 int left = u.value; 4 int right = v.value; 5 //二叉查找树内,如果左结点大于右结点,不对,交换 6 if (left > right) 7 { 8 int temp = left; 9 left = right; 10 right = temp; 11 } 12 while (true) 13 { 14 //如果t小于u、v,往t的右子树中查找 15 if (t.value < left) 16 { 17 t = t.right; 18 19 //如果t大于u、v,往t的左子树中查找 20 } 21 else if (t.value > right) 22 { 23 t = t.left; 24 } 25 else 26 { 27 return t.value; 28 } 29 } 30 }
解法二:Tarjan(离线)
1 const int mx = 10000; //最大顶点数 2 int n, root; //实际顶点个数,树根节点 3 int indeg[mx]; //顶点入度,用来判断树根 4 vector<int> tree[mx]; //树的邻接表(不一定是二叉树) 5 void inputTree() //输入树 6 { 7 scanf("%d", &n); //树的顶点数 8 for (int i = 0; i < n; i++) //初始化树,顶点编号从0开始 9 tree[i].clear(), indeg[i] = 0; 10 for (int i = 1; i < n; i++) //输入n-1条树边 11 { 12 int x, y; 13 scanf("%d%d", &x, &y); //x->y有一条边 14 tree[x].push_back(y); 15 indeg[y]++;//加入邻接表,y入度加一 16 } 17 for (int i = 0; i < n; i++) //寻找树根,入度为0的顶点 18 if (indeg[i] == 0) 19 { 20 root = i; 21 break; 22 } 23 } 24 vector<int> query[mx]; //所有查询的内容 25 void inputQuires() //输入查询 26 { 27 for (int i = 0; i < n; i++) //清空上次查询 28 query[i].clear(); 29 30 int m; 31 scanf("%d", &m); //查询个数 32 while (m--) 33 { 34 int u, v; 35 scanf("%d%d", &u, &v); //查询u和v的LCA 36 query[u].push_back(v); 37 query[v].push_back(u); 38 } 39 } 40 int father[mx], rnk[mx]; //节点的父亲、秩 41 void makeSet() //初始化并查集 42 { 43 for (int i = 0; i < n; i++) father[i] = i, rnk[i] = 0; 44 } 45 int findSet(int x) //查找 46 { 47 if (x != father[x]) father[x] = findSet(father[x]); 48 return father[x]; 49 } 50 void unionSet(int x, int y) //合并 51 { 52 x = findSet(x), y = findSet(y); 53 if (x == y) return; 54 if (rnk[x] > rnk[y]) father[y] = x; 55 else father[x] = y, rnk[y] += rnk[x] == rnk[y]; 56 } 57 int ancestor[mx]; //已访问节点集合的祖先 58 bool vs[mx]; //访问标志 59 void Tarjan(int x) //Tarjan算法求解LCA 60 { 61 for (int i = 0; i < tree[x].size(); i++) 62 { 63 Tarjan(tree[x][i]); //访问子树 64 unionSet(x, tree[x][i]); //将子树节点与根节点x的集合合并 65 ancestor[findSet(x)] = x;//合并后的集合的祖先为x 66 } 67 vs[x] = 1; //标记为已访问 68 for (int i = 0; i < query[x].size(); i++) //与根节点x有关的查询 69 if (vs[query[x][i]]) //如果查询的另一个节点已访问,则输出结果 70 printf("%d和%d的最近公共祖先为:%d\\n", x, 71 query[x][i], ancestor[findSet(query[x][i])]); 72 } 73 int main() 74 { 75 inputTree(); //输入树 76 inputQuires();//输入查询 77 makeSet(); 78 for (int i = 0; i < n; i++) 79 ancestor[i] = i; 80 memset(vs, 0, sizeof(vs)); 81 //初始化为未访问 82 Tarjan(root); 83 }
4.割点、割边(桥)
在一个无向连通图中,如果删除后某个顶点之后,图不再连通(即任意两点之间不能相互可达),这样的顶点叫做割点。
由此,删去某个顶点之后,然后进行一次dfs搜索一遍判断图是否还连通,便能求出该点是不是割点。
但是时间复杂度颇高。
所以,基于dfs搜索树设计了求割点的算法。
求割点可分为两种情况,
1. 求根节点的是否为割点,只要其有两棵或两棵以上子树,则为割点。
2. 叶节点都不是割点,所以只剩下要求非叶节点,若一非叶节点的子树的节点没有指向该点的祖先节点的回边,说明删除该点之后,该点的祖先节点与该点的子树不再连通,则说明该节点为割点。
使用dfs进行一次搜索,假设搜索结果是下图这样的,即1->3->2->4->5->6
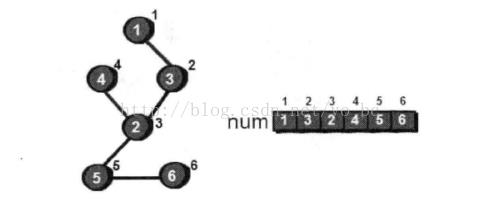
圆圈内代表节点编号,旁边的数值代表该顶点在进行遍历时是第几个被访问到的,我们称做时间戳,用num数组来进行存储每个顶点的时间戳。
当遍历至某个顶点时,判断剩余未访问的点在不经过该点的情况下能否回到在访问该点之前的任意一个点,可以形象地说成该点的儿子在不经过它这个父亲的情况下是否还能回到它的祖先。
所以我们在用一个low数组来记录每个顶点在不经过其父节点时,能够直接回到的最小 ‘时间戳‘,如图
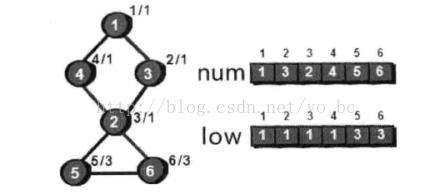
所以,对于某点u若至少存在一个儿子顶点v,使low[v] >= num[u],即不能回到祖先,则说明该点u为割点。
1 #include <algorithm> 2 #include <cstring> 3 #include <cstdio> 4 using namespace std; 5 struct node{ 6 int v, next; 7 }edge[4005]; 8 int head[1005], num[1005], low[1005], ans[1005]; 9 int n, m, no, index, root; 10 void add(int u, int v){ 11 edge[no].v = v; 12 edge[no].next = head[u]; 13 head[u] = no++; 14 } 15 void init(){ 16 no = 1, index = 0, root = 1; 17 memset(head, -1, sizeof head); 18 memset(ans, 0, sizeof ans); 19 memset(num, 0, sizeof num); 20 } 21 void dfs(int cur, int father){ 22 int child = 0; 23 ++index; 24 num[cur] = index; 25 low[cur] = index; 26 int k = head[cur]; 27 while(k != -1){ 28 if(num[edge[k].v] == 0){ 29 ++child; 30 dfs(edge[k].v, cur); 31 low[cur] = min(low[cur], low[edge[k].v]); 32 if(cur != root && low[edge[k].v] >= num[cur]) ans[cur] = 1; 33 if(child == 2 && cur == root) ans[cur] = 1; 34 } 35 else if(edge[k].v != father){ 36 low[cur] = min(low[cur], num[edge[k].v]); 37 } 38 k = edge[k].next; 39 } 40 } 41 int main(){ 42 int i, u, v; 43 scanf("%d %d", &n, &m); 44 init(); 45 for(i = 1; i <= m; ++i){ 46 scanf("%d %d", &u, &v); 47 add(u, v); 48 add(v, u); 49 } 50 dfs(root, root); 51 for(i = 1; i <= n; ++i) 52 if(ans[i]) printf("%d ", i); 53 printf("\\n"); 54 return 0; 55 }
求割边其实就需要将上面的代码稍加改动,将low[v] >= num[u]改为low[v] > num[u],因为这句代码代表该点的子节点在不经过其父亲节点回不到该点及该点的祖先的,所以u->v这条边是一条割边。
1 #include <algorithm> 2 #include <cstring> 3 #include <cstdio> 4 using namespace std; 5 struct node{ 6 int v, next; 7 }edge[4005]; 8 int head[1005], num[1005], low[1005], ans[1005]; 9 int n, m, no, index, root; 10 void add(int u, int v){ 11 edge[no].v = v; 12 edge[no].next = head[u]; 13 head[u] = no++; 14 } 15 void init(){ 16 no = 1, index = 0, root = 1; 17 memset(head, -1, sizeof head); 18 memset(ans, 0, sizeof ans); 19 memset(num, 0, sizeof num); 20 } 21 void dfs(int cur, int father){ 22 ++index; 23 num[cur] = index; 24 low[cur] = index; 25 int k = head[cur]; 26 while(k != -1){ 27 if(num[edge[k].v] == 0){ 28 dfs(edge[k].v, cur); 29 low[cur] = min(low[cur], low[edge[k].v]); 30 if(low[edge[k].v] > num[cur]) 31 printf("%d--%d\\n", cur, edge[k].v); 32 } 33 else if(edge[k].v != father){ 34 low[cur] = min(low[cur], num[edge[k].v]); 35 } 36 k = edge[k].next; 37 } 38 } 39 int main(){ 40 int i, u, v; 41 scanf("%d %d", &n, &m); 42 init(); 43 for(i = 1; i <= m; ++i){ 44 scanf("%d %d", &u, &v); 45 add(u, v); 46 add(v, u); 47 } 48 dfs(root, root); 49 return 0; 50 }
时间复杂度为O(M+N)
参考来源:http://m.blog.csdn.net/yo_bc/article/details/60780840
暂更新到这里。
讲一讲这一周的体验吧。
首先有点郁闷每天都要考试wwww (无奈脸) 不过考着考着大概就习惯了吧唔。
然后发现周围的oier们真是越来越可爱了呢,他们可以在机房里搞很多事情hhhh(#斜眼)
NOIP很快也要到了呢,不管怎么样,一路往前走吧。
我似乎越说越乱了,感觉这几天思绪的确很乱,所以需要好好整理一下,结果也整的乱七八糟。
天气燥热,不过是晴好的天气。
我们不说话/这样就很好。
(真是越说越乱了我也不知道该说什么了就这样吧唔)
G.N. to world.——Hathaway
2017-07-07
以上是关于关于图论的若干巴拉巴拉的主要内容,如果未能解决你的问题,请参考以下文章