axure 中继器的每行怎么求和输出到外面?网上竟没有这信息,高手进来
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了axure 中继器的每行怎么求和输出到外面?网上竟没有这信息,高手进来相关的知识,希望对你有一定的参考价值。
如何把中继器指定单例的数值都加起来算一个总和,然后输出到非中继器的外部部件中?
像这个图黄色部份是中继器,如果可以指定从第二行例2开始求和,一直算到结尾,也是最好不过的了。

这个不复杂吧,在中继器的每项加载事件中 汇总及可以了
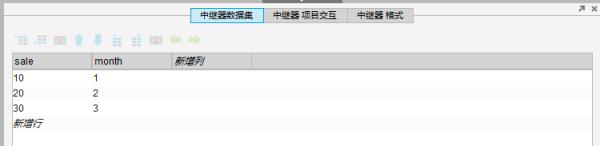

结果

Shell命令对整数求和,每行一个?
【中文标题】Shell命令对整数求和,每行一个?【英文标题】:Shell command to sum integers, one per line? 【发布时间】:2010-10-01 20:04:43 【问题描述】:我正在寻找一个可以接受(作为输入)多行文本的命令,每行包含一个整数,并输出这些整数的总和。
作为背景知识,我有一个包含时序测量的日志文件。通过对相关行的 grepping 和一些sed 重新格式化,我可以列出该文件中的所有时间。我想算出总数。我可以将此中间输出通过管道传输到任何命令,以便进行最终总和。过去我一直使用expr,但除非它在 RPN 模式下运行,否则我认为它无法解决这个问题(即使这样也会很棘手)。
我怎样才能得到整数的总和?
【问题讨论】:
这和我前段时间问的一个问题很相似:***.com/questions/295781/… 这个问题感觉像是代码高尔夫的问题。 codegolf.stackexchange.com :) 【参考方案1】:不能避免提交这个,这是这个问题最通用的方法,请检查:
jot 1000000 | sed '2,$s/$/+/;$s/$/p/' | dc
在这里可以找到,我是OP,答案来自观众:
Most elegant unix shell one-liner to sum list of numbers of arbitrary precision?以下是它相对于 awk、bc、perl、GNU 的 datamash 和朋友的特殊优势:
它使用任何 unix 环境中常见的标准实用程序 它不依赖于缓冲,因此它不会被非常长的输入阻塞。 这意味着没有特定的精度限制 - 或者整数大小 - 各位 AWK 朋友您好! 不需要不同的代码,如果需要添加浮点数,而不是。 理论上它可以在最小的环境中不受阻碍地运行【讨论】:
请在答案中包含与问题相关的代码,不要引用链接 它也恰好比所有其他解决方案慢得多,比 datamash 解决方案慢 10 倍以上 @GabrielRavier OP 并未将速度定义为首要要求,因此如果没有此要求,则首选通用工作解决方案。供参考。 datamash 并不是所有 Unix 平台的标准,fi。 MacOSX 似乎缺少这一点。 @fgeorgatos 这是真的,但我只是想向所有关注这个问题的人指出,与大多数 Linux 系统相比,这个答案实际上非常慢。 @GabrielRavier 您能否提供一些测量数据进行比较?顺便提一句。我已经运行了几个jot 测试,即使对于相当大的列表,速度也非常合理。顺便提一句。如果将 datamash 作为 OP 问题的解决方案,那么任何编译的汇编程序也应该是可以接受的......这会加快速度!【参考方案2】:
这是一个漂亮而干净的Raku(以前称为 Perl 6)单行:
say [+] slurp.lines
我们可以这样使用它:
% seq 10 | raku -e "say [+] slurp.lines"
55
它是这样工作的:
slurp 默认从标准输入读取,不带任何参数;它返回一个字符串。对字符串调用 lines method 会返回该字符串的行列表。
+ 周围的括号将+ 转换为reduction meta operator,这将列表缩减为单个值:列表中值的总和。 say 然后用换行符将其打印到标准输出。
需要注意的一点是,我们从不将行显式转换为数字——Raku 足够聪明,可以为我们做到这一点。然而,这意味着我们的代码在输入肯定不是数字时会中断:
% echo "1\n2\nnot a number" | raku -e "say [+] slurp.lines"
Cannot convert string to number: base-10 number must begin with valid digits or '.' in '⏏not a number' (indicated by ⏏)
in block <unit> at -e line 1
【讨论】:
say [+] lines 其实就够了:-)
@ElizabethMattijsen:酷!这是怎么回事?
不带任何参数的 lines 与不带任何语义的 slurp 具有相同的语义,但它会生成 Str 的 Seq,而不是单个 Str。【参考方案3】:
使用GNU datamash util:
seq 10 | datamash sum 1
输出:
55
如果输入数据不规则,在奇数位置有空格和制表符,这可能会混淆datamash,那么要么使用-W 开关:
<commands...> | datamash -W sum 1
...或使用tr 清理空白:
<commands...> | tr -d '[[:blank:]]' | datamash sum 1
如果输入足够大,输出将是科学计数法。
seq 100000000 | datamash sum 1
输出:
5.00000005e+15
要将其转换为十进制,请使用--format 选项:
seq 100000000 | datamash --format '%.0f' sum 1
输出:
5000000050000000
【讨论】:
【参考方案4】:您可以使用 num-utils,尽管它可能超出您的需要。这是一组用于在 shell 中处理数字的程序,可以做一些漂亮的事情,当然包括将它们相加。它有点过时了,但它们仍然有效,如果您需要做更多的事情,它们会很有用。
https://suso.suso.org/programs/num-utils/index.phtml
使用起来真的很简单:
$ seq 10 | numsum
55
但是大量输入的内存不足。
$ seq 100000000 | numsum
Terminado (killed)
【讨论】:
示例:numsum numbers.txt.
管道示例:printf "%s\n" 1 3 5 | numsum【参考方案5】:
好的,这是在 PowerShell 中的操作方法(PowerShell 核心,应该可以在 Windows、Linux 和 Mac 上运行)
Get-Content aaa.dat | Measure-Object -Sum
【讨论】:
这个问题被标记为 [[shell]]:“如果没有特定的标记,则应该假定一个可移植的(POSIX 兼容)解决方案”而不是 PowerShell【参考方案6】:我要对普遍认可的解决方案提出一个重大警告:
awk 's+=$1 END print s' mydatafile # DO NOT USE THIS!!
这是因为在这种形式中,awk 使用 32 位有符号整数表示:超过 2147483647(即 2^31)的总和会溢出。
更一般的答案(对整数求和)是:
awk 's+=$1 END printf "%.0f\n", s' mydatafile # USE THIS INSTEAD
【讨论】:
因为问题其实出在“打印”功能上。 awk 使用 64 位整数,但由于某种原因 print 将它们缩小为 32 位。 打印错误似乎已修复,至少对于 awk 4.0.1 和 bash 4.3.11,除非我弄错了:echo -e "2147483647 \n 100" |awk 's+=$1ENDprint s' 显示 2147483747
使用浮点数只是引入了一个新问题:echo 999999999999999999 | awk 's+=$1 END printf "%.0f\n", s' 产生 1000000000000000000
不应该只在 64 位系统上使用“%ld”来避免将 printf 截断为 32 位吗?正如@Patrick 指出的那样,浮动在这里不是一个好主意。
@yerforkferchips,%ld 应该放在代码的什么位置?我试过echo -e "999999999999999999" | awk 's+=$1 END printf "%ld\n", s',但它仍然产生1000000000000000000。【参考方案7】:
BASH 解决方案,如果你想把它变成一个命令(例如,如果你需要经常这样做):
addnums ()
local total=0
while read val; do
(( total += val ))
done
echo $total
然后用法:
addnums < /tmp/nums
【讨论】:
【参考方案8】:为反引号(“`”)的可读性提前道歉,但这些在 bash 以外的 shell 中工作,因此更易于粘贴。如果您使用接受它的 shell,则 $(command ...) 格式比 `command ...` 更具可读性(因此可调试),因此请随意修改以保持理智。
我的 bashrc 中有一个简单的函数,它将使用 awk 计算一些简单的数学项
calc()
awk 'BEGINprint '"$@"' '
这将执行 +,-,*,/,^,%,sqrt,sin,cos, 括号 ....(以及更多取决于您的 awk 版本)...您甚至可以使用 printf 和格式化浮点输出,但这就是我通常所需要的
对于这个特定的问题,我会简单地为每一行做这个:
calc `echo "$@"|tr " " "+"`
所以对每一行求和的代码块看起来像这样:
while read LINE || [ "$LINE" ]; do
calc `echo "$LINE"|tr " " "+"` #you may want to filter out some lines with a case statement here
done
如果您只想逐行求和的话。但是对于数据文件中的每个数字
VARS=`<datafile`
calc `echo $VARS// /+`
顺便说一句,如果我需要在桌面上快速做一些事情,我会使用这个:
xcalc()
A=`calc "$@"`
A=`Xdialog --stdout --inputbox "Simple calculator" 0 0 $A`
[ $A ] && xcalc $A
【讨论】:
你用的什么古代shell不支持$()?【参考方案9】:
我已经对现有答案进行了快速基准测试
仅使用标准工具(对于lua 或rocket 之类的内容,请见谅),
是真正的单线,
能够添加大量数字(1 亿),并且
很快(我忽略了那些耗时超过一分钟的)。
我总是将 1 到 1 亿的数字相加,这可以在我的机器上在一分钟内完成多种解决方案。
结果如下:
Python
:; seq 100000000 | python -c 'import sys; print sum(map(int, sys.stdin))'
5000000050000000
# 30s
:; seq 100000000 | python -c 'import sys; print sum(int(s) for s in sys.stdin)'
5000000050000000
# 38s
:; seq 100000000 | python3 -c 'import sys; print(sum(int(s) for s in sys.stdin))'
5000000050000000
# 27s
:; seq 100000000 | python3 -c 'import sys; print(sum(map(int, sys.stdin)))'
5000000050000000
# 22s
:; seq 100000000 | pypy -c 'import sys; print(sum(map(int, sys.stdin)))'
5000000050000000
# 11s
:; seq 100000000 | pypy -c 'import sys; print(sum(int(s) for s in sys.stdin))'
5000000050000000
# 11s
Awk
:; seq 100000000 | awk 's+=$1 END print s'
5000000050000000
# 22s
粘贴 & Bc
这在我的机器上耗尽了内存。它适用于输入大小的一半(5000 万个数字):
:; seq 50000000 | paste -s -d+ - | bc
1250000025000000
# 17s
:; seq 50000001 100000000 | paste -s -d+ - | bc
3750000025000000
# 18s
所以我猜这 1 亿个数字大约需要 35 秒。
Perl
:; seq 100000000 | perl -lne '$x += $_; END print $x; '
5000000050000000
# 15s
:; seq 100000000 | perl -e 'map $x += $_ <> and print $x'
5000000050000000
# 48s
红宝石
:; seq 100000000 | ruby -e "puts ARGF.map(&:to_i).inject(&:+)"
5000000050000000
# 30s
C
为了比较,我编译了 C 版本并对其进行了测试,只是想知道基于工具的解决方案有多慢。
#include <stdio.h>
int main(int argc, char** argv)
long sum = 0;
long i = 0;
while(scanf("%ld", &i) == 1)
sum = sum + i;
printf("%ld\n", sum);
return 0;
:; seq 100000000 | ./a.out
5000000050000000
# 8s
结论
C 当然是最快的 8 秒,但 Pypy 解决方案仅在 11 秒内增加了大约 30% 的少量开销。但是,公平地说,Pypy 并不完全是标准的。大多数人只安装了 CPython,它的速度要慢得多(22 秒),与流行的 Awk 解决方案一样快。
基于标准工具的最快解决方案是 Perl (15s)。
【讨论】:
paste + bc 方法正是我想要对十六进制值求和的方法,谢谢!
只是为了好玩,在 Rust 中:use std::io::self, BufRead; fn main() let stdin = io::stdin(); let mut sum: i64 = 0; for line in stdin.lock().lines() sum += line.unwrap().parse::<i64>().unwrap(); println!("", sum);
很棒的答案。不要吹毛求疵,但如果您决定包含那些运行时间较长的结果,那么答案会更棒!
@StevenLu 我觉得答案会更长,因此不太棒(用你的话来说)。但我可以理解这种感觉不需要每个人都分享:)
下一步:numba + 并行化【参考方案10】:
简单的 bash:
$ cat numbers.txt
1
2
3
4
5
6
7
8
9
10
$ sum=0; while read num; do ((sum += num)); done < numbers.txt; echo $sum
55
【讨论】:
较小的一个班轮:***.com/questions/450799/… @rjack,num 是在哪里定义的?我相信它以某种方式连接到< numbers.txt 表达式,但不清楚如何。【参考方案11】:
粘贴通常会合并多个文件的行,但它也可用于将文件的各个行转换为单行。分隔符标志允许您将 x+x 类型的方程传递给 bc。
paste -s -d+ infile | bc
或者,当从标准输入管道时,
<commands> | paste -s -d+ - | bc
【讨论】:
非常好!我会在“+”之前放一个空格,只是为了帮助我更好地解析它,但这对于通过 paste & 然后 bc 来管道一些内存数字非常方便。 比 awk 解决方案更容易记住和输入。另外,请注意paste 可以使用破折号 - 作为文件名 - 这将允许您将命令输出中的数字通过管道传输到粘贴的标准输出中,而无需先创建文件:<commands> | paste -sd+ - | bc跨度>
我有一个包含 1 亿个数字的文件。 awk 命令耗时 21s;粘贴命令需要 41 秒。但是很高兴见到“粘贴”!
@Abhi: 有趣:D 我想我需要 20 多岁才能弄清楚 awk 命令,所以直到我尝试 1 亿和一个数字,它才会变得平衡:D
@George 不过,您可以省略-。 (如果您想将文件与标准输入结合起来,这很有用)。【参考方案12】:
为了完整起见,还有一个R解决方案
seq 1 10 | R -q -e "f <- file('stdin'); open(f); cat(sum(as.numeric(readLines(f))))"
【讨论】:
【参考方案13】:Python 中的单行版本:
$ python -c "import sys; print(sum(int(l) for l in sys.stdin))"
【讨论】:
上面的单行代码不适用于 sys.argv[] 中的文件,但那行代码可以 ***.com/questions/450799/… 是的——作者说他要将另一个脚本的输出通过管道传输到命令中,我试图让它尽可能短:) 较短的版本是python -c"import sys; print(sum(map(int, sys.stdin)))"
我喜欢这个答案,因为它易于阅读和灵活。我需要一组目录中小于 10Mb 的文件的平均大小,并将其修改为:find . -name '*.epub' -exec stat -c %s '' \; | python -c "import sys; nums = [int(n) for n in sys.stdin if int(n) < 10000000]; print(sum(nums)/len(nums))"
如果混入了一些文本,也可以过滤掉非数字:import sys; print(sum(int(''.join(c for c in l if c.isdigit())) for l in sys.stdin))【参考方案14】:
一点awk应该可以吗?
awk 's+=$1 END print s' mydatafile
注意:如果您要添加超过 2^31 (2147483647) 的任何内容,某些版本的 awk 会出现一些奇怪的行为。有关更多背景信息,请参见 cmets。一种建议是使用printf 而不是print:
awk 's+=$1 END printf "%.0f", s' mydatafile
【讨论】:
这个房间里有很多 awk 的爱!我喜欢如何修改像这样的简单脚本,只需将 $1 更改为 $2 即可添加第二列数据 没有实际限制,因为它将输入作为流处理。所以,如果它可以处理 X 行的文件,你可以很确定它可以处理 X+1。 我曾经编写了一个基本的邮件列表处理器,其中包含一个通过假期实用程序运行的 awk 脚本。美好时光。 :) 只是将它用于:计算所有文档的页面脚本:ls $@ | xargs -i pdftk dump_data | grep NumberOfPages | awk 's+=$2 END print s'
小心,它不适用于大于 2147483647(即 2^31)的数字,这是因为 awk 使用 32 位有符号整数表示。请改用awk 's+=$1 END printf "%.0f", s' mydatafile。【参考方案15】:
C++(简体):
echo 1..10 | scc 'WRL n+=$0; n'
SCC 项目 - http://volnitsky.com/project/scc/
SCC 是 shell 提示符下的 C++ sn-ps 评估器
【讨论】:
【参考方案16】:使用环境变量 tmp
tmp=awk -v tmp="$tmp" 'print $tmp" "$1' <filename>|echo $tmp|sed "s/ /+/g"|bc
tmp=cat <filename>|awk -v tmp="$tmp" 'print $tmp" "$1'|echo $tmp|sed "s/ /+/g"|bc
谢谢。
【讨论】:
【参考方案17】:对于红宝石爱好者
ruby -e "puts ARGF.map(&:to_i).inject(&:+)" numbers.txt
【讨论】:
【参考方案18】:dc -f infile -e '[+z1<r]srz1<rp'
请注意,带有负号前缀的负数应转换为dc,因为它使用_ 前缀而不是- 前缀。例如,通过tr '-' '_' | dc -f- -e '...'。
编辑:由于这个答案“默默无闻”得到了这么多票,这里有一个详细的解释:
表达式[+z1<r]srz1<rpdoes the following:
[ interpret everything to the next ] as a string
+ push two values off the stack, add them and push the result
z push the current stack depth
1 push one
<r pop two values and execute register r if the original top-of-stack (1)
is smaller
] end of the string, will push the whole thing to the stack
sr pop a value (the string above) and store it in register r
z push the current stack depth again
1 push 1
<r pop two values and execute register r if the original top-of-stack (1)
is smaller
p print the current top-of-stack
作为伪代码:
-
将“add_top_of_stack”定义为:
-
从堆栈中删除两个顶部值并将结果添加回来
如果堆栈有两个或多个值,则递归运行“add_top_of_stack”
要真正了解dc 的简单性和强大功能,这里有一个工作 Python 脚本,它实现了来自dc 的一些命令并执行上述命令的 Python 版本:
### Implement some commands from dc
registers = 'r': None
stack = []
def add():
stack.append(stack.pop() + stack.pop())
def z():
stack.append(len(stack))
def less(reg):
if stack.pop() < stack.pop():
registers[reg]()
def store(reg):
registers[reg] = stack.pop()
def p():
print stack[-1]
### Python version of the dc command above
# The equivalent to -f: read a file and push every line to the stack
import fileinput
for line in fileinput.input():
stack.append(int(line.strip()))
def cmd():
add()
z()
stack.append(1)
less('r')
stack.append(cmd)
store('r')
z()
stack.append(1)
less('r')
p()
【讨论】:
dc 只是选择使用的工具。但我会用更少的堆栈操作来做到这一点。假设所有行都包含一个数字:(echo "0"; sed 's/$/ +/' inp; echo 'pq')|dc。
在线算法:dc -e '0 0 [+?z1<m]dsmxp'。所以我们不会在处理之前将所有数字保存在堆栈上,而是一个一个地读取和处理它们(更准确地说,是一行一行,因为一行可以包含多个数字)。请注意,空行可以终止输入序列。
@ikrabbe 太好了。它实际上可以再缩短一个字符:sed 替换中的空格可以删除,因为dc 不关心参数和运算符之间的空格。 (echo "0"; sed 's/$/+/' inputFile; echo 'pq')|dc【参考方案19】:
与jq:
seq 10 | jq -s 'add' # 'add' is equivalent to 'reduce .[] as $item (0; . + $item)'
【讨论】:
有没有办法用rq做到这一点?
我想我知道下一个问题可能是什么,所以我会在这里添加答案:) 计算平均值: seq 10 | jq -s 'add / length' ref here【参考方案20】:
您可以使用您喜欢的“expr”命令,您只需先稍微修改一下输入即可:
seq 10 | tr '[\n]' '+' | sed -e 's/+/ + /g' -e's/ + $/\n/' | xargs expr
流程是:
"tr" 将 eoln 字符替换为 + 符号, sed 在 '+' 两边用空格填充,然后从行中去掉最后一个 + xargs 将管道输入插入命令行以供 expr 使用。【讨论】:
【参考方案21】:替代的纯 Perl,可读性强,不需要包或选项:
perl -e "map $x += $_ <> and print $x" < infile.txt
【讨论】:
或更短一点: perl -e 'map $x += $_ ;打印 $x' infile.txt 大量输入 1000 万个数字所需的内存几乎为 2GB【参考方案22】:您可以使用 Alacon - Alasql 数据库的命令行实用程序来完成。
它适用于 Node.js,所以你需要安装 Node.js 然后 Alasql 包:
要从标准输入计算总和,您可以使用以下命令:
> cat data.txt | node alacon "SELECT VALUE SUM([0]) FROM TXT()" >b.txt
【讨论】:
【参考方案23】:我的版本:
seq -5 10 | xargs printf "- - %s" | xargs | bc
【讨论】:
短:seq -s+ -5 10 | bc【参考方案24】:
实时求和,让您监控一些数字运算任务的进度。
$ cat numbers.txt
1
2
3
4
5
6
7
8
9
10
$ cat numbers.txt | while read new; do total=$(($total + $new)); echo $total; done
1
3
6
10
15
21
28
36
45
55
(在这种情况下无需将$total设置为零。完成后您也无法访问$total。)
【讨论】:
【参考方案25】:sed 's/^/.+/' infile | bc | tail -1
【讨论】:
【参考方案26】:简单的php
cat numbers.txt | php -r "echo array_sum(explode(PHP_EOL, stream_get_contents(STDIN)));"
【讨论】:
【参考方案27】:Rebol 中的单线:
rebol -q --do 's: 0 while [d: input] [s: s + to-integer d] print s' < infile.txt
不幸的是,上述内容目前在 Rebol 3 中还不起作用(INPUT 不流式传输 STDIN)。
所以这里有一个临时解决方案,它也适用于 Rebol 3:
rebol -q --do 's: 0 foreach n to-block read %infile.txt [s: s + n] print s'
【讨论】:
【参考方案28】:我的十五美分:
$ cat file.txt | xargs | sed -e 's/\ /+/g' | bc
例子:
$ cat text
1
2
3
3
4
5
6
78
9
0
1
2
3
4
576
7
4444
$ cat text | xargs | sed -e 's/\ /+/g' | bc
5148
【讨论】:
我的输入可能包含空行,所以我使用了您在此处发布的内容以及grep -v '^$'。谢谢!
哇!!你的回答太棒了!我个人最喜欢的胎面
喜欢这个并为管道 +1。对我来说非常简单易用的解决方案【参考方案29】:
...和 PHP 版本,只是为了完整起见
cat /file/with/numbers | php -r '$s = 0; while (true) $e = fgets(STDIN); if (false === $e) break; $s += $e; echo $s;'
【讨论】:
可以更短:seq 1 10 | php -r ' echo array_sum(file("php://stdin")) 。 PHP_EOL; '【参考方案30】:#include <iostream>
int main()
double x = 0, total = 0;
while (std::cin >> x)
total += x;
if (!std::cin.eof())
return 1;
std::cout << x << '\n';
【讨论】:
以上是关于axure 中继器的每行怎么求和输出到外面?网上竟没有这信息,高手进来的主要内容,如果未能解决你的问题,请参考以下文章