读书笔记125
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了读书笔记125相关的知识,希望对你有一定的参考价值。
第一章 Linux内核简介
1.1 Unix的历史
- 由于Unix系统设计简洁并且在发布时提供源代码,所以许多其他组织和团体都对它进了进一步的开发。
- Unⅸ虽然已经使用了40年,但计算机科学家仍然认为它是现存操作系统中最强大和最优秀的系统。从1969年诞生以来,由Dennis Ritchie和Ken Thompson的灵感火花点亮的这个Unix产物已经成为一种传奇,它历经了时间的考验依然声名不坠。
1.2 追寻Linus足迹:Linux简介
1.3 操作系统和内核简介
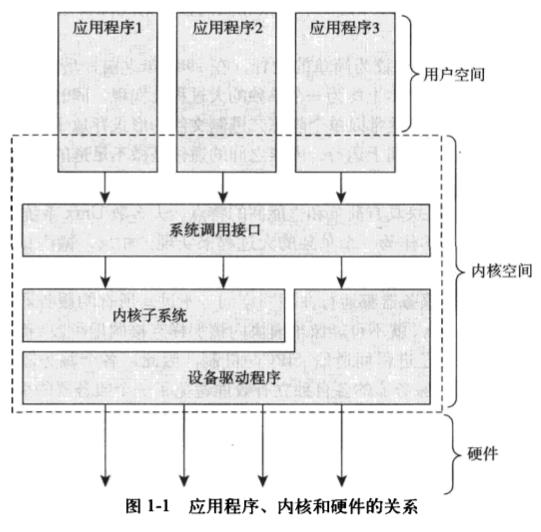
处理器在任何指定时间点上的活动范围可以概括为下列三者之一:
- 运行于内核空间,处于进程上下文,代表某个特定的进程执行。
- 运行于内核空间,处于中断上下文,与任何进程无关,处理某个特定的中断。
- 运行于用户空间,执行用户进程。
1.4 Linux内核和传统Unix内核的比较
Linux内核和传统UNIX内核特点的比较
- Linux支持动态加载内核模块。
- Linux支持对称多处理(SMP)机制
- Linux内核可以抢占。
- Linux内核并不区分线程和其他的一般进程
1.5 Linux内核版本
命名规则: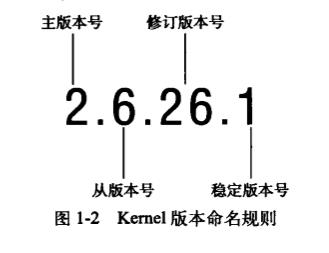
1.6 Linux内核开发者社区
这个社区最重要的论坛:Linux kernel mailing list(lkml)
1.7 小结
第二章 从内核出发
这一章介绍Linux内核一些基本常识:从何处获取源码,如何编译它,又如何安装新内核。
2.1 获取内核源码
- 在Linux内核官方网站http://www.kernel.org,可以随时获取当前版本的Linux源代码,可以是完整的压缩形式,也可以是增量补丁形式。
- 除非特殊情况下需要Linux源码的旧版本,一般都希望拥有最新的代码。kernel.org是源码的库存之处,那些领导潮流的内核开发者所发布的增量补丁也放在这里。
2.1.1 使用Git
2.1.2 安装内核源代码
- 如果压缩形式是bzip2,则运行:
$ tar xvjf linux-x.y.z.tar.bz2 - 如果压缩形式是GNU的zip,则运行
$ tar xvzf linux-x.y.z.tar.gz
解压后的源代码位于linux-x.y.z.目录下。 - 何处安装源码:内核源码一般安装在/usr/src/linux目录下。
2.1.3 使用补丁
- 内核版本在不断更新,增量补丁可以作为版本转移的桥梁。
- 优点:节约了带宽,还省了时间
- 要应用增量补丁,从你的内部源码树开始,只是运行:
$ patch p1 < ../patch-x.y.z - 一般说来,一个给定版本的内核补丁总是打在前一个版本上
2.2 内核源码树
内核源码树由很多目录组成,而大多数目录又包含更多的子目录。源码树的根目录及其子目录如表所示。
目录 描述
arch 特定体系结构的源码
crypto Crypto API
Documentation 内核源码文档
drivers 设备驱动程序
fs VFS和各种文件系统
include 内核头文件
init 内核引导和初始化
ipc 进程间通信代码
kernel 像调度程序这样的核心子系统
lib 通用内核函数
mm 内存管理子系统和VM
net 网络子系统
scripts 编译内核所用的脚本
security Linux安全模块
sound 语音子系统
usr 早期用户空间代码 (所谓的 initramfs)2.3 编译内核
2.3.1 配置内核
- 在编译内核之前,首先你必须配置它。
- 可以配置的各种选项,以CONFIG_FEATURE形式表示,其前缀为CONFIG。
- 配置选项既可以用来决定那些文件编译进内核,也可以通过预处理命令处理代码。
- 这些配置项要么是二选一,要么是三选一。二选一就是yes或no。比如说CONFIG_PREEMPT就是二选一,表示内核抢占功能是否开启。三选一可以是yes、no或module。Module意味着该配置项被选定了,但编译的时候这部分功能的实现代码是以模块(一种可以动态安装的独立代码段)的形式生成。在三选一的情况下,显然yes选项表示把代码编译进主内核映像中,而不是作为一个模块。驱动程序一般都用三选一的配置项。
2.3.2 减少编译的垃圾信息
- 我们希望在编译时看到错误和警告信息,但对匆匆掠过屏幕的垃圾信息不感兴趣,可以用下面的技巧来实现愿望:
make > some_other_file - 一旦需要查看编译的输出信息,可以查看这个文件。不过,因为错误和警告都会在屏幕上显示,所以你需要看这个文件的可能性不大。事实上,我只不过敲入如下命令
$ make > /dev/null
这就把无用的输出信息重定向到永无返回值的黑洞/dev/null。
2.3.3 衍生多个编译作业
- 为了以多个作业编译内核,使用以下命令:
$ make -jn - 这里,n是要衍生的作业数,在实际中,每个处理器上一般衍生一个或者两个作业。例如,在一个双处理器上,可以输入如下命令:
$ make –j4
2.3.4 安装新内核
- 模块的安装是自动的,也是独立于体系结构的。以root身份,只要运行:
% make modules_install
就可以把所有已编译的模块安装到正确的主目录/lib下。
2.4 内核开发的特点
Linux内核编程与用户空间内应用程序开发的差异
- Linux内核编程时不能访问C库
- Linux内核编程时必须使用GNU C
- Linux内核编程时缺乏像用户空间那样的内存保护机制。
- Linux内核编程时浮点数很难使用。
- 内核只有一个很小的定长堆栈。
- 由于内核支持异步中断、抢占式和SMP,因此必须时刻注意同步和并发。
- 要考虑可移植性的重要性。
2.4.1 无libc库抑或无标准头文件
- 大部分常用的C库函数在内核中都已经得到实现了。比如说操作字符串的函数组就位于lib/string.c文件中。只要包含<linux/string.h>头文件,就可以使用它们。
- 在所有没有实现的函数中,最著名的就数printf()函数了。内核代码虽然无法调用printf(),但它可以调用printk()函数。
2.4.2 GNU C
内核开发者使用的C语言涵盖了ISO C995标准和GNU C扩展特性。
- 内联(inline)函数
- 内联汇编
- 分支声明
2.4.3 没有内存保护机制
- 如果一个用户程序试图进行一次非法的内存访问,内核会发现这个错误,发送 SIGSEGV,并结束整个进程。
- 内核中发生的内存错误会导致oops,这是内核中出现的最常见的一类错误。
- 内核中的内存都不分页。
2.4.4 不要轻易在内核中使用浮点数
- 在执行浮点指令时到底会做些什么,因体系结构不同,内核的选择也不同,但是,内核通常捕获陷阱并做相应处理。
- 和用户空间进程不同,内核并不能完美地支持浮点操作,因为它本身不能陷入。
2.4.5 容积小而固定的栈
- 内核栈的准确大小随体系结构而变。在x86上,栈的大小在编译时配置,可以是4KB也可以是8KB。
- 从历史上说,内核栈的大小是两页,这就意味着,32位机的内核栈是8KB,而64位机是16KB,这是固定不变的。
- 每个处理器都有自己的栈。
2.4.6 同步和并发
- Linux是抢占多任务操作系统。内核的进程调度程序即兴对进程进行调度和重新调度。内核必须对这些任务同步。
- Linux内核支持多处理器系统。
- 中断是异步到来的,完全不顾及当前正在执行的代码。
- Linux内核可以抢占。
2.4.7 可移植性的重要性
- Linux是一个可移植的操作系统,
- 必须把体系结构相关的代码从内核代码树的特定目录中适当地分离出来.
5.1 与内核通信57
系统调用在用户空间进程和硬件设备之间添加了一个中间层,该层主要作用有三个:
- 首先它为用户空间提供了一种硬件的抽象接口,举例来说当需要读写文件的时候,应用程序就可以不去管磁盘类型和介质,甚至不用去管文件所在的文件系统到底是哪种类型。
- 第二,系统调用保证了系统的稳定和安全,作为硬件设备和应用程序之间的中间人,内核可以基于权限、用户类型和其他一些规则对需要进行的访问进行裁决,举例来说,这样可以避免应用程序不正确地使用硬件设备,窃取其他进程的资源,或做出其他危害系统的事情。
- 第三,在第3章中曾经提到过,每个进程都运行在虚拟系统中,而在用户空间和系统的其余部分提供这样一层公共接口,也是出于这种考虑,如果应用程序可以随意访问硬件而内核又对此一无所知的话几乎就没法实现多任务和虚拟内存,当然也不可能实现良好的稳定性和安全性。
在Linux中,系统调用是用户空间访问。内核的唯一手段;除异常和陷入外,它们是内核唯一的合法入口。
本章重点强调Linux系统调用的规则和实现方法。
5.2 API、POSIX和C库57
- 一般情况下,应用程序通过在用户空间实现的应用编程接口而不是直接通过系统调用来编程。
- 应用程序使用的这种编程接口实际上并不需要和内核提供的系统调用对应。一个API定义了一组应用程序使用的编程接口,它们可以实现成一个系统调用,也可以通过调用多个系统调用来实现,而完全不使用任何系统调用也不存在问题。
- 实际上,API可以在各种不同的操作系统实现,给应用程序提供完全相同的接口,而它们本身在这些系统上的实现却可能迥异。
- API、POSIX和C库以及系统调用之间的关系如下图
图一 - 在Unix世界中,最流行的应用编程接口是基于POSIX标准的。
- 关于Unix的接口设计有一句格言:提供机制而不是策略。
5.3 系统调用58
- 要访问系统调用,通常通过C库中定义的函数调用来进行。
- 系统调用最终具有一种明确的操作。
- 如何定义系统调用
首先,注意函数声明中的asmlinkage限定词,这是一个编译指令,通知编译器仅从栈中提取该函数的参数。所有的系统调用都需要这个限定词。
其次函数返回long。为了保证32位和64位系统的兼容,系统调用在用户空间和内核空间有不同的返回值类型,在用户空间为int在内核空间为long。
最后,注意系统调用get_pid()中的在内核中被定义成sys_getpid()。这是Linux中所有系统调用都应该遵守的命名规则,系统调用bar()在内核中也实现为sys_bar()函数。
5.3.1 系统调用号59
- 在Linux中,每个系统调用被赋予一个系统调用号。
这样,通过这个独一无二的号就可以关联系统调用。
当用户空间的进程执行一个系统调用的时候,这个系统调用号就用来指明到底是要执行哪个系统调用。 - 系统调用号相当重要,一旦分配就不能再有任何变更,否则编译好的应用程序就会崩溃。此外,如果一个系统调用被删除,它所占用的系统调用号也不允许被回收利用,否则,以前编译过的代码会调用这个系统调用,但事实上却调用的是另一个系统调用。
- Linux有一个“未实现”系统调用sys_ni_syscall(),它除了返回―ENOSYS外不做任何其他工作,这个错误号就是专门针对无效的系统调用而设的。虽然很罕见,但如果一个系统调用被删除,或者变得不可用,这个函数就要负责“填补空缺”。
- 内核记录了系统调用表中的所有已注册过的系统调用的列表,存储在sys_call_table中。
- 每一种体系结构中,都明确定义了这个表,在×86-64中,它定义于arch/i386/kernel/syscall_64.c文件中。这个表为每一个有效的系统调用指定了唯一的系统调用号。
5.3.2 系统调用的性能59
Linux系统执行快的原因:
- 很短的上下文切换时间。
- 系统调用处理程序和每个系统调用本身也十分简洁。
5.4 系统调用处理程序60
用户空间的程序无法执行内核代码。
通知内核的机制是靠软中断实现的:
通过引发一个异常来促使系统切换到内核态去执行异常处理程序,此时的异常处理程序实际上就是系统调用处理程序,在×86系统上预定义的软中断是中断号128。通过int¥0X80指令触发该中断,这条指令会触发一个异常导致系统切换到内核态并执行第128号异常处理程序,而该程序正是系统调用处理程序,这个处理程序名字起得很贴切,叫system_call().它与硬件体系结构紧密相关。
5.4.1 指定恰当的系统调用60
- 必须把系统调用号一并传给内核。
- 在x86上,系统调用号是通过eax寄存器传递给内核的。
5.4.2 参数传递60
- 除了系统调用号外,大部分系统调用都还需要一些外部的参数输入。
- 最简单的办法是像传递系统调用号一样,把这些参数也放在寄存器里。
- 图2
- 给用户空间的返回值也通过寄存器传递。在x86系统上,它存放在eax寄存器中。
5.5 系统调用的实现61
5.5.1 实现系统调用61
- 在Linux中不提倡采用多用途的系统调用。
- 新系统调用的参数、返回值和错误码又该是什么呢?系统调用的接口应该力求简洁,参数尽可能少。系统调用的语义和行为非常关键;因为应用程序依赖于它们,所以它们应力求稳定,不做改动设想一下,如果功能多次改变会怎样。
- 新的功能是否可以追加到系统调用亦或是否某个改变将需要一个全新的函数是否可以容易地修订错误而不用破坏向后兼容?很多系统调用提供了标志参数以确保向前兼容。标志并不是用来让单个系统调用具有多个不同的行别如前所述,这是不允许的,而是为了即使增加新的功能和选项,也不破坏向后兼容或不需要增加新的系统调用。
- 设计接口的时候要尽量为将来多做考虑。你是不是对函数做了不必要的限制?系统调用设计得越通用越好。不要假设这个系统调用现在怎么用将来也一定就是这么用。系统调用的目的可能不变,但它的用法却可能改变。
- 这个系统调用可移植吗?别对机器的字节长度和字节序做假设。要确保不对系统调用做错误的假设否则将来这个调用就可能会崩溃。
5.5.2 参数验证62
- 系统调用必须仔细检查它们所有的参数是否合法有效。系统调用在内核空间执行,如果任由用户将不合法的输入传递给内核,那么系统的安全和稳定将面临极大的考验;举例来说,与文件I/O相关的系统调用必须检查文件描述符是否有效。与进程相关的函数必须检查提供的PID是否有效。必须检查每个参数,保证它们不但合法有效,而且正确。进程不应当让内核去访问那些它无权访问的资源。
- 最重要的一种检查就是检查用户提供的指针是否有效。试想,如果一个进程可以给内核传递指针而又无须检查,那么它就可以给出一个它根本就没有访问权限的指针,哄骗内核去为它拷贝本不允许它访问的数据如原本属于其他进程的数据或者不可读的映射数据。在接收一个用户空间的指针之前,内核必须保证:
1.指针指向的内存区域属于用户空间,进程决不能哄骗内核去读内核空间的数据。
2.指针指向的内存区域在进程的地址空间里,进程决不能哄骗内核去读其他进程的数据。
3.如果是读,该内存应被标记为可读;如果是写,该内存应被标记为可写;如果是可执行,该内存被标记为可执行。进程绝不能绕过内存访问权限。
5.6 系统调用上下文64
- 内核在执行系统调用的时候处于进程上下文。
- 在进程上下文中,内核可以休眠并且可以被抢占。
- 当系统调用返回的时候,控制权仍在system_call()中,它最终会负责切换到用户空间,并让用户进程继续执行下去。
5.6.1 绑定一个系统调用的最后步骤65
当编写完一个系统调用后,把它注册成一个正式的系统调用是件琐碎的工作:
1.首先,在系统调用表的最后加入一个表项。每种支持该系统调用的硬件体系都必须做这样的工作(大部分的系统调用都针对所有的体系结构)从0开始算起,系统调用在该表中的位置就是它的系统调用号。如第10个系统调用分配到的系统调用号为9)
2.对于所支持的各种体系结构,系统调用号都必须定义于<asm/unistd.h>中。
3.系统调用必须被编译进内核映象(不能被编译成模块)。这只要把它放进kernel/下的一个相关文件中就可以了,比如sys.c,它包含了各种各样的系统调用。
5.6.2 从用户空间访问系统调用67
- 通常,系统调用靠C库支持。
- Linux本身提供了一组宏。
5.6.3 为什么不通过系统调用的方式实现68
建立一个新的系统调用的好处
- 系统调用创建容易且使用方便。
- Linux系统调用的高性能显而易见。
问题是
- 你需要―个系统调用号,而这需要一个内核在处于开发版本的时候由官方分配给你。
- 需要将系统调用分别注册到每个需要支持的体系结构中去。
- 在脚本中不容易调用系统调用,也不能从文件系统直接访问系统调用。
- 由于你需要系统调用号,因此在主内核树之外是很难维护和使用系统调用的。如果仅仅进行简单的信息交换系统调用就大材小用了。替代方法:实现一个设备节点,并对此实现read()和write()。使用特定的信息进行检索。
- 像信号量这样的某些接口,可以用文件描述符来表示,因此也就可以按上述方式对其进行操作
- 把增加的信息作为一个文件放在sysfs的合适位置。
以上是关于读书笔记125的主要内容,如果未能解决你的问题,请参考以下文章