7.哈希
Posted CoderBuff
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了7.哈希相关的知识,希望对你有一定的参考价值。
哈希(Hash)又称散列,它是一个很常见的算法。在Java的HashMap数据结构中主要就利用了哈希。哈希算法包括了哈希函数和哈希表两部分。我们数组的特性可以知道,可以通过下标快速(O(1))的定位元素,同理在哈希表中我们可以通过键(哈希值)快速的定位某个值,这个哈希值的计算就是通过哈希函数(hash(key) = address )计算得出的。通过哈希值即能定位元素[address] = value,原理同数组类似。
最好的哈希函数当然是每个key值都能计算出唯一的哈希值,但往往可能存在不同的key值的哈希值,这就造成了冲突,评判一个哈希函数是否设计良好的两个方面:
1.冲突少。
2.计算快。
下面给出几种常用的哈希函数,它们的背后都有一定的数学原理且经过大量实践,其数学原理不在这里探究。
BKDR哈希函数(h = 31 * h + c)
这个哈希函数被应用在Java的字符串哈希值计算。
//String#hashCode public int hashCode() { int h = hash; if (h == 0 && value.length > 0) { char val[] = value; for (int i = 0; i < value.length; i++) { h = 31 * h + val[i]; //BKDR 哈希函数,常数可以是131、1313、13131…… } hash = h; } return h; }
DJB2 哈希函数(h = h << 5 + h + c = h = 33 * h + c)
ElasticSearch就利用了DJB2哈希函数对要索引文档的指定key进行哈希。
SDBM哈希函数(h = h << 6 + h << 16 - h + c = 65599 * h + c)
在SDBM(一种简单的数据库引擎)中被应用。
以上只是列举了三种哈希函数,我们做下试验,看看它们的冲突情况是怎么样的。
Java
1 package com.algorithm.hash; 2 3 import java.util.HashMap; 4 import java.util.UUID; 5 6 /** 7 * 三种哈希函数冲突数比较 8 * Created by yulinfeng on 6/27/17. 9 */ 10 public class HashFunc { 11 12 public static void main(String[] args) { 13 int length = 1000000; //100万字符串 14 //利用HashMap来计算冲突数,HashMap的键值不能重复所以length - map.size()即为冲突数 15 HashMap<String, String> bkdrMap = new HashMap<String, String>(); 16 HashMap<String, String> djb2Map = new HashMap<String, String>(); 17 HashMap<String, String> sdbmMap = new HashMap<String, String>(); 18 getStr(length, bkdrMap, djb2Map, sdbmMap); 19 System.out.println("BKDR哈希函数100万字符串的冲突数:" + (length - bkdrMap.size())); 20 System.out.println("DJB2哈希函数100万字符串的冲突数:" + (length - djb2Map.size())); 21 System.out.println("SDBM哈希函数100万字符串的冲突数:" + (length - sdbmMap.size())); 22 } 23 24 /** 25 * 生成字符串,并计算冲突数 26 * @param length 27 * @param bkdrMap 28 * @param djb2Map 29 * @param sdbmMap 30 */ 31 private static void getStr(int length, HashMap<String, String> bkdrMap, HashMap<String, String> djb2Map, HashMap<String, String> sdbmMap) { 32 for (int i = 0; i < length; i++) { 33 System.out.println(i); 34 String str = UUID.randomUUID().toString(); 35 bkdrMap.put(String.valueOf(str.hashCode()), str); //Java的String.hashCode就是BKDR哈希函数, h = 31 * h + c 36 djb2Map.put(djb2(str), str); //DJB2哈希函数 37 sdbmMap.put(sdbm(str), str); //SDBM哈希函数 38 } 39 } 40 41 /** 42 * djb2哈希函数 43 * @param str 44 * @return 45 */ 46 private static String djb2(String str) { 47 int hash = 0; 48 for (int i = 0; i != str.length(); i++) { 49 hash = hash * 33 + str.charAt(i); //h = h << 5 + h + c = h = 33 * h + c 50 } 51 return String.valueOf(hash); 52 } 53 54 /** 55 * sdbm哈希函数 56 * @param str 57 * @return 58 */ 59 private static String sdbm(String str) { 60 int hash = 0; 61 for (int i = 0; i != str.length(); i++) { 62 hash = 65599 * hash + str.charAt(i); //h = h << 6 + h << 16 - h + c = 65599 * h + c 63 } 64 return String.valueOf(hash); 65 } 66 }
以下是10万、100万、200万的冲突数情况:
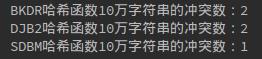
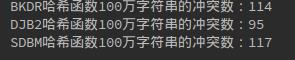
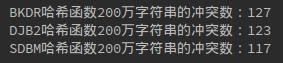
反复试验实际上三种哈希函数的冲突数差不多。
Python3
1 import uuid 2 3 def hash_test(length, bkdrDic, djb2Dic, sdbmDic): 4 for i in range(length): 5 string = str(uuid.uuid1()) #基于时间戳 6 bkdrDic[bkdr(string)] = string 7 djb2Dic[djb2(string)] = string 8 sdbmDic[sdbm(string)] = string 9 10 #BDKR哈希函数 11 def bkdr(string): 12 hash = 0 13 for i in range(len(string)): 14 hash = 31 * hash + ord(string[i]) # h = 31 * h + c 15 return hash 16 17 #DJB2哈希函数 18 def djb2(string): 19 hash = 0 20 for i in range(len(string)): 21 hash = 33 * hash + ord(string[i]) # h = h << 5 + h + c 22 return hash 23 24 #SDBM哈希函数 25 def sdbm(string): 26 hash = 0 27 for i in range(len(string)): 28 hash = 65599 * hash + ord(string[i]) # h = h << 6 + h << 16 - h + c 29 return hash 30 31 length = 100 32 bkdrDic = dict() #bkdrDic = {} 33 djb2Dic = dict() 34 sdbmDic = dict() 35 hash_test(length, bkdrDic, djb2Dic, sdbmDic) 36 print("BKDR哈希函数100万字符串的冲突数:%d"%(length - len(bkdrDic))) 37 print("DJB2哈希函数100万字符串的冲突数:%d"%(length - len(djb2Dic))) 38 print("SDBM哈希函数100万字符串的冲突数:%d"%(length - len(sdbmDic)))
哈希表是一种数据结构,它需要配合哈希函数使用,用于建立索引,便于快速查找——《算法笔记》。一般来讲它就是一个定长的存储空间,比如HashMap默认的哈希表就是定长为16的Entry数组。有了定长的存储空间过后,剩下的问题就是如何将值放入哪个位置,通常如果哈希值是m,长度为n,那么这个值就放到m mod n位置处。
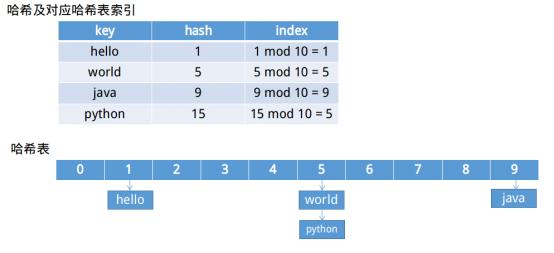
上图就是哈希和哈希表,以及产生冲突的解决办法(拉链法)。产生冲突后的解决办法有很多,有再哈希一次直到没有冲突,也有向上图一样采用拉链法利用链表将相同位置的元素串联。
想象一下,上面的例子哈希表的长度为10,产生了1次冲突,如果哈希表长度为20,那么就不会产生冲突查找更快但会浪费更多空间,如果哈希表长度为2,将会倒置3次冲突查找更慢但这样又会节省不少空间。所以哈希表的长度选择至关重要,但同时也是一个重要的难题。
补充:
哈希在很多方面有应用,例如在不同的值有不同的哈希值,但也可以将哈希算法设计精妙使得相似或相同的值有相似或相同的哈希值。也就是说如果两个对象完全不同,那么它们的哈希值也完全不同;如果两个对象完全相同,那么它们的哈希值也完全相同;两个对象越相似,那么它们的哈希值也就越相似。这实际上就是相似性问题,也就是说这个思想可以被推广应用到相似性的计算(例如Jaccard距离问题),最终应用到广告精准投放、商品推荐等。
另外,一致性哈希也可应用在负载均衡,如何保证每台服务器能均匀的分摊负载压力,一个好的哈希算法也可做到。
以上是关于7.哈希的主要内容,如果未能解决你的问题,请参考以下文章