全文检索技术---Lucene
Posted oldmonk
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了全文检索技术---Lucene相关的知识,希望对你有一定的参考价值。
1 Lucene介绍
1.1 什么是Lucene
Lucene是apache下的一个开源的全文检索引擎工具包。它为软件开发人员提供一个简单易用的工具包(类库),以方便的在目标系统中实现全文检索的功能。
1.2 全文检索的应用场景
1.2.1 搜索引擎
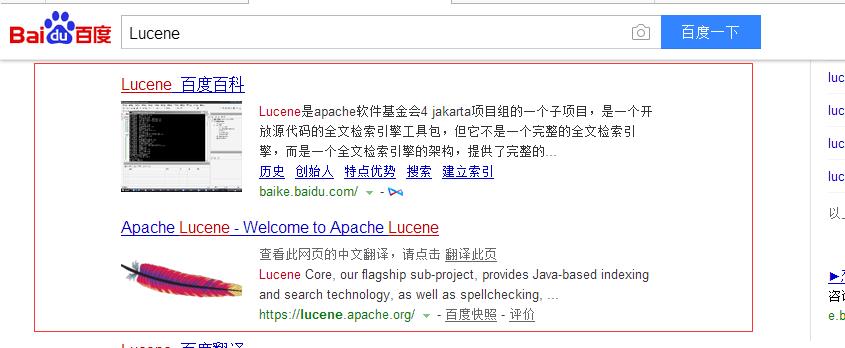
©注意:
Lucene和搜索引擎是不同的,Lucene是一套用java或其它语言写的全文检索的工具包。它为应用程序提供了很多个api接口去调用,可以简单理解为是一套实现全文检索的类库。搜索引擎是一个全文检索系统,它是一个单独运行的软件系统。
1.2.2 站内搜索(关注)
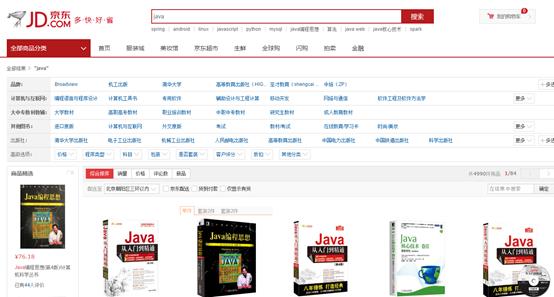
1.3 全文检索定义
全文检索首先将要查询的目标文档中的词提取出来,组成索引,通过查询索引达到搜索目标文档的目的。这种先建立索引,再对索引进行搜索的过程就叫全文检索(Full-text Search)。
2 Lucene实现全文检索的流程

全文检索的流程分为两大部分:索引流程、搜索流程。
- 索引流程:即采集数据à构建文档对象à分析文档(分词)à创建索引。
- 搜索流程:即用户通过搜索界面à创建查询à执行搜索,搜索器从索引库搜索à渲染搜索结果。
3 入门程序
3.1.1 第一步:添加jar包
入门程序只需要添加以下jar包:
- mysql5.1驱动包:mysql-connector-java-5.1.7-bin.jar
- 核心包:lucene-core-4.10.3.jar
- 分析器通用包:lucene-analyzers-common-4.10.3.jar
- 查询解析器包:lucene-queryparser-4.10.3.jar
3.1.2 PO,DAO以及测试代码



1 package cn.xjy.po ; 2 3 public class Book { 4 5 // 图书ID 6 private Integer id ; 7 // 图书名称 8 private String name ; 9 // 图书价格 10 private Float price ; 11 // 图书图片 12 private String pic ; 13 // 图书描述 14 private String description ; 15 16 public Book() {} 17 18 public Book(Integer id, String name, Float price, String pic, String description) { 19 super() ; 20 this.id = id ; 21 this.name = name ; 22 this.price = price ; 23 this.pic = pic ; 24 this.description = description ; 25 } 26 27 public Integer getId() { 28 return id ; 29 } 30 31 public void setId(Integer id) { 32 this.id = id ; 33 } 34 35 public String getName() { 36 return name ; 37 } 38 39 public void setName(String name) { 40 this.name = name ; 41 } 42 43 public Float getPrice() { 44 return price ; 45 } 46 47 public void setPrice(Float price) { 48 this.price = price ; 49 } 50 51 public String getPic() { 52 return pic ; 53 } 54 55 public void setPic(String pic) { 56 this.pic = pic ; 57 } 58 59 public String getDescription() { 60 return description ; 61 } 62 63 public void setDescription(String description) { 64 this.description = description ; 65 } 66 67 @Override 68 public String toString() { 69 return "Book [id=" + id + ", name=" + name + ", price=" + price + ", pic=" + pic 70 + ", description=" + description + "]" ; 71 } 72 73 }
1 package cn.xjy.dao ; 2 3 import java.sql.Connection ; 4 import java.sql.DriverManager ; 5 import java.sql.PreparedStatement ; 6 import java.sql.ResultSet ; 7 import java.util.ArrayList ; 8 import java.util.List ; 9 import cn.xjy.po.Book ; 10 11 public class BookDaoImpl implements BookDao { 12 13 @Override 14 public List<Book> getBooks() { 15 List<Book> books = new ArrayList<Book>() ; 16 17 try { 18 Class.forName("com.mysql.jdbc.Driver") ; 19 Connection con = DriverManager.getConnection("jdbc:mysql:///luncene", "root", "root") ; 20 PreparedStatement statement = con.prepareStatement("select * from book") ; 21 ResultSet resultSet = statement.executeQuery() ; 22 while (resultSet.next()) { 23 Book book = new Book(resultSet.getInt("id"), resultSet.getString("name"), 24 resultSet.getFloat("price"), resultSet.getString("pic"), 25 resultSet.getString("description")) ; 26 books.add(book) ; 27 } 28 } catch (Exception e) { 29 e.printStackTrace() ; 30 } 31 32 return books ; 33 } 34 35 }
1 package cn.xjy.lucene ; 2 3 import java.io.File ; 4 import java.util.ArrayList ; 5 import java.util.List ; 6 import org.apache.lucene.analysis.Analyzer ; 7 import org.apache.lucene.analysis.standard.StandardAnalyzer ; 8 import org.apache.lucene.document.Document ; 9 import org.apache.lucene.document.Field ; 10 import org.apache.lucene.document.Field.Store ; 11 import org.apache.lucene.document.FloatField ; 12 import org.apache.lucene.document.IntField ; 13 import org.apache.lucene.document.TextField ; 14 import org.apache.lucene.index.DirectoryReader ; 15 import org.apache.lucene.index.IndexReader ; 16 import org.apache.lucene.index.IndexWriter ; 17 import org.apache.lucene.index.IndexWriterConfig ; 18 import org.apache.lucene.index.Term ; 19 import org.apache.lucene.queryparser.classic.QueryParser ; 20 import org.apache.lucene.search.BooleanClause.Occur ; 21 import org.apache.lucene.search.BooleanQuery ; 22 import org.apache.lucene.search.IndexSearcher ; 23 import org.apache.lucene.search.NumericRangeQuery ; 24 import org.apache.lucene.search.Query ; 25 import org.apache.lucene.search.ScoreDoc ; 26 import org.apache.lucene.search.TermQuery ; 27 import org.apache.lucene.search.TopDocs ; 28 import org.apache.lucene.store.Directory ; 29 import org.apache.lucene.store.FSDirectory ; 30 import org.apache.lucene.util.Version ; 31 import org.wltea.analyzer.lucene.IKAnalyzer ; 32 import cn.xjy.dao.BookDao ; 33 import cn.xjy.dao.BookDaoImpl ; 34 import cn.xjy.po.Book ; 35 36 public class TestLucene { 37 38 /** 39 * 创建索引库 40 * @throws Exception 41 */ 42 public void lucene() throws Exception { 43 BookDao bookDao = new BookDaoImpl() ; 44 List<Book> books = bookDao.getBooks() ; 45 // 采集数据的目的是为了索引,在索引前需要将原始内容创建成文档(Document), 46 // 文档(Document)中包括一个一个的域(Field)。 47 48 // 1.创建document集合对象 49 List<Document> documents = new ArrayList<Document>() ; 50 51 // 2.循环遍历数据集,根据需求创建不同的filed,添加到对应的document对象中 52 Document document = null ; 53 for (Book book : books) { 54 document = new Document() ; 55 Field id = new IntField("id", book.getId(), Store.YES) ; 56 Field name = new TextField("name", book.getName(), Store.YES) ; 57 58 if (book.getId()==4) 59 name.setBoost(100f) ;// 设置权重.值越大搜索越靠前 60 Field price = new FloatField("price", book.getPrice(), Store.YES) ; 61 Field pic = new TextField("pic", book.getPic(), Store.YES) ; 62 Field description = new TextField("description", book.getDescription(), Store.NO) ; 63 64 document.add(id) ; 65 document.add(name) ; 66 document.add(price) ; 67 document.add(pic) ; 68 document.add(description) ; 69 documents.add(document) ; 70 } 71 72 // 3.把每个document对象添加到document集合中 73 74 // 4.分析文档,对文档中的内容记性分词,实例化分析器对象,首先创建索引目录 75 Analyzer analyzer = new StandardAnalyzer() ; 76 Directory directory = FSDirectory.open(new File("src/index")) ; 77 78 // 5.创建indexWriterConfig对象 79 IndexWriterConfig config = new IndexWriterConfig(Version.LATEST, analyzer) ; 80 81 // 6.创建indexWriter对象 82 IndexWriter writer = new IndexWriter(directory, config) ; 83 84 // 7.通过indexWriter对象,添加文档对象,写入索引库的过程 85 for (Document doc : documents) { 86 writer.addDocument(doc) ; 87 } 88 89 // 8.关闭indexWriter流 90 writer.close() ; 91 92 } 93 94 /** 95 * 创建索引库,可解析中文 96 * @throws Exception 97 */ 98 public void luceneCN() throws Exception { 99 BookDao bookDao = new BookDaoImpl() ; 100 List<Book> books = bookDao.getBooks() ; 101 // 采集数据的目的是为了索引,在索引前需要将原始内容创建成文档(Document), 102 // 文档(Document)中包括一个一个的域(Field)。 103 104 // 1.创建document集合对象 105 List<Document> documents = new ArrayList<Document>() ; 106 107 // 2.循环遍历数据集,根据需求创建不同的filed,添加到对应的document对象中 108 Document document = null ; 109 for (Book book : books) { 110 document = new Document() ; 111 Field id = new IntField("id", book.getId(), Store.YES) ; 112 Field name = new TextField("name", book.getName(), Store.YES) ; 113 114 if (book.getId()==4) 115 name.setBoost(100f) ;// 设置权重.值越大搜索越靠前 116 Field price = new FloatField("price", book.getPrice(), Store.YES) ; 117 Field pic = new TextField("pic", book.getPic(), Store.YES) ; 118 Field description = new TextField("description", book.getDescription(), Store.YES) ; 119 120 document.add(id) ; 121 document.add(name) ; 122 document.add(price) ; 123 document.add(pic) ; 124 document.add(description) ; 125 documents.add(document) ; 126 } 127 128 // 3.把每个document对象添加到document集合中 129 130 // 4.分析文档,对文档中的内容记性分词,实例化分析器对象,首先创建索引目录 131 Analyzer analyzer = new IKAnalyzer(); 132 Directory directory = FSDirectory.open(new File("src/index")) ; 133 134 // 5.创建indexWriterConfig对象 135 IndexWriterConfig config = new IndexWriterConfig(Version.LATEST, analyzer) ; 136 137 // 6.创建indexWriter对象 138 IndexWriter writer = new IndexWriter(directory, config) ; 139 140 // 7.通过indexWriter对象,添加文档对象,写入索引库的过程 141 for (Document doc : documents) { 142 writer.addDocument(doc) ; 143 } 144 145 // 8.关闭indexWriter流 146 writer.close() ; 147 148 } 149 150 /** 151 * 删除指定的索引 152 * @throws Exception 153 */ 154 public void deleteIndex() throws Exception { 155 // 1.指定索引库的位置 156 Directory directory = FSDirectory.open(new File("src/index")) ; 157 158 // 2.创建indexWriterConfig 159 IndexWriterConfig indexWriterConfig = new IndexWriterConfig(Version.LATEST, null) ; 160 161 // 3.创建indexWriter 162 IndexWriter indexWriter = new IndexWriter(directory, indexWriterConfig) ; 163 164 // 4.删除指定的索引(new Term()) 165 // indexWriter.deleteDocuments(new Term("id", "1"));//参数是Term() 166 // indexWriter.deleteDocuments(new QueryParser("id", new 167 // StandardAnalyzer()).parse("id:1"));//参数为query 168 indexWriter.deleteAll() ;// 删除所有 169 // 5.关闭流 170 indexWriter.close() ; 171 172 System.out.println("删除成功") ; 173 174 // 在查询一遍验证是否删除 175 searchIndex() ; 176 } 177 178 /** 179 * 更新索引, 180 * 最好的做法是先查出要修改的索引进行更新 181 * @throws Exception 182 */ 183 public void updateIndex() throws Exception { 184 // 1.指定索引库 185 Directory directory = FSDirectory.open(new File("src/index")) ; 186 187 // 2.定义indexReader 188 IndexReader indexReader = DirectoryReader.open(directory) ; 189 190 // 3.定义indexSearcher 191 IndexSearcher indexSearcher = new IndexSearcher(indexReader) ; 192 193 Query query = new QueryParser("id", new StandardAnalyzer()).parse("id:1") ; 194 // 查询索引库 195 TopDocs topDocs = indexSearcher.search(query, 1) ; 196 197 // 获取查询到的对象 198 ScoreDoc scoreDoc = topDocs.scoreDocs[0] ; 199 200 // 获取document对象 201 Document document = indexSearcher.doc(scoreDoc.doc) ; 202 203 // 更新内容 204 document.removeField("name") ; 205 document.add(new TextField("name", "这是测试更新的内容", Store.YES)) ; 206 207 // 初始化indexWriterConfig和indexWriter对象 208 IndexWriterConfig IndexWriterConfig = new IndexWriterConfig(Version.LATEST, 209 new StandardAnalyzer()) ; 210 IndexWriter indexWriter = new IndexWriter(directory, IndexWriterConfig) ; 211 212 // 开始更新,这个方法第一个参数如果设置为null,则不会删除原来的数据,而且添加了一条更新后的新数据 213 // 为了保证数据的严谨性,必须删除为更新之前的数据,添加上更新后的数据就哦了 214 indexWriter.updateDocument(new Term("id", "1"), document) ; 215 indexWriter.close() ; 216 indexReader.close() ; 217 218 System.out.println("更新成功") ; 219 } 220 221 /** 222 * 可多条件连接QueryParser会将用户输入的查询表达式解析成Query对象实例。 223 * 搜索 Query query = queryParser.parse("*:*") ; 224 * @throws Exception 225 */ 226 public void searchIndex() throws Exception { 227 // 创建分析器 228 Analyzer analyzer = new StandardAnalyzer() ; 229 230 // 查询条件 231 QueryParser queryParser = new QueryParser("description", analyzer) ; 232 Query query = queryParser.parse("description:个") ; 233 234 // 指定搜索目录 235 Directory directory = FSDirectory.open(new File("src/index")) ; 236 237 // 创建indexReader 238 IndexReader indexReader = DirectoryReader.open(directory) ; 239 240 // 创建indexSearch对象 241 IndexSearcher indexSearcher = new IndexSearcher(indexReader) ; 242 243 // 查询索引库 244 TopDocs topDocs = indexSearcher.search(query, 10) ; 245 246 // 获取前十条记录 247 ScoreDoc [] scoreDocs = topDocs.scoreDocs ; 248 249 System.out.println("文档个数:" + topDocs.totalHits) ; 250 251 for (ScoreDoc scoreDoc : scoreDocs) { 252 Document doc = indexSearcher.doc(scoreDoc.doc) ; 253 System.out.println(doc) ; 254 } 255 } 256 257 /** 258 * 这种不可多条件查询 259 * 搜索 Query query = new TermQuery(new Term("id", "1")); 260 * @throws Exception 261 */ 262 public void searchIndex2() throws Exception { 263 // 创建分析器 264 Analyzer analyzer = new StandardAnalyzer() ; 265 266 // 查询条件 267 Query query = new TermQuery(new Term("description", "徐景洋驻马店")) ; 268 269 // 指定搜索目录 270 Directory directory = FSDirectory.open(new File("src/index")) ; 271 272 // 创建indexReader 273 IndexReader indexReader = DirectoryReader.open(directory) ; 274 275 // 创建indexSearch对象 276 IndexSearcher indexSearcher = new IndexSearcher(indexReader) ; 277 278 // 查询索引库 279 TopDocs topDocs = indexSearcher.search(query, 10) ; 280 281 // 获取前十条记录 282 ScoreDoc [] scoreDocs = topDocs.scoreDocs ; 283 284 System.out.println("文档个数:" + topDocs.totalHits) ; 285 286 for (ScoreDoc scoreDoc : scoreDocs) { 287 Document doc = indexSearcher.doc(scoreDoc.doc) ; 288 System.out.println(do以上是关于全文检索技术---Lucene的主要内容,如果未能解决你的问题,请参考以下文章