Hash表从了解到深入(浅谈)
Posted 我不管,我就是DBA
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hash表从了解到深入(浅谈)相关的知识,希望对你有一定的参考价值。
· Hasn表,将一个数据进行Value化,再进行一个映射关系到Key直接进行访问的一个数据结构,这样可以通过直接的计算进行数据的访问和插入。关于Hash表的基本概念这里就不一一叙述,可以通过百度了解Hash的一些基本概念。今天这里主要讲2个点,Hash冲突与Hash构建函数算法。
1,一个基本的Hash表是什么?
很多人如果只是简单了解过Hash表的结构,可能提到这个数据结构的第一个印象是Hash是由一个数组和一个链表(链表这里可能有很多种形态)组成的数据结构。大错特错,个人感觉这完全是一种错误的植入方式,首先Hash本身的描述仅仅只是一个数组,我们根据每次要插入或者访问的数据,通过Value->Key的一个映射,通过Key直接访问数组下标进行数据插入或访问,在插入数据时,如果当前下标已经放入了某个数值,则在这个下标的基础上向后移动,直到某一个块还没有被插入数据,就将当前需要插入的数据放入当前块。而之所以很多不太了解Hash表的人将其说成一个数组加一个链表,是因为这种数据结构是采用Hash的拉链法进行一个解决Hash冲突的方法而已。
2,什么是Hash冲突?
Hash冲突简单来说就是两个数据,虽然Value不相同(某些存储也会需要存入相同的Value),但通过Hash映射函数所得到的Key是相同的,这两个数据都要存入Hash表中时,就会产生冲突。而我们要解决冲突,就需要拉链法(常用且简单)或一些其他的方法,进行冲突解决,如果Key相同,拉链法是在当前哈希表(数组)存放一个链表的头,若两个数据的Key均相同,则将数据分别存放在链表中。
3,常见解决冲突的方法?
常见解决除了上述的拉链法外,还有一些比较常用的方法像“开放定址法”,“再哈希法”,“建立公共溢出区”。这三种方法的实现百度就有很多,在此处不详细介绍,个人比较喜欢拉链法,也是比较容易实现的一种,就是拉下去会增加空间的开销。
4,装载因子是什么?
装载因子 = 添加的数据总数 / 哈希表的大小,称为饱和程度。一般来说饱和程度越小,对于我们Hash搜索的效率也是越高的,但同样,这就代表这空间的代价也是很高的,往往很多空间是浪费掉没有使用的。比如装载因子为0.2,就表示哈希表只有20%的空间被使用,其余浪费。所以为了平衡这个点,大部分采用0.75作为装载因子,如果超过,就动态进行哈希的重构,增加哈希表的大小。
5,哈希表的大小怎么设定最好?
在开始构造哈希表的时候,由于哈希表的大小是固定的,虽然可以动态调整,但重构起来是比较浪费时间的,所以一般在开始需要根据实际项目情况定好一个大小值。至于大小取什么比较合适,网上有一种说法是取质数,个人理解这种取质数的方法仅仅适用于 Key = Value % Buff 。先讨论一下这种情况,算法导论中有提到,针对于取余这种情况,可以选择远离2的幂次方的质数,其次是普通质数,最后才是刚好为2^幂次数。但在我看来,这完全是一种错误指向。举个例子:为什么最差的宣发是2^幂次,假设对4/8/16等等取余为1,那么对2取余同样是1,这样的一个理解特别容易使人进入一个误区,觉得只要是2^幂次数大小,就会造成不均匀。看似有点道理,但用概率论的想法去思考这个问题,感觉完全是因果没有任何关系,牛唇不对马嘴。
因为随着哈希表大小的增加,取余的范围也会增加,对于任意常熟对其取余,所得到的概率应该均是相等才对,比如1-100的自然数,无论取余多少,都会是类似于桶的一种塞法,每个桶先塞一个,轮询完后回来从第一个继续塞,所以个人认为无论对于取余这种情况,哈希大小选定只要是某个区间内是合适的,就应该是可以的。不在乎是否为2^幂次还是质数(有特殊规律的数据群,需要依靠其规律设计大小)。这一段仅仅时候从常熟概率相同的角度分析,看来是很容易分析到的一种现象,但同样,后面通过一些公式,我们又能证明出另一种可能性。
一个数对一个2^幂次取余其实就是 Value % Key = Value & (Key - 1),所以也就是说这个余数只是Value二进制中的后几位而已,若后几位相同的情况下,前面的位数无论取何值,结果都是相同的,这样产生冲突的可能性就大了一些。
综上所述,如果是已经知道了是一个自然数均匀分布的数据群,那无论取质数或是2^幂次数都是没什么影响的,但如果是某些特殊群,比如后几位或前几位经常会出现相同值,那我们使用远离2^次幂的质数大小就能有效的减少冲突的产生。
(这段讲的真的很乱,就是转折来转折去,最终结论还是建议可以遵守远离2^次幂的质数大小)。
6,Hash构建函数-常见的?
第一个问题提到的插入方法就是最基本的构建方法,直接寻址法,百度中也有一些基本的Hash构造方法,比如:
⑴ 数字分析法:先对可能插入的数据进行简单的分析,比如是数字,那就看有几位,那几位基本是固定的,那我们就用剩下位数的数字作为Key来存放数据。举个例子,比如存放出生日期,那年月日中3个参数中,年份这个参数前两个参数的数据基本是一致的,那就可以直接抛弃,只以十位和个位的数来作为Key进行判断。
⑵ 除留余数法:此方法为 Key = Value % Buff 进行计算的,总体来说这个简单的构建方法也是我比较喜欢的,如果不是做一些大项目,仅仅用于小的数据存储的话,完全可以使用这种构建方法进行Hash构建。
7,好一些的Hash构建算法?
在这个大数据横飞的时代,如果仅仅使用一些简单的Hash构造那肯定是不能满足我们的要求,所以前人们就研究出了许多适用于各种环境下的Hash构造算法,都是很高效,并且现在的项目也在使用的一些算法。
⑴ BKDRHash构造:
BKDR算法,主要应用场景是对字符串数据进行Hash构造的方法,我们先抛开算法一说,从最初开始想办法。首先要将字符串Value化,最常用的方法就是字符串中的每个字符进行相加,得到的值就是Value,如果直接使用Value作为Key,那么Value(ad) = a + d = 97 + 100 = 197 = 98 + 99 = Value(bc)。很明显,立即就产生了碰撞,这当然不是我们想要的一种构造方法了,那继续进行下去,根据高数中的离散性分析,在无系数线性方程中加入系数管控是可以一定程度上加大离散性。所以我们将Value的计算方法进一步修改为:
Value(ad) = k1 * a + k2 * d 。这样得出来的Value就没那么容易产生冲突了,当然也不能完全避免,至于如何最大化的降低冲突的概率,我们就需要研究一下 k1,k2 系数的取值为多少时,可以最大化的降低冲突概率。
系数取值:首先由于字符串无法去评估它的长度,有可能是一个很长的字符串,我们如果人为的去设定 k1,k2 的定值,一旦字符串长了,我们就需要预先设定很多值,这样无疑很麻烦。所以我们可以给出一个固定的系数值k,方程式中的 k1,k1 完全可以替换为 k^0,k^1.....。替换后的方程就是 Value(ad) = k^1 * a + k^0 * d,其中 k ≠ 0,1。设字符串为数组p,元素个数为n,就有公式:
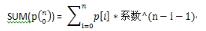
(Ps:这个博客居然不能插入数学公式,我服)
继续取值的问题,到这步我们只需要对 k 进行一个合理的取值就OK。网上看过有人对这个值进行讨论是分为2的幂的偶数、非2的幂的偶数、奇数三个部分讨论。但作为一名学数学的人,总觉得喜欢分为偶数和奇数两种进行讨论,而实验之后发现也完全是可以推导下去的(网上之所以分了2的幂,应该是为了逐步说明,这里就不逐步了)。
假设Value的存储类型为Hash默认的 unsigned int 类型。如果取 k 为偶数,k 总是能分解为 k = 2 * k1(偶数或奇数)。若是字符串的长度大于等于33时,第一位的系数就会变成 k = 2 * k1 ^ 32 = 2 ^ 32 * k1 ^ 32,而熟悉编程的人都知道,如果某个数不断增加,超过类型范围会被直接抛弃,所以无论哪个字符串在乘以 2 ^ 32 之后第一位就会被抛弃,就造成了只要后面32位字符不变化,前面的字符无论怎么改变,都会发生冲突。所以系数去偶数是行不通的。
那再来讨论 k 取奇数,k = 2 * k1 + 1。则 k ^ n = 2 * k1 ^ n + 1。系数后面永远有一个1,所以就可以保证每个字符的改变都会影响到Value值,这样就保证了我们的冲突可能降到最小。上述的方法就是BkdrHash构造算法。
⑵ 一致性Hash构造算法:
一致性Hash的构造经常被用来进行服务器分配,比如一个服务器集群组,可以通过这种Hash分配的方法将新连入的请求分配给某个服务器进行处理。具体的一个原理是:在移除或添加一个Cache时,它能够尽可能小的改变已存在Key映射关系,满足单调性。
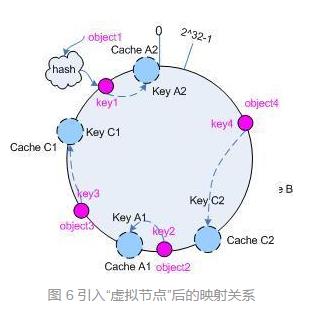
对于一致性Hash,我们可以把它想象成一个环形的控件,首为0,尾为2^32 - 1。首先当请求到来时,先将请求映射到Hash空间中,这时候再把服务器的节点映射到Hash空间中,到这里我们先看几个简单的图,来实例一下大致如何映射。
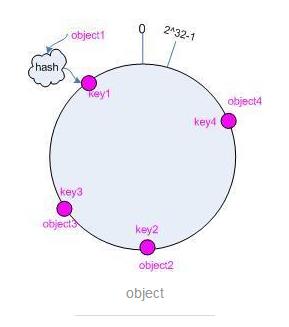
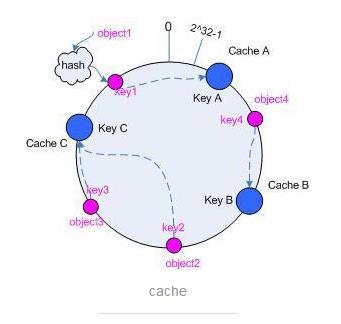
4个请求通过Hash函数映射到哈希表中 3个服务器也进行映射
观察第二张图的箭头,比如 Key1 会被分到 Cache A 处理,Key 4 会被分到 Cache B 处理, Key 2 和 Key 3 会被分给 Cache C处理。如果其中一个服务器挂掉,如Cache B挂掉,就会将 Key 4 的请求交给 Cache C
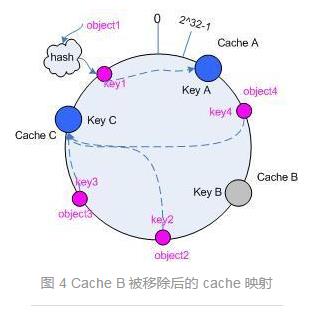
当然如果说某种情况下导致服务器不均匀,就需要进行负载均衡的原理进行重新搭建虚拟映射,对服务进行统计划分后,将服务器的已存在的映射进行再次虚拟映射,使得每个服务器所接受到的请求基本是平均的
本次的分享大致就是这些,基本都是对Hash有过基本的了解后,通过本次文章,可以大致了解到一些实用的Hash构建方法以及怎么保证冲突最小化的办法。
以上是关于Hash表从了解到深入(浅谈)的主要内容,如果未能解决你的问题,请参考以下文章