spark 教程二 spark中的一些术语和概念
Posted jialiming
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了spark 教程二 spark中的一些术语和概念相关的知识,希望对你有一定的参考价值。
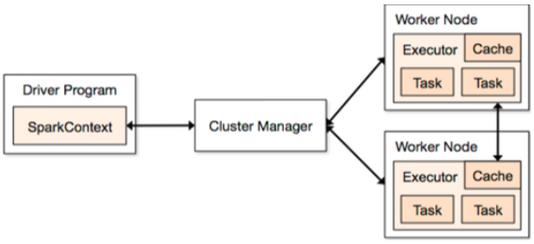
1.Application:基于spark的用户程序,包含了一个driver program 和集群中多个 executor
2.Driver Program:运行application的main()函数并自动创建SparkContext。通常SparkContext 代表driver program
3.Executor:为某个Application运行在worker node 上的一个进程。该进程负责运行task并负责将数据存储在内存或者硬盘上,每个application 都有自己独立的 executors
4.Cluster Mannager:在集群上获得资源的外部服务(spark standalon,mesos,yarm)
5.Worker Node:集群中任何可运行application 代码的节点
6.RDD:spark 的几本运算单元,通过scala集合转化,读取数据集生成或者由其他RDD进过算子操作得到
7.Job:可以被拆分成task并行计算的单元,一般为spark action 触发的一次执行作业
8.Stage:每个job会被拆分成很多组task,每组任务被称为stage,也可称TaskSet,该属于经常在日志中看到
9.task:被送到executor上执行的工作单元
基本运行流程
Spark应用程序有多种运行模式。SparkContext和Executor这两部分的核心代码实现在各种运行模式中都是公用的,在这两部分之上,根据运行部署模式(例如:Local[N]、Yarn cluster等)的不同,有不同的调度模块以及对应的适配代码。
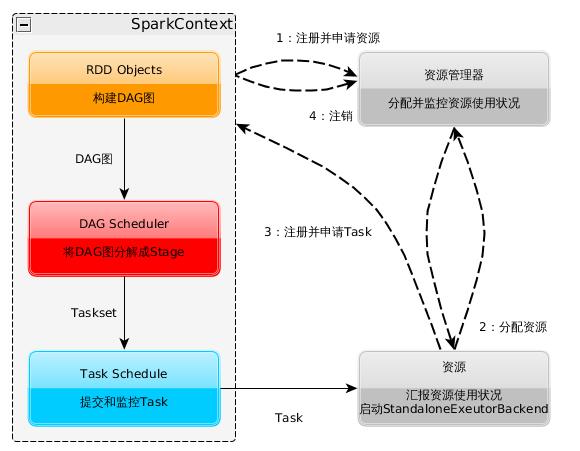
具体来说,以SparkContext为程序运行的总入口,在SparkContext的初始化过程中,Spark会分别创建DAGScheduler作业和TaskScheduler任务调度两级调度模块。
其中作业调度模块是基于任务阶段的高层调度模块,它为每个Spark作业计算具有依赖关系的多个调度阶段(通常根据shuffle来划分),然后为每个阶段构建出一组具体的任务(通常会考虑数据的本地性等),然后以TaskSets(任务组)的形式提交给任务调度模块来具体执行。而任务调度模块则负责具体启动任务、监控和汇报任务运行情况。
详细的运行流程为:
- 构建Spark Application的运行环境(启动SparkContext),SparkContext向资源管理器(可以是Standalone、Mesos或YARN)注册并申请运行Executor资源;
- 资源管理器分配Executor资源并启动StandaloneExecutorBackend,Executor运行情况将随着心跳发送到资源管理器上;
- SparkContext构建成DAG图,将DAG图分解成Stage,并把Taskset发送给Task Scheduler。Executor向SparkContext申请Task,Task Scheduler将Task发放给Executor运行同时SparkContext将应用程序代码发放给Executor。
- Task在Executor上运行,运行完毕释放所有资源。
作业调度模块和具体的部署运行模式无关,在各种运行模式下逻辑相同。不同运行模式的区别主要体现在任务调度模块。不同的部署和运行模式,根据底层资源调度方式的不同,各自实现了自己特定的任务调度模块,用来将任务实际调度给对应的计算资源。接下来重点介绍下YARN cluster模式的实现原理和实现细节。
YARN cluster运行模式的内部实现原理
Spark有多种运行模式,在这里主要介绍下YARN cluster模式的内部实现原理。如下图是YARN cluster模式的原理框图,相对于其他模式,该模式比较特殊的是它需要由外部程序辅助启动APP。用户的应用程序通过辅助的YARN Client类启动。YARN cluster模式和YARN client模式的区别在于:YARN client模式的AM是运行在提交任务的节点,而YARN cluster模式的AM是由YARN在集群中选取一个节点运行,不一定是在提交任务的节点运行。例如spark-shell如果需要使用YARN模式运行,只能为yarn-client模式,启动命令可以使用spark-shell --master yarn-client。
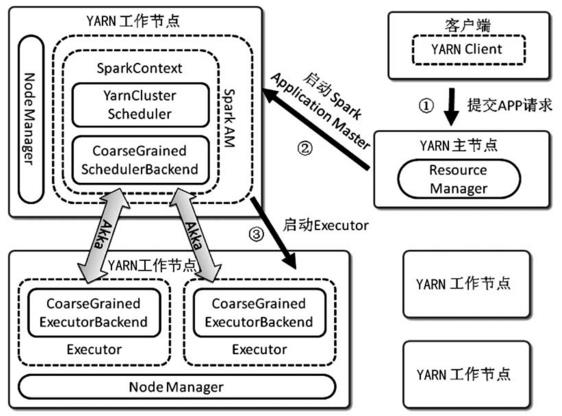
Client类通过YARN Client API提交请求,在Hadoop集群上启动一个Spark ApplicationMaster,Spark ApplicationMaster首先注册自己为一个YARN ApplicationMaster,之后启动用户程序,SparkContext在用户程序中初始化时,使用CoarseGrainedSchedulerBackend配合YARNClusterScheduler,YARNClusterScheduler只是对TaskSchedulerImpl的一个简单包装,增加了对Executor的等待逻辑等。
根据Client类传递的参数,Spark ApplicationMaster通过YARN ResourceManager/NodeManager的接口在集群中启动若干个Container,用于运行CoarseGrainedExecutorBackend.CoarseGrainedExecutorBackend在启动过程中会向CoarseGrainedSchedulerBackend注册。
CoarseGrainedSchedulerBackend是一个基于Akka Actor实现的粗粒度的资源调度类,在整个Spark作业运行期间,CoarseGrainedSchedulerBackend主要负责如下功能:
- 监听并持有注册给它的Executor资源
- 根据现有的Executor资源,进行Executor的注册、状态更新、相应Scheduler的请求等任务的调度
以上是关于spark 教程二 spark中的一些术语和概念的主要内容,如果未能解决你的问题,请参考以下文章