oracle 取平均值
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了oracle 取平均值相关的知识,希望对你有一定的参考价值。
如图,oracle如何平均值?

select CHECK_NORM,
(to_number(substr(CHECK_INFO, 1, 4)) +
to_number(substr(CHECK_INFO, 6, 4)) +
to_number(substr(CHECK_INFO, 11, 4)) +
to_number(substr(CHECK_INFO, 16, 4)) +
to_number(substr(CHECK_INFO, 21, 4)) +
to_number(substr(CHECK_INFO, 26, 4)) +
to_number(substr(CHECK_INFO, 31, 4)) +
to_number(substr(CHECK_INFO, 36, 4)) +
to_number(substr(CHECK_INFO, 41, 4)) +
to_number(substr(CHECK_INFO, 46, 4))) / 10
from 表名;
如果格式不统一,建议如2楼的,把字符型中的‘/’全部替换成‘+’,然后拼接出来一个sql,执行处理。
望采纳,谢谢。追问
关键是数值还有9.85/3.25/18.75这种。你这种substr就不能用了啊
追答那就第二种方法,拼接出来加法SQL,你把查询出来的语句想办法方一个表里就行了。
一看就明白了。
select 'select CHECK_NORM, '||'sum('|| REPLACE(CHECK_INFO, '/', '+' )||')'||' from 表名' from 表名;
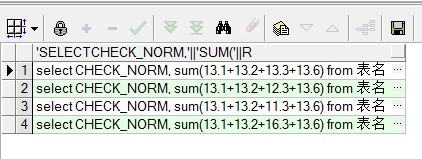
都是十个数的话 还可以直接就算出平均值。select 'select CHECK_NORM, '||'sum('|| REPLACE(CHECK_INFO, '/', '+' )||')/10'||' from 表名' from 表名;
如果想一个表里展示出来查询结果,可以把这些语句用union 连接起来批量一起执行。
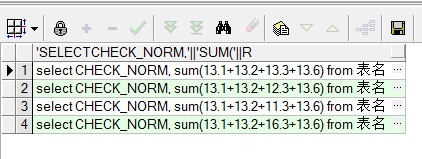
SELECT CHECK_NORM,CHECK_INFO,(SUM(REPLACE(CHECK_INFO,'/','+'))/10 AVG,TERMINALID FROM 表名 WHERE TERMINALID=10003653追问
你说的我试过,不行的
ORA-00904: "CHECK_INFO": invalid identifier
可以建一个拆分函数﹐把每个数字拆出来再SUM﹐网上查一下﹐MSSQL的话就可以帮你﹐ORACLE就没办法了
参考技术C 你看到下面,我相信你会有另外一种解决的idea 。连接到:
Oracle Database 11g Enterprise Edition Release 11.1.0.7.0 - Production
With the Partitioning, OLAP, Data Mining and Real Application Testing options
SQL> SELECT AVG(column_value) FROM TABLE(ku$_vcnt(12,13,14,15,16,17));
AVG(COLUMN_VALUE)
-----------------
14.5
SQL>
我自己剪短的写了个:
CREATE OR REPLACE FUNCTION getAvg(COLUMN_VALUE VARCHAR2)
RETURN NUMBER
IS
v_str VARCHAR2(1000);
v_col_name VARCHAR2(100);
avg_val NUMBER;
BEGIN
v_col_name:=COLUMN_VALUE;
v_str:='SELECT AVG(COLUMN_VALUE) FROM table(ku$_vcnt('||REPLACE(v_col_name,'/',',')||'))';
EXECUTE IMMEDIATE v_str INTO avg_val;
RETURN avg_val;
END;
SQL>
SQL> SELECT getAvg('12/13/14/15/16') FROM dual;
GETAVG('12/13/14/15/16')
------------------------
14
SQL>
当然你也可以将分割符作为参数传入。
参考技术D 请输入:我要取平均值追问请滚回碗里去
第5个回答 推荐于2017-09-30 可以使用split函数:1,建立split函数
create or replace function split(p_value varchar2,
p_split varchar2)
return strsplit_type
pipelined is
v_idx integer;
v_str varchar2(500);
v_strs_last varchar2(4000) := p_value;
begin
loop
v_idx := instr(v_strs_last, p_split);
exit when v_idx = 0;
v_str := substr(v_strs_last, 1, v_idx - 1);
v_strs_last := substr(v_strs_last, v_idx + 1);
pipe row(v_str);
end loop;
pipe row(v_strs_last);
return;
end split;
2,应用
select avg(to_number(column_value))) as avgvalue from table (split(check_info的列值, ' / ' ))追问
你好,我在用你的语句建立函数的时候,有个报错, ORA-24344: success with compilation error ,在帮忙看看是不是语句哪边有问题?
本回答被提问者和网友采纳如何根据 R 中的条件对多列取平均值?
【中文标题】如何根据 R 中的条件对多列取平均值?【英文标题】:How do I take an average over multiple columns based on conditions in R? 【发布时间】:2021-07-29 03:04:03 【问题描述】:tconst averageRating language startYear
1 tt0000001 5.7 en 1894
2 tt0000002 6.0 de 1892
3 tt0000003 6.5 ja 1892
4 tt0000004 6.1 es 1892
5 tt0000007 5.4 de 1894
6 tt0000008 5.4 ja 1894
如何找到每种语言每年的平均评分?那么每年所有ja的平均值?我想以包含两列的每种语言的数据框结束,一列包含所有年份,另一列包含当年的平均 averageRating(示例如下)
Year Rating
1990 6.0
1991 5.7
1992 6.2
1993 5.5
1994 6.5
1995 6.7
我能想到的唯一方法是使用三个 for 循环,但这似乎低效无望,一定有更好的方法吗?
谢谢
【问题讨论】:
【参考方案1】:startYear 和 language 的第一组。然后通过mean(averageRating) 汇总,然后pivot_wider() 合并所有语言的输出:
require(tidyr)
require(dplyr)
df <- df %>% group_by(startYear,language) %>%
dplyr::summarise(Rating=mean(averageRating)) %>%
tidyr::pivot_wider(names_from = language, values_from = Rating)
> df
startYear de es ja en
<dbl> <dbl> <dbl> <dbl> <dbl>
1 1892 6 6.1 6.5 NA
2 1894 5.4 NA 5.4 5.7
更整洁(感谢@LMc):
df %>% tidyr::pivot_wider(id_cols = startYear, names_from = language, values_from = averageRating, values_fn = function(x) mean(x, na.rm = T))
startYear de es ja en
<dbl> <dbl> <dbl> <dbl> <dbl>
1 1892 6 6.1 6.5 NA
2 1894 5.4 NA 5.4 5.7
数据:
df <- data.frame(tconst = c("tt0000001","tt0000002","tt0000003","tt0000004","tt0000007","tt0000008"), averageRating=c(5.7,6.0,6.5,6.1,5.4,5.4),language=c("en","de","ja","es","de","ja"), startYear = c(1894,1892,1892,1892,1894,1894))
【讨论】:
您可以将其简化为:df %>% tidyr::pivot_wider(id_cols = startYear, names_from = language, values_from = averageRating, values_fn = function(x) mean(x, na.rm = T))以上是关于oracle 取平均值的主要内容,如果未能解决你的问题,请参考以下文章