HBase写入性能改造(续)--MemStoreflushcompact参数调优及压缩卡的使用
Posted 尧字节
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HBase写入性能改造(续)--MemStoreflushcompact参数调优及压缩卡的使用相关的知识,希望对你有一定的参考价值。
首先续上篇测试:
经过上一篇文章中对代码及参数的修改,Hbase的写入性能在不开Hlog的情况下从3~4万提高到了11万左右。
本篇主要介绍参数调整的方法,在HDFS上加上压缩卡,最后能达到的写入性能为17W行每秒(全部测试都不开Hlog)。
|
上篇测试内容: 详情 http://blog.csdn.net/kalaamong/article/details/7275242。 测试数据 http://blog.csdn.net/kalaamong/article/details/7290192
同时上一篇中除压缩卡之外的代码改动被整理成patch放到了Git上。打上patch修改参数之后写入随便压到7至8万应当都是没问题的。感谢某试用过的童鞋。 https://github.com/ICT-Ope/HBase.0.90.4_Put_Throughput_Improvement 一个简单的Read Me:
|
1.遗留的问题--首先为什么最后的测试没出现瓶颈:
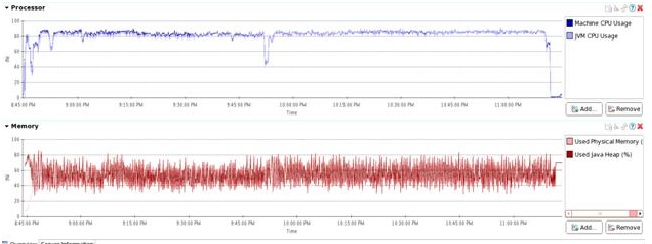
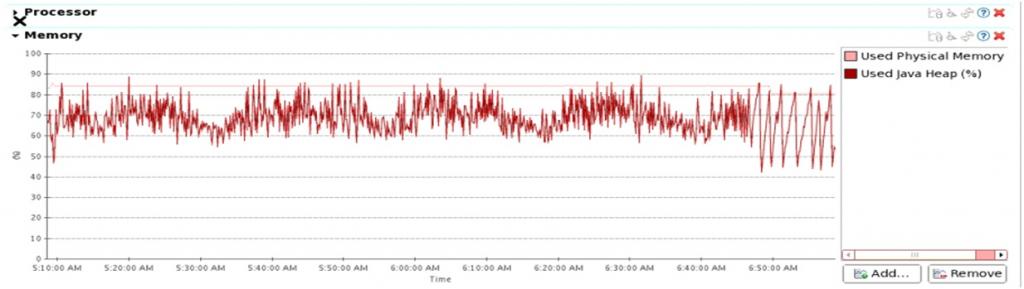
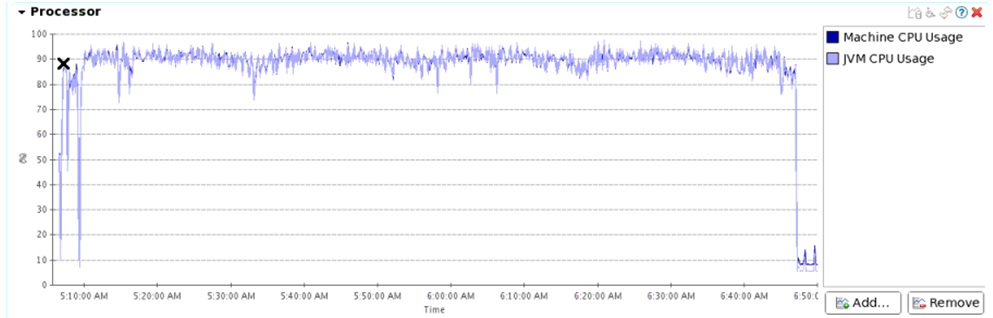
这是上篇文章中第五组测试时CPU和JVM GC的情况,当时的系统吞吐量稳定在11w/s。
CPU 徘徊在80%多一点,没有找到瓶颈的位置。
首先看一下我们集群的参数:
|
测试机性能 |
|
|
CPU |
16* Intel(R) Xeon(R) CPU E5620 @ 2.40GHz |
|
MEMORY |
48GB |
|
DISK |
12*SATA 2TB |
|
NET |
4*1Gb Ethernet |
下面简单分析一下:
CPU
最直白的是Region Server CPU只到80%左右。没有到瓶颈。
DISK
12*SATA *5 data node最差的情况下能提供 50MB*12*5=3000MB/s的吞吐量。
写入10亿行数据最后变成没有压缩的HFile大约450GB,同时三副本开销约1350GB。
上次测试最快完的一组耗时2小时24。
也就是说平均写入磁盘的通量是160MB/S。这远没达到磁盘通量。
并且非常重要的一点,最后的一组测试是使用压缩卡的,HDFS透明压缩后数据量下降到1/4左右。
也就是说实际的平均通量也就是30MB/S到50MB/S。如此看来磁盘很闲。
NET
所以最有嫌疑是就是网络,并且是hbase client到Region Server这一段,没有压缩的数据传输可能遇到了网络的瓶颈。
但仔细一算未压缩的数据写入磁盘通量是160MB/S,HBase client到Region Server这一段数据没有副本。
也就是说平均通量为50MB/S。对于单张网卡压力较大,但其实也没有到瓶颈。
写入稳定性
所以还有一个可能的问题,就是我们在监控网卡时发现HBase运行时,写入流量不稳定,网络流量时高时底。
2.解决问题:多网卡绑定
测试服务器网卡采用双网卡4千兆口bond 0链路聚合。交换机上四口绑定为trunk。
但实际测量的情况是双机互联数据传输时不论开多少端口用多少链路,传输极限还是只能到一张网卡的速度110MB左右。
且实际的现象是发送机的所有网卡都有数据output而接收机的网卡只有一个口有input数据包。
原因:H3C-S5120-SI trunk负载均衡策略问题
问题渐渐浮出水面了,交换机即使trunk了也没有对四个端口作负载均衡。而操作系统在发送时是会做网卡的负载均衡的。
同时我们又测了一下多台机器向一台机器发送数据,及一台机器向多台机器发送数据的情况。
结果都是两个测试中的单点都流量都能超过单张网卡的流量。
如此我们有理由怀疑交换机trunk负载均衡是利用源和目的MAC地址来做的。
所以对于源和目的MAC都相同的双机对传数据的情况,不论开多少端口速度也超不过一张网卡。
交换机型号为H3C-S5120-SI。去年8月份购入,默认安装的固件不支持修改聚合均衡模式。
不过H3C官网提供升级,并添加了以下几条新命令可以修改模式。
display link-aggregationload-sharing mode
link-aggregation load-sharingmode
同时H3C官方说明如下:
|
缺省情况下,全局采用的聚合负载分担类型是:二层报文根据源/目的MAC地址进行聚合负载分担,三层报文根据源/目的MAC地址及源/目的IP地址进行聚合负载分担。 |
我们改用了源port和目的port的负载均衡。这个问题被解决。
点对点传输多个端口的情况下,双网卡四千兆网口绑定流量实测为350MB/s左右。
3.解决问题:HBase写入通量波动问题
几个常见参数的之间的关系:
|
hbase.hregion.memstore.flush.size 默认 1024*1024*64L hbase.hregion.memstore.block.multiplier 默认 2 hbase.regionserver.global.memstore.upperLimit 默认 0.4 hbase.regionserver.global.memstore.lowerLimit 默认 0.35 以及在patch中添加的一个参数: hbase.hregion.memstore.flush.block.size |
hbase.hregion.memstore.flush.size
每次update之后会检查此region memstore是否达到这个大小,达到之后就会请求flush。默认值为64MB
hbase.hregion.memstore.block.multiplier
当单个region 的memstore size达到hbase.hregion.memstore.flush.size*hbase.hregion.memstore.block.multiplier时,本region的update会被block。
hbase.regionserver.global.memstore.upperLimit
当RS memstore超过这个比率,RS的所有update会被block。
具体见reclaimMemStoreMemory(),这几乎是个跟gc一样的stop word上限。
hbase.regionserver.global.memstore.lowerLimit
当用memstore高于这个值时,即使没有region要求flush,MemstoreFlusher也会挑一个region去flush然后sleep一会,这个参数影响不大。
调整原则:
1.让memstore占用尽量大,一方面可以缓冲定入流量,一方面可以增加StoreFile大小,减少flush次数,减少StoreFile数目减小Compact压力。
2.控制memstore总大小,不大于memstore.upperLimit,不出现RegionServer block。
3.每个Region交错flush。
最初HBase RegionServer分到的内存是20GB。
由于是写入压测,所以把memstore大小调节到hbase.regionserver.global.memstore.upperLimit 0.55 即为11GB。
同时100个Region同时写入,到region达到block时,也就是最坏情况下memstore能达到的最大值为11.75GB。
这样则有可能达到upperLimit而阻碍整个RS的update。
这里我们把RS的内存调到了30GB。并增加了flush的线程数到30,优先级最大。
之后我们发现压测过程中memstore占用维持在4到5GB左右。
按道理一共能使用的16GB memstore都处于闲置状态。刷新次数频繁导致刷新产生的文件多,且文件大小都偏小。
加重了compact的负担,同时过小的memstore也是产生波动的主要原因。
所以将hbase.hregion.memstore.flush.size调整到100MB。
同时添加了一个参数控制代替系统中使用的hbase.hregion.memstore.block.multiplier参数。
名为hbase.hregion.memstore.flush.block.size来直接控制单个region blockupdate时的size大小,并设为120000000。
如此之后memstore 的size在压测过程中一直维持在8到10GB之间。写入通量也更为平稳了。
4.解决问题:其它改动
1 .打开了LAB。来减少full GC的次数。
2 .减少compact线程
之后压测时发现CPU大量消耗在compact线程上,所以我们把compact的线程数目重新降到1。
(由于现在flush时region更大,compact相对压力较小)。
compact优化的是读取,在写入密集的应用中作用不大。
同时把hbase.hstore.blockingStoreFiles设到一个非常大的值,使compact不会阻塞flush的进行。
3 . 加速反序列化
将
- org.apache.hadoop.io.WritableFactories
- private static final HashMap<Class, WritableFactory> CLASS_TO_FACTORY
改为ConcurrentHashMap并去掉了相关方法中synchronize关键字来加速反序列化过程。
5.效果:
经过这样的修改之后,压测时基本又回到最cpu 90%以上的情况。
经分析30%多的CPU消耗在Put插入Memstore时Bytes.compareTo()上,20%左右的CPU消耗在IPC Reader反序列化数据上。
6.附加内容:
我们尝试用JNI调用memcmp来替换compareTo()方法,
但发现效果非常差,不是memcmp慢,而是JNI调用非常慢。系统吞吐量下降到5w左右。
再说说压缩卡的作用,我们做的HDFS上的GZ压缩卡透明压缩,起初我们以为会有明显的off loading cpu的效果,但实际测试并不明显。
主要还是现在服务器cpu太强,再HBase写入时CPU的消耗大部分不在做压缩上。
其实压缩卡最大的作用还是大大提高了磁盘的通量,通过压缩在几乎没有时延的前提下让磁盘IO提高4到5倍。
最后下面是我们刚拿到的新硬:
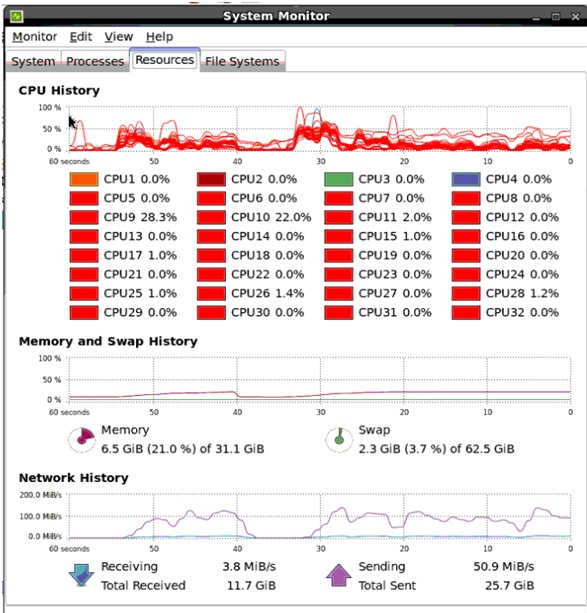
Intel的新CPU,这只是半个节点的配置,简单用上面的数据测试了一下,吞吐量轻松过30W/S。
这也从侧面证明了HBase写入时瓶颈通常还是CPU。
PC Server快赶上小型机了。
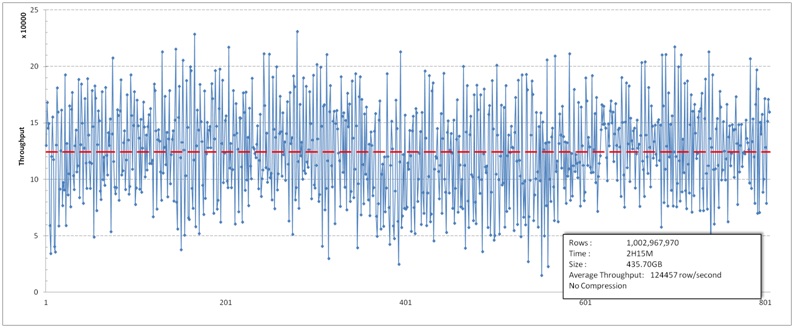
7:本次测试的详细测试结果
测试分为三组,数据和集群情况与http://blog.csdn.net/kalaamong/article/details/7290192相同
三组分别为:不做数据压缩,使用软件GZ压缩,使用压缩卡HDFS层GZ透明压缩。
(Put.setWriteToWAL(false);不写log)
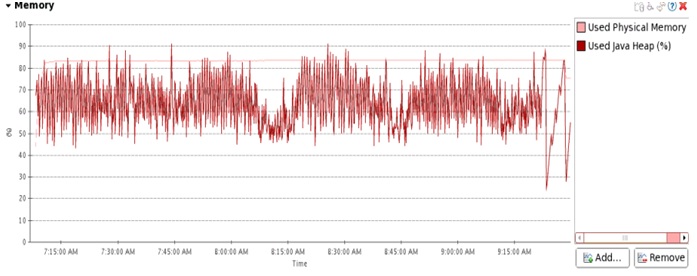
三组的写入流量都比上次测试的要稳定。
不压缩的情况:


软件GZ压缩的情况:

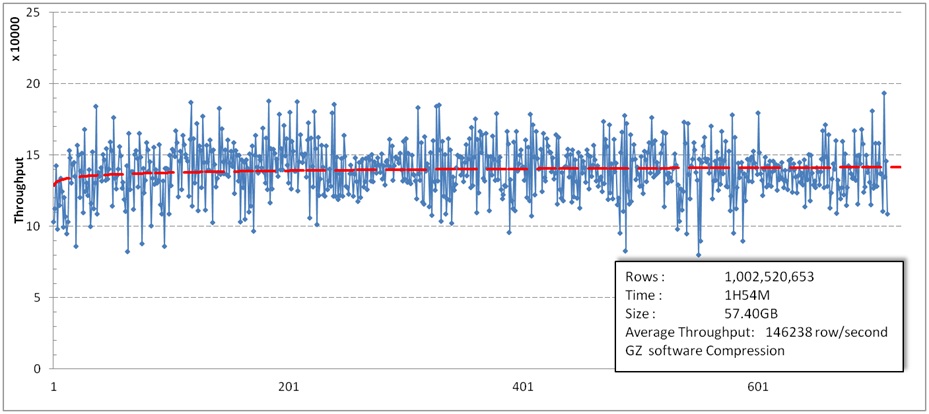
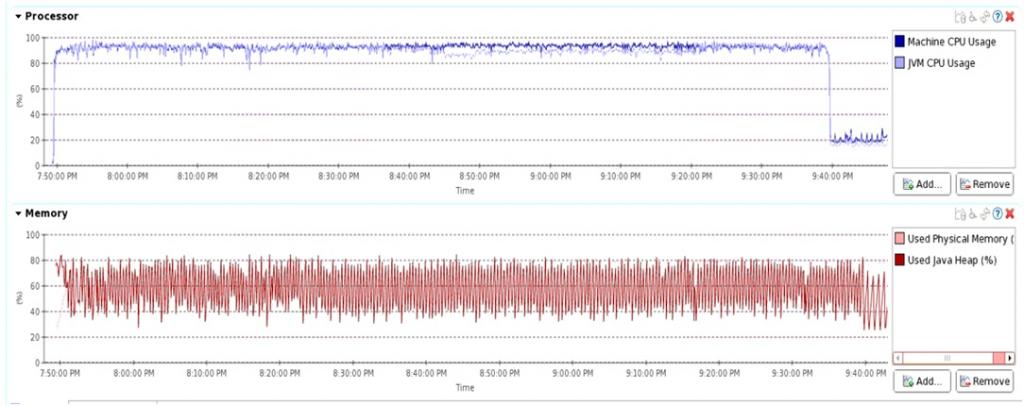
HDFS上GZ压缩卡透明压缩
这一组采用了我们新添加的功能,HDFS透明硬件压缩卡数据压缩。以下是测试结果。
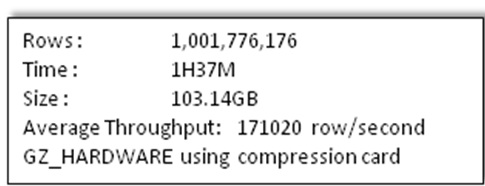
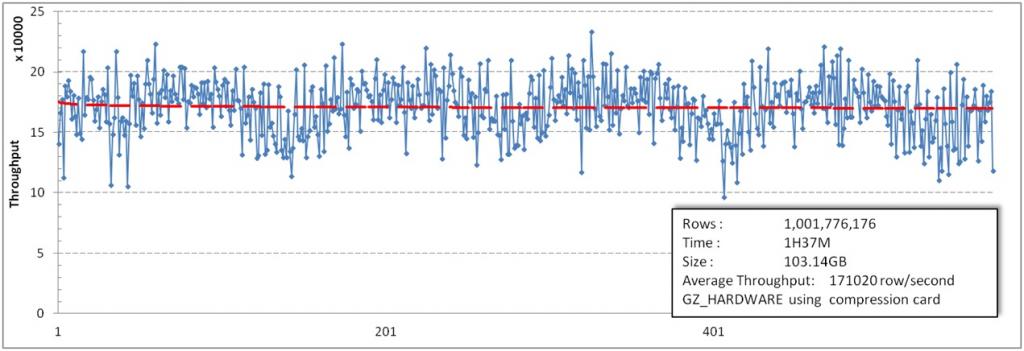
以上是关于HBase写入性能改造(续)--MemStoreflushcompact参数调优及压缩卡的使用的主要内容,如果未能解决你的问题,请参考以下文章