Day17:继承实现的原理子类中调用父类的方法封装
Posted Wang-Vee
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Day17:继承实现的原理子类中调用父类的方法封装相关的知识,希望对你有一定的参考价值。
一、继承实现的原来
1、继承顺序
Python的类可以继承多个类。继承多个类的时候,其属性的寻找的方法有两种,分别是深度优先和广度优先。
如下的结构,新式类和经典类的属性查找顺序都一致。顺序为D--->A--->E--->B--->C。
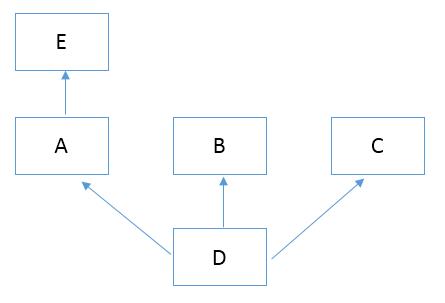
class E: def test(self): print(\'from E\') class A(E): def test(self): print(\'from A\') class B: def test(self): print(\'from B\') class C: def test(self): print(\'from C\') class D(A,B,C): def test(self): print(\'from D\') d=D() d.test() print(D.mro()) #新式类才可以查看.mro()方法查看查找顺序 \'\'\' from D [<class \'__main__.D\'>, <class \'__main__.A\'>, <class \'__main__.E\'>, <class \'__main__.B\'>, <class \'__main__.C\'>, <class \'object\'>] \'\'\'
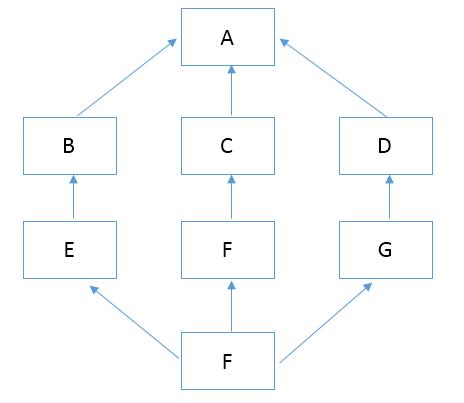
如下的结构,新式类和经典类的属性查找顺序就不一样了。
经典类遵循深度优先,其顺序为:F--->E--->B--->A--->F--->C--->G--->D
新式类遵循广度优先,其顺序为:F--->E--->B--->F--->C--->G--->D--->A
2、继承原理
python到底是如何实现继承的,对于你定义的每一个类,python会计算出一个方法解析顺序(MRO)列表,这个MRO列表就是一个简单的所有基类的线性顺序列表,例如:
print(D.mro()) \'\'\' [<class \'__main__.D\'>, <class \'__main__.A\'>, <class \'__main__.E\'>, <class \'__main__.B\'>, <class \'__main__.C\'>, <class \'object\'>] \'\'\'
为了实现继承,python会在MRO列表上从左到右开始查找基类,直到找到第一个匹配这个属性的类为止。
而这个MRO列表的构造是通过一个C3线性化算法来实现的。我们不去深究这个算法的数学原理,它实际上就是合并所有父类的MRO列表并遵循如下三条准则:
1.子类会先于父类被检查。
2.多个父类会根据它们在列表中的顺序被检查。
3.如果对下一个类存在两个合法的选择,选择第一个父类。
二、子类中调用父类的方法
子类继承了父类的方法,然后想进行修改,注意了是基于原有的基础上修改,那么就需要在子类中调用父类的方法。
方法一:父类名.父类方法()
#_*_coding:utf-8_*_ class Vehicle: #定义交通工具类 Country=\'China\' def __init__(self,name,speed,load,power): self.name=name self.speed=speed self.load=load self.power=power def run(self): print(\'开动啦...\') class Subway(Vehicle): #地铁 def __init__(self,name,speed,load,power,line): Vehicle.__init__(self,name,speed,load,power) self.line=line def run(self): print(\'地铁%s号线欢迎您\' %self.line) Vehicle.run(self) line13=Subway(\'中国地铁\',\'180m/s\',\'1000人/箱\',\'电\',13) line13.run()
方法二:super()
class Vehicle: #定义交通工具类 Country=\'China\' def __init__(self,name,speed,load,power): self.name=name self.speed=speed self.load=load self.power=power def run(self): print(\'开动啦...\') class Subway(Vehicle): #地铁 def __init__(self,name,speed,load,power,line): #super(Subway,self) 就相当于实例本身 在python3中super()等同于super(Subway,self) super().__init__(name,speed,load,power) self.line=line def run(self): print(\'地铁%s号线欢迎您\' %self.line) super(Subway,self).run() class Mobike(Vehicle):#摩拜单车 pass line13=Subway(\'中国地铁\',\'180m/s\',\'1000人/箱\',\'电\',13) line13.run()
不用super引发的惨案
#每个类中都继承了且重写了父类的方法 class A: def __init__(self): print(\'A的构造方法\') class B(A): def __init__(self): print(\'B的构造方法\') A.__init__(self) class C(A): def __init__(self): print(\'C的构造方法\') A.__init__(self) class D(B,C): def __init__(self): print(\'D的构造方法\') B.__init__(self) C.__init__(self) f1=D() print(D.__mro__) \'\'\' D的构造方法 B的构造方法 A的构造方法 C的构造方法 A的构造方法 (<class \'__main__.D\'>, <class \'__main__.B\'>, <class \'__main__.C\'>, <class \'__main__.A\'>, <class \'object\'>) \'\'\'
使用super()的结果
class A: def __init__(self): print(\'A的构造方法\') class B(A): def __init__(self): print(\'B的构造方法\') super().__init__() #super(B,self).__init__() class C(A): def __init__(self): print(\'C的构造方法\') super().__init__() #super(C,self).__init__() class D(B,C): def __init__(self): print(\'D的构造方法\') super().__init__() #super(D,self).__init__() # C.__init__(self) f1=D() print(D.__mro__) \'\'\' D的构造方法 B的构造方法 C的构造方法 A的构造方法 (<class \'__main__.D\'>, <class \'__main__.B\'>, <class \'__main__.C\'>, <class \'__main__.A\'>, <class \'object\'>) \'\'\'
当你使用super()函数时,Python会在MRO列表上继续搜索下一个类。只要每个重定义的方法统一使用super()并只调用它一次,那么控制流最终会遍历完整个MRO列表,每个方法也只会被调用一次(注意注意注意:使用super调用的所有属性,都是从MRO列表当前的位置往后找,千万不要通过看代码去找继承关系,一定要看MRO列表)
三、封装
1、要封装什么
封装数据和方法
2、为什么要封装
封装不是单纯意义的隐藏:
1:封装数据的主要原因是:保护隐私
2:封装方法的主要原因是:隔离复杂度
3、封装分为两个层面
封装其实分为两个层面,但无论哪种层面的封装,都要对外界提供好访问你内部隐藏内容的接口(接口可以理解为入口,有了这个入口,使用者无需且不能够直接访问到内部隐藏的细节,只能走接口,并且我们可以在接口的实现上附加更多的处理逻辑,从而严格控制使用者的访问。
第一个层面的封装(什么都不用做):创建类和对象会分别创建二者的名称空间,我们只能用类名.或者obj.的方式去访问里面的名字,这本身就是一种封装。
注意:对于这一层面的封装(隐藏),类名.和实例名.就是访问隐藏属性的接口
第二个层面的封装:类中把某些属性和方法隐藏起来(或者说定义成私有的),只在类的内部使用、外部无法访问,或者留下少量接口(函数)供外部访问。
在python中用双下划线的方式实现隐藏属性(设置成私有的)
class A: __N=0 #类的数据属性就应该是共享的,但是语法上是可以把类的数据属性设置成私有的如__N,会变形为_A__N def __init__(self): self.__X=10 #变形为self._A__X def __foo(self): #变形为_A__foo print(\'from A\') def bar(self): self.__foo() #只有在类内部才可以通过__foo的形式访问到.
class Teacher: def __init__(self,name,age): self.__name=name self.__age=age def tell_info(self): print(\'姓名:%s,年龄:%s\' %(self.__name,self.__age)) def set_info(self,name,age): if not isinstance(name,str): raise TypeError(\'姓名必须是字符串类型\') if not isinstance(age,int): raise TypeError(\'年龄必须是整型\') self.__name=name self.__age=age t=Teacher(\'egon\',18) t.tell_info() t.set_info(\'egon\',19) t.tell_info()
这种自动变形的特点:
1.类中定义的__x只能在内部使用,如self.__x,引用的就是变形的结果。
2.这种变形其实正是针对外部的变形,在外部是无法通过__x这个名字访问到的。
2.在子类定义的__x不会覆盖在父类定义的__x,因为子类中变形成了:_子类名__x,而父类中变形成了:_父类名__x,即双下滑线开头的属性在继承给子类时,子类是无法覆盖的。
注意:对于这一层面的封装(隐藏),我们需要在类中定义一个函数(接口函数)在它内部访问被隐藏的属性,然后外部就可以使用了。
这种变形需要注意的问题是:
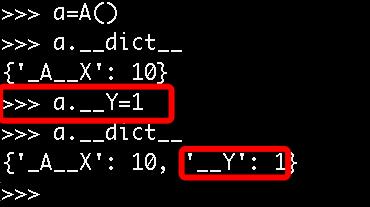
1.这种机制也并没有真正意义上限制我们从外部直接访问属性,知道了类名和属性名就可以拼出名字:_类名__属性,然后就可以访问了,如a._A__N
2.变形的过程只在类的定义是发生一次,在定义后的赋值操作,不会变形。
3.在继承中,父类如果不想让子类覆盖自己的方法,可以将方法定义为私有的。
类中所有双下划线开头的名称如__x都会自动变形成:_类名__x的形式:
#正常情况 >>> class A: ... def fa(self): ... print(\'from A\') ... def test(self): ... self.fa() ... >>> class B(A): ... def fa(self): ... print(\'from B\') ... >>> b=B() >>> b.test() from B
#把fa定义成私有的,即__fa >>> class A: ... def __fa(self): #在定义时就变形为_A__fa ... print(\'from A\') ... def test(self): ... self.__fa() #只会与自己所在的类为准,即调用_A__fa ... >>> class B(A): ... def __fa(self): ... print(\'from B\') ... >>> b=B() >>> b.test() from A
python并不会真的阻止你访问私有的属性,模块也遵循这种约定,如果模块名以单下划线开头,那么from module import *时不能被导入,但是你from module import _private_module依然是可以导入的
其实很多时候你去调用一个模块的功能时会遇到单下划线开头的(socket._socket,sys._home,sys._clear_type_cache),这些都是私有的,原则上是供内部调用的,作为外部的你,一意孤行也是可以用的,只不过显得稍微傻逼一点点。
4、特性(property)
1.什么是特性property
property是一种特殊的属性,访问它时会执行一段功能(函数)然后返回值
例一:BMI指数(bmi是计算而来的,但很明显它听起来像是一个属性而非方法,如果我们将其做成一个属性,更便于理解)
class People: def __init__(self,name,weight,height): self.name=name self.weight=weight self.height=height @property def bmi(self): return self.weight / (self.height**2) p1=People(\'egon\',75,1.85) print(p1.bmi)
例二、圆的周长和面积
import math class Circle: def __init__(self,radius): #圆的半径radius self.radius=radius @property def area(self): return math.pi * self.radius**2 #计算面积 @property def perimeter(self): return 2*math.pi*self.radius #计算周长 c=Circle(10) print(c.radius) print(c.area) #可以向访问数据属性一样去访问area,会触发一个函数的执行,动态计算出一个值 print(c.perimeter) #同上 \'\'\' 输出结果: 314.1592653589793 62.83185307179586 \'\'\'
注意:此时的特性arear和perimeter不能被赋值
c.area=3 #为特性area赋值 \'\'\' 抛出异常: AttributeError: can\'t set attribute \'\'\'
2.为什么要用property
将一个类的函数定义成特性以后,对象再去使用的时候obj.name,根本无法察觉自己的name是执行了一个函数然后计算出来的,这种特性的使用方式遵循了统一访问的原则。
ps:面向对象的封装有三种方式: 【public】 这种其实就是不封装,是对外公开的 【protected】 这种封装方式对外不公开,但对朋友(friend)或者子类公开 【private】 这种封装对谁都不公开
python并没有在语法上把它们三个内建到自己的class机制中,在C++里一般会将所有的所有的数据都设置为私有的,然后提供set和get方法(接口)去设置和获取,在python中通过property方法可以实现。
class Foo: def __init__(self,val): self.__NAME=val #将所有的数据属性都隐藏起来 @property def name(self): return self.__NAME #obj.name访问的是self.__NAME(这也是真实值的存放位置) @name.setter def name(self,value): if not isinstance(value,str): #在设定值之前进行类型检查 raise TypeError(\'%s must be str\' %value) self.__NAME=value #通过类型检查后,将值value存放到真实的位置self.__NAME @name.deleter def name(self): raise TypeError(\'Can not delete\') f=Foo(\'egon\') print(f.name) # f.name=10 #抛出异常\'TypeError: 10 must be str\' del f.name #抛出异常\'TypeError: Can not delete\'


class People: def __init__(self,name,age,sex,height,weight,permission=False): self.__name=name self.__age=age self.__sex=sex self.__height=height self.__weight=weight self.permission=permission @property def name(self): return self.__name @name.setter def name(self,val): if not isinstance(val,str): raise TypeError(\'must be str\') self.__name=val @name.deleter def name(self): if not self.permission: raise PermissionError(\'不让删\') del self.__name egon=People(\'egon\',18,\'male\',1.79,70) # print(egon.name) # egon.name=123 # print(egon.name) print(egon.permission) egon.permission=True del egon.name print(egon.name) 教师实例
以上是关于Day17:继承实现的原理子类中调用父类的方法封装的主要内容,如果未能解决你的问题,请参考以下文章