python正则表达式管道符的使用?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python正则表达式管道符的使用?相关的知识,希望对你有一定的参考价值。
如果管道符的作用是表示用第一个正则表达式\d8去匹配字符串或者用第二个正则表达式\d6去匹配字符串。二者无论谁匹配到都会返回一个值,为什么返回的是‘313233’,不是‘12345678’。就算是按照第二个正则表达式去匹配,为什么返回的不能是‘132334’或者‘123456’?他这个处理逻辑是怎么样的呢?
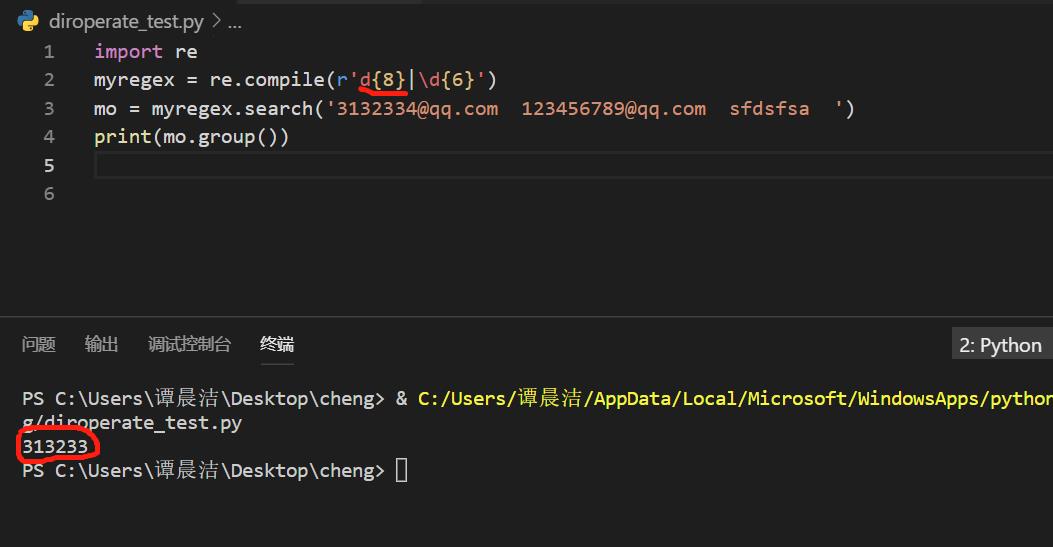
1、你要测试是否匹配多个,应该用findall,而不是search,search只找第一个匹配的。
2、\d8 你写成了d8
3、6是精确6位,6,才会匹配到8位的12345678
/m 修饰符的 perl 正则表达式意外行为
【中文标题】/m 修饰符的 perl 正则表达式意外行为【英文标题】:perl regex unexpected behaviour of /m modifier 【发布时间】:2021-06-26 09:49:39 【问题描述】:我想用这个正则表达式从多行字符串中删除前导和尾随空格:
s/^\s*|\s*$//mg
在这个例子中似乎工作得差不多了:
perl -e '$_=" a \n \n b\n"; s/^\s*|\s*$//mg; print "$_\n";'
给出结果:
a
b
(没想到中间有空格的双\n变成了单\n)
但请注意:
perl -e '$_=" a \n\n b\n"; s/^\s*|\s*$//mg; print "$_\n";'
结果:
ab
现在两个 \n 都消失了,多行字符串现在是单行,这不是我想要的。 如果这不是错误,我该如何避免这种行为?
【问题讨论】:
\s 匹配包括换行符在内的空格,请改用\h
你能为两个给定的样本添加完整的预期输出吗?您想为字符串中的每一行删除前导/尾随空格还是只为整个字符串删除一次?如果您只想删除外部空格,请使用 s/\A\s*|\s*\z//g
如果您想深入了解细节,可以尝试添加-Mre=debug 以获取有关正则表达式的一些调试信息,然后比较两个不同字符串的交互方式。
This 很有趣。
【参考方案1】:
使用-Mre=debug 模块并深入了解细节,我找到了我认为的答案。我删除了前导空格,因为它与问题无关。我删除了除相关部分之外的所有内容。两个正则表达式首先使用 RHS (5:BRANCH) 匹配第二个换行符前面的空格/换行符,然后将指针设置在第二个换行符前面:
案例一:字符串a \n \n b\n
Matching REx "^\s+|\s+$" against "%n b%n"
4 <a %n > <%n b%n> | 0| 1:BRANCH(5)
4 <a %n > <%n b%n> | 1| 2:MBOL(3)
| 1| failed...
4 <a %n > <%n b%n> | 0| 5:BRANCH(9)
4 <a %n > <%n b%n> | 1| 6:PLUS(8)
| 1| POSIXD[\s] can match 2 times out of 2147483647...
6 <a %n %n > <b%n> | 2| 8:MEOL(9)
| 2| failed...
5 <a %n %n> < b%n> | 2| 8:MEOL(9)
| 2| failed...
| 1| failed...
| 0| BRANCH failed...
5 <a %n %n> < b%n> | 0| 1:BRANCH(5) <-- HERE!
5 <a %n %n> < b%n> | 1| 2:MBOL(3)
5 <a %n %n> < b%n> | 1| 3:PLUS(9)
| 1| POSIXD[\s] can match 1 times out of 2147483647...
6 <a %n %n > <b%n> | 2| 9:END(0)
Match successful!
在这种情况下,LHS (1:BRANCH) 首先失败,RHS (5:BRANCH) 失败,所以它向前移动 1 步,直到 LHS 匹配的换行符之后,并删除前面的内容它:一个空格。
在换行符和b 前面的空格匹配时,正则表达式中的“指针”向前移动到换行符前面。
%n> < b%n>
^ \s
案例2:字符串a \n\n b\n
Matching REx "^\s+|\s+$" against "%n b%n"
3 <a %n> <%n b%n> | 0| 1:BRANCH(5) <-- HERE!
3 <a %n> <%n b%n> | 1| 2:MBOL(3)
3 <a %n> <%n b%n> | 1| 3:PLUS(9)
| 1| POSIXD[\s] can match 2 times out of 2147483647...
5 <a %n%n > <b%n> | 2| 9:END(0)
Match successful!
在此字符串中,LHS (1:BRANCH) 中的零宽度断言^ 可以看到字符串左侧的换行符,并允许其匹配。在另一个字符串中,它有一个空格,因此无法匹配。所以 LHS 交流发电机匹配(称为 1:BRANCH),并删除它前面的内容,即换行符和空格 \n 。
不像案例1那样跳过第一次尝试并向前移动1步,它可以直接匹配左侧的换行符,右侧的空格\n :
%n> <%n b%n>
^ \s\s
TL;DR:在您的第二个字符串中,换行符可以匹配两个换行符之间的行首,因此将它们都删除。在第一个字符串中,它不能像那样匹配,因为那里有一个空格,而是向前移动一步,跳过换行符并使用该换行符来匹配字符串的开头。效果是换行符保留在字符串中。
如何避免这种行为?好吧,问题是你的正则表达式太松了。 \n 可以匹配正则表达式 ^、$ 和 \s 的所有组件,以各种组合方式进行。它也可以匹配在字符串的中间。如果您想安全并获得可预测的结果,请在逐行模式下使用正则表达式,不要将文件转换为单个字符串。那么你就不需要多行匹配了,所有的问题都迎刃而解了。
否则,请避免使用多行修饰符,只需照常删除前导和尾随空格,然后在字符串内部修剪多个带有空格的换行符,例如s/\n\s*\n/\n/g。
本质上,您试图同时做太多事情。让你的正则表达式更严格,并尝试一次做一件事情。
【讨论】:
【参考方案2】:\s 可以匹配换行符,这导致了换行符被移除的问题。
将\s 替换为以下之一:
[^\S\n]匹配既不是非空白字符也不是换行符的字符,即不是换行符的空白字符。
(?[ \s - \n ])目前处于试验阶段,需要use experimental qw( regex_sets );。
\h仅删除水平空白字符。虽然它不匹配换行符,但它也不匹配其他垂直空白字符。[1]
以下内容详细说明了您的模式是如何匹配的。
对于
␠ a ␠ ␊ ␠ ␊ ␠ b ␊
0 1 2 3 4 5 6 7 8 9
模式
/^\s*|\s*$/m
产生以下匹配:
-
位置 0,长度 1:
␠ 与 ^\s* 匹配。
位置 2,长度 3:␠␊␠ 与 \s*$ 匹配。 XXX
Pos 5, len 0: 与\s*$ 匹配的空字符串
位置 6,长度 1:␠ 与 ^\s* 匹配。
位置 8,长度 1:␊ 与 \s*$ 匹配。 XXX
Pos 9,len 0:与^\s* 匹配的空字符串。
对于
␠ a ␠ ␊ ␊ ␠ b ␊
0 1 2 3 4 5 6 7 8
模式
/^\s*|\s*$/m
产生以下匹配:
-
位置 0,长度 1:
␠ 与 ^\s* 匹配。
位置 2,长度 2:␠␊ 与 \s*$ 匹配。 XXX
位置 4,长度 2:␊␠ 与 ^\s* 匹配。 XXX
位置 7,长度 1:␊ 与 \s*$ 匹配。 XXX
Pos 8,len 0:与^\s* 匹配的空字符串。
脚注:
垂直空格:
U+000A 换行 U+000B 线制表 U+000C 换页 U+000D 回车 U+0085 下一行 U+2028 行分隔符 U+2029 段落分隔符【讨论】:
以上是关于python正则表达式管道符的使用?的主要内容,如果未能解决你的问题,请参考以下文章