二分图之匈牙利算法
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了二分图之匈牙利算法相关的知识,希望对你有一定的参考价值。
(⊙o⊙)…——————————————————————————————————————————————————————————————————前面的概念大多使用网上粘的(ORZ)
one、基本概念
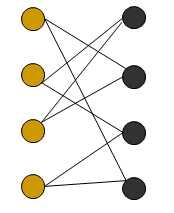
1. 二分图
二分图是图论中的一种特殊模型。若能将无向图G=(V,E)的顶点V划分为两个交集为空的顶点集,并且任意边的两个端点都分属于两个集合,则称图G为一个为二分图。
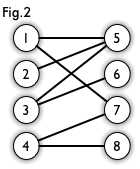
2.匹配
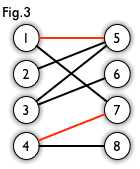
一个匹配即一个包含若干条边的集合,且其中任意两条边没有公共端点。如下图,图3的红边即为图2的一个匹配。
有关匹配
①最大匹配
在G的一个子图M中,M的边集中的任意两条边都不依附于同一个顶点,则称M是一个匹配。选择这样的边数最大的子集称为图的最大匹配问题,最大匹配的边数称为最大匹配数.如果一个匹配中,图中的每个顶点都和图中某条边相关联,则称此匹配为完全匹配,也称作完备匹配。如果在左右两边加上源汇点后,图G等价于一个网络流,最大匹配问题可以转为最大流的问题。解决此问的匈牙利算法的本质就是寻找最大流的增广路径。上图中的最大匹配如下图红边所示:
②最优匹配
最优匹配又称为带权最大匹配,是指在带有权值边的二分图中,求一个匹配使得匹配边上的权值和最大。一般X和Y集合顶点个数相同,最优匹配也是一个完备匹配,即每个顶点都被匹配。如果个数不相等,可以通过补点加0边实现转化。一般使用KM算法解决该问题。
③最小覆盖
二分图的最小覆盖分为最小顶点覆盖和最小路径覆盖:
①最小顶点覆盖是指最少的顶点数使得二分图G中的每条边都至少与其中一个点相关联,二分图的最小顶点覆盖数=二分图的最大匹配数;
②最小路径覆盖也称为最小边覆盖,是指用尽量少的不相交简单路径覆盖二分图中的所有顶点。二分图的最小路径覆盖数=|V|-二分图的最大匹配数;
④最大独立集
最大独立集是指寻找一个点集,使得其中任意两点在图中无对应边。对于一般图来说,最大独立集是一个NP完全问题,对于二分图来说最大独立集=|V|-二分图的最大匹配数。如下图中黑色点即为一个最大独立集:
基本概念—匈牙利算法
交替路:从一个未匹配点出发,依次经过非匹配边、匹配边、非匹配边...形成的路径叫交替路。*
增广路:从一个未匹配点出发,走交替路,如果途径另一个未匹配点(出发的点不算),则这条交替路称为增广路(agumenting path)。
3.最大匹配与最小点覆盖
最小点覆盖:假如选了一个点就相当于覆盖了以它为端点的所有边,你需要选择最少的点来覆盖所有的边
最小割定理是一个二分图中很重要的定理:一个二分图中的最大匹配数等于这个图中的最小点覆盖数。
最小点集覆盖==最大匹配。在这里解释一下原因,首先,最小点集覆盖一定>=最大匹配,因为假设最大匹配为n,那么我们就得到了n条互不相邻的边,光覆盖这些边就要用到n个点。现在我们来思考为什么最小点击覆盖一定<=最大匹配。任何一种n个点的最小点击覆盖,一定可以转化成一个n的最大匹配。因为最小点集覆盖中的每个点都能找到至少一条只有一个端点在点集中的边(如果找不到则说明该点所有的边的另外一个端点都被覆盖,所以该点则没必要被覆盖,和它在最小点集覆盖中相矛盾),只要每个端点都选择一个这样的边,就必然能转化为一个匹配数与点集覆盖的点数相等的匹配方案。所以最大匹配至少为最小点集覆盖数,即最小点击覆盖一定<=最大匹配。综上,二者相等。
4.无聊的讲解(这来自学长博客)
由增广路的性质,增广路中的匹配边总是比未匹配边多一条,所以如果我们放弃一条增广路中的匹配边,选取未匹配边作为匹配边,则匹配的数量就会增加。匈牙利算法就是在不断寻找增广路,如果找不到增广路,就说明达到了最大匹配。
先给一个例子
1、起始没有匹配
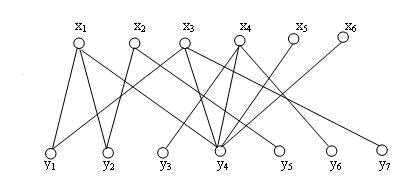
2、选中第一个x点找第一跟连线 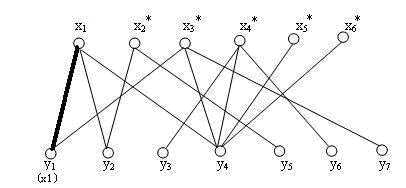
3、选中第二个点找第二跟连线 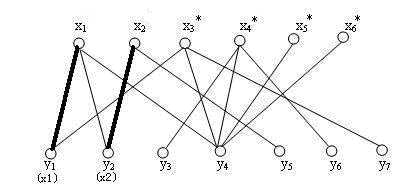
4、发现x3的第一条边x3y1已经被人占了,找出x3出发的的交错路径x3-y1-x1-y4,把交错路中已在匹配上的边x1y1从匹配中去掉,剩余的边x3y1 x1y4加到匹配中去 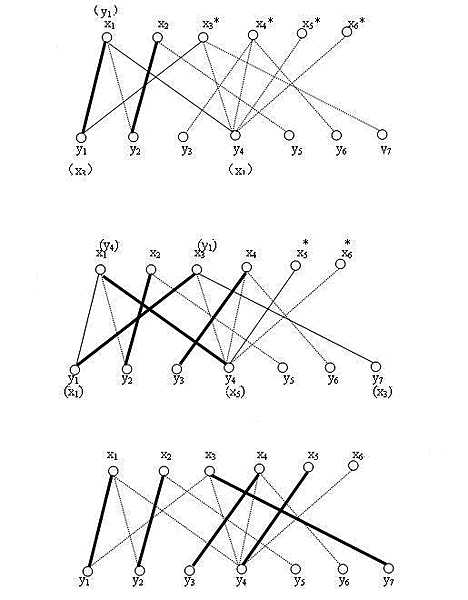
5、同理加入x4,x5。
匈牙利算法可以深度有限或者广度优先,刚才的示例是深度优先,即x3找y1,y1已经有匹配,则找交错路。若是广度优先,应为:x3找y1,y1有匹配,x3找y2。
two、趣味讲解
上面的东西有没有看懵??好吧,我们来看一个生动有趣的讲解
首先我们有n个王子和n个女孩。现在你是皇上,你要给他们指婚,你当然需要尽可能的把这些女孩都与王子匹配上。我们已知这些王子都有自己心仪的女孩,女孩也都有自己梦中的白马王子,(当然,身为一位明君,你是不会硬生生的将这些有情人拆开的。。)

本着救人一命,胜造七级浮屠的原则,你想要尽可能地撮合更多的情侣,匈牙利算法的工作模式会教你这样做:
===============================================================================
一: 先试着给1号王子找妹子,发现第一个和他相连的1号女生还名花无主,got it,连上一条红线

===============================================================================
二:接着给2号男生找妹子,发现第一个和他相连的3号女生名花无主,got it

===============================================================================
三:接下来是3号男生,很遗憾1号女生已经有主了,怎么办呢?
我们试着给之前1号女生匹配的男生(也就是1号男生)另外分配一个妹子。
(黄色表示这条边被临时拆掉)

与1号男生相连的第二个女生是2号女生,但是2号女生没主,来牵上红线。

来我们再来匹配3号王子(这是他正好与1号女孩牵上红绳)

来再来4号王子。这么办,这位帅帅的王子的心仪女孩也被牵走了。。。怎么办呢?我们再试着给2号女生的原配( )重新找个妹子(注意这个步骤和上面是一样的,这是一个递归的过程)
)重新找个妹子(注意这个步骤和上面是一样的,这是一个递归的过程)
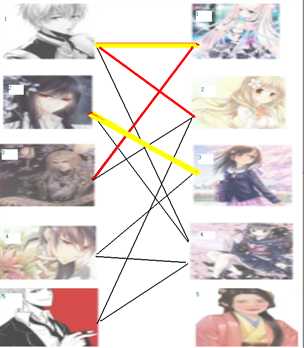
此时发现2号男生还能找到4号女生,那么之前的问题迎刃而解了,回溯回去

来,给4号王子连上红绳。

2号王子可以找4号妹子~~~ 1号男生可以找2号妹子了~~~ 3号男生可以找1号妹子 4号王子可以找3号妹子了。。
所以第三步最后的结果就是:

===============================================================================
四: 接下来是5号王子,很遗憾,按照第三步的节奏我们没法给5号王子腾出来一个公主,我们实在是无能为力了…(那就公猪吧,凑活凑活吧。。。。)
===============================================================================
其原则大概是:有机会上,没机会创造机会也要上
three、代码呈现
#include<cstdio> #include<cstdlib> #include<cstring> #include<iostream> #include<algorithm> #define N 1010 using namespace std; bool vis[N]; int n1,n2,m,x,y,ans,girl[N],map[N][N]; int read() { int x=0,f=1; char ch=getchar(); while(ch<‘0‘||ch>‘9‘) {if(ch==‘-‘) f=-1; ch=getchar();} while(ch<=‘9‘&&ch>=‘0‘){x=x*10+ch-‘0‘;ch=getchar();} return x*f; } int find(int x) { for(int i=1;i<=n2;i++) if(map[x][i]&&!vis[i]) { vis[i]=true; if(!girl[i]||find(girl[i])) { girl[i]=x; return 1; } } return 0; } int main() { n1=read(),n2=read(),m=read(); for(int i=1;i<=m;i++) x=read(),y=read(),map[x][y]=1; for(int i=1;i<=n1;i++) { memset(vis,0,sizeof(vis)); if(find(i)) ans++; } printf("%d",ans); return 0; }
以上是关于二分图之匈牙利算法的主要内容,如果未能解决你的问题,请参考以下文章