基于GCC的openMP学习与测试
Posted bamtercelboo
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于GCC的openMP学习与测试相关的知识,希望对你有一定的参考价值。
(一)、openMP简述
- Open Multiprocessing (OpenMP) 框架是一种功能极为强大的规范,可以帮助您利用 C、C++ 和 Fortran 应用程序中的多个核心带来的好处,是基于共享内存模式的一种并行编程模型, 使用十分方便, 只需要串行程序中加入OpenMP预处理指令, 就可以实现串行程序的并行化。
(二)、openMP简单使用
1、简单的HelloWord程序
-
 View Code
View Code#include <iostream> int main() { #pragma omp parallel { std::cout << "Hello World!\\n"; } }

#pragma omp parallel仅在您指定了-fopenmp编译器选项后才会发挥作用。在编译期间,GCC 会根据硬件和操作系统配置在运行时生成代码,创建尽可能多的线程。- 只运行 g++ hello.cpp,只会打印出一行Hello world!
- 运行g++ hello.cpp -fopenmp,打印出12个Hello World!(12个是因为我用的是linux服务器默认分配的)
- 运行结果
-
View Code
user@NLP ~/vsworksapce $ g++ hello.cpp user@NLP ~/vsworksapce $ ./a.out Hello World! user@NLP ~/vsworksapce $ g++ hello.cpp -fopenmp user@NLP ~/vsworksapce $ ./a.out Hello World! Hello World! Hello World! Hello World! Hello World! Hello World! Hello World! Hello World! Hello World! Hello World! Hello World! Hello World!
2、如何自定义线程数量
- num_threads的设置
- omp_set_num_threads()库函数的设置
-
View Code
#include <omp.h> #include <iostream> int main() { int number_threads = 1; omp_set_num_threads(number_threads) //方法二 #pragma omp parallel num_threads(number_threads) //方式一 { std::cout << "Hello World!\\n"; } }
- OMP_NUM_THREADS环境变量的设置 (Linux下:export OMP_NUM_THREADS=4)
- 编译器默认实现(一般而言,不指定具体线程数量的情况下,默认实现的总线程数等于处理器的核心数)
3、parallel sections 编译指示
pragma omp sections和pragma omp parallel之间的代码将由所有线程并行运行。pragma omp sections之后的代码块通过pragma omp section进一步被分为各个子区段。每个pragma omp section块将由一个单独的线程执行。但是,区段块中的各个指令始终按顺序运行。
-
View Code
#include <iostream> int main() { #pragma omp parallel { std::cout << "parallel \\n"; #pragma omp sections { #pragma omp section { std::cout << "section1 \\n"; } #pragma omp section { std::cout << "sectio2 \\n"; std::cout << "after sectio2 \\n"; } #pragma omp section { std::cout << "sectio3 \\n"; std::cout << "after sectio3 \\n"; } } } } //运行结果 user@NLP ~/vsworksapce $ g++ openMP12.cpp -fopenmp user@NLP ~/vsworksapce $ ./a.out parallel section1 sectio2 after sectio2 sectio3 after sectio3 parallel parallel parallel parallel parallel parallel parallel parallel parallel parallel parallel
4、还有一些omp_get_wtime、for、while循环中的并行处理、OpenMP critical section、OpenMP实现锁和互斥、以及firstprivate和lastprivate指令等一些 openMP的使用可以参考(https://www.ibm.com/developerworks/cn/aix/library/au-aix-openmp-framework/)
(三)、openMP简单测试
1、简单的测试--不限制线程数量
-
View Code
#include <omp.h> #include <time.h> #include <iostream> #include <ctime> int main() { time_t start,end1; time( &start ); int a = 0; #pragma omp parallel for for (int i = 0; i < 100; ++i) { for (int j = 0; j < 1000000000; j++); //std::cout<< a++ << std::endl; } time( &end1 ); double omp_end = omp_get_wtime( ); std::cout<<std::endl; std::cout<<"Time_used " <<((end1 - start))<<"s"<<std::endl; std::cout<<"omp_time: "<<((omp_end - omp_start))<<std::endl; return 0; }
- 从下面的图表可以看出使用openMP的运行时间明显少于不使用openMP。
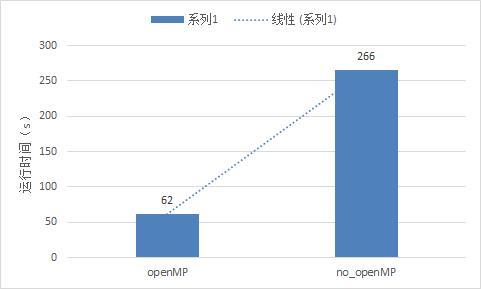
2、简单的测试--限制线程数量
-
View Code
#include <omp.h> #include <time.h> #include <iostream> #include <ctime> int main() { time_t start,end1; time( &start ); int a = 0; double omp_start = omp_get_wtime( ); #pragma omp parallel for num_threads(8) for (int i = 0; i < 100; ++i) { for (int j = 0; j < 1000000000; j++); } time( &end1 ); double omp_end = omp_get_wtime( ); std::cout<<std::endl; std::cout<<"Time_used " <<((end1 - start))<<"s"<<std::endl; std::cout<<"omp_time: "<<((omp_end - omp_start))<<std::endl; return 0; }
- 从下面的图表能够看出,线程数量对程序运行时间也是有一定的影响的,影响的大小和程序运算数据量有关。
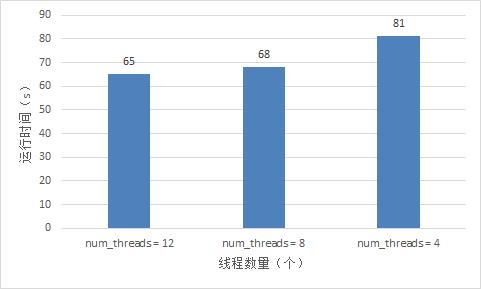
3、简单测试--提升数据量,限制线程数量
-
View Code
#include <omp.h> #include <time.h> #include <iostream> #include <ctime> int main() { time_t start,end1; time( &start ); int a = 0; double omp_start = omp_get_wtime( ); #pragma omp parallel for num_threads(12) for (int i = 0; i < 1000; ++i) { for (int j = 0; j < 1000000000; j++); } time( &end1 ); double omp_end = omp_get_wtime( ); std::cout<<std::endl; std::cout<<"Time_used " <<((end1 - start))<<"s"<<std::endl; std::cout<<"omp_time: "<<((omp_end - omp_start))<<std::endl; return 0; }
- 线程数量对程序的运行时间是有影响的,如果继续提升数据运算量,openMP的实验效果会更加明显。
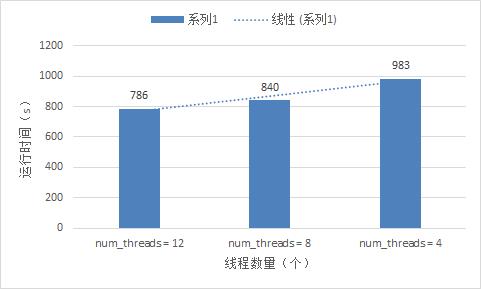
4、简单测试--降低数据量,限制线程数量
-
View Code
#include <omp.h> #include <time.h> #include <iostream> #include <ctime> int main() { time_t start,end1; time( &start ); int a = 0; double omp_start = omp_get_wtime( ); #pragma omp parallel for for (int i = 0; i < 1000; ++i) { for (int j = 0; j < 10000; j++); } time( &end1 ); double omp_end = omp_get_wtime( ); std::cout<<std::endl; std::cout<<"Time_used " <<((end1 - start))<<"s"<<std::endl; std::cout<<"omp_time: "<<((omp_end - omp_start))<<std::endl; return 0; }
- 当数据量很小的时候,使用或者不使用openMP对于程序的运行时间影响不大。
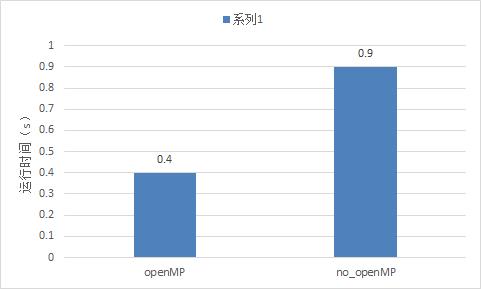
(四)、openMP学习参考
- 通过 GCC 学习 OpenMP 框架:https://www.ibm.com/developerworks/cn/aix/library/au-aix-openmp-framework/
-
Guide into OpenMP : http://bisqwit.iki.fi/story/howto/openmp/
以上是关于基于GCC的openMP学习与测试的主要内容,如果未能解决你的问题,请参考以下文章