浏览器
Posted ZRainna
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了浏览器相关的知识,希望对你有一定的参考价值。
主流浏览器
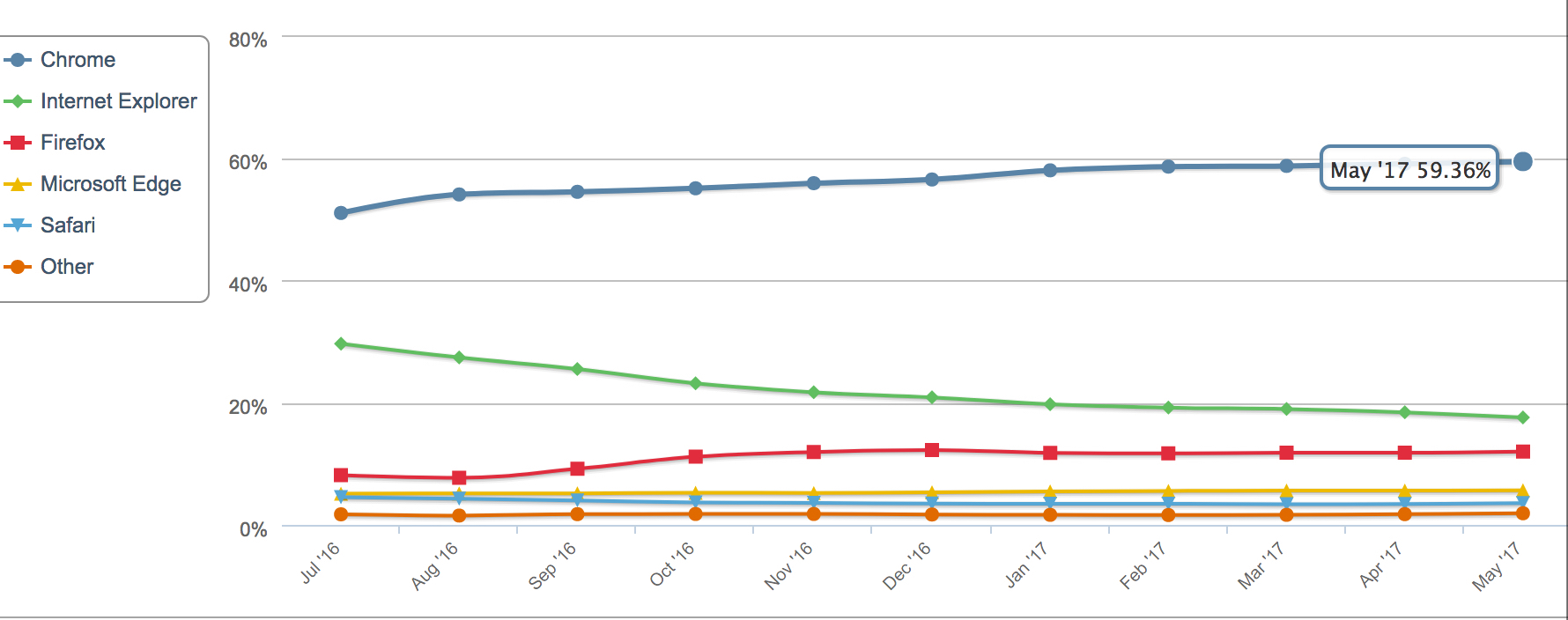
目前我们使用的主流浏览器包括:chrome, firefox, ie, safari, opera, uc等等。其中chrome浏览器所占的全球市场份额最高,其次是IE。下面截图数据来源于统计网站 https://www.netmarketshare.com/
浏览器的主要目的就是向服务器发送请求,获取并展示服务器上的资源,资源文件可以是html文档,也可以是pdf,jpg等其他类型的文件。
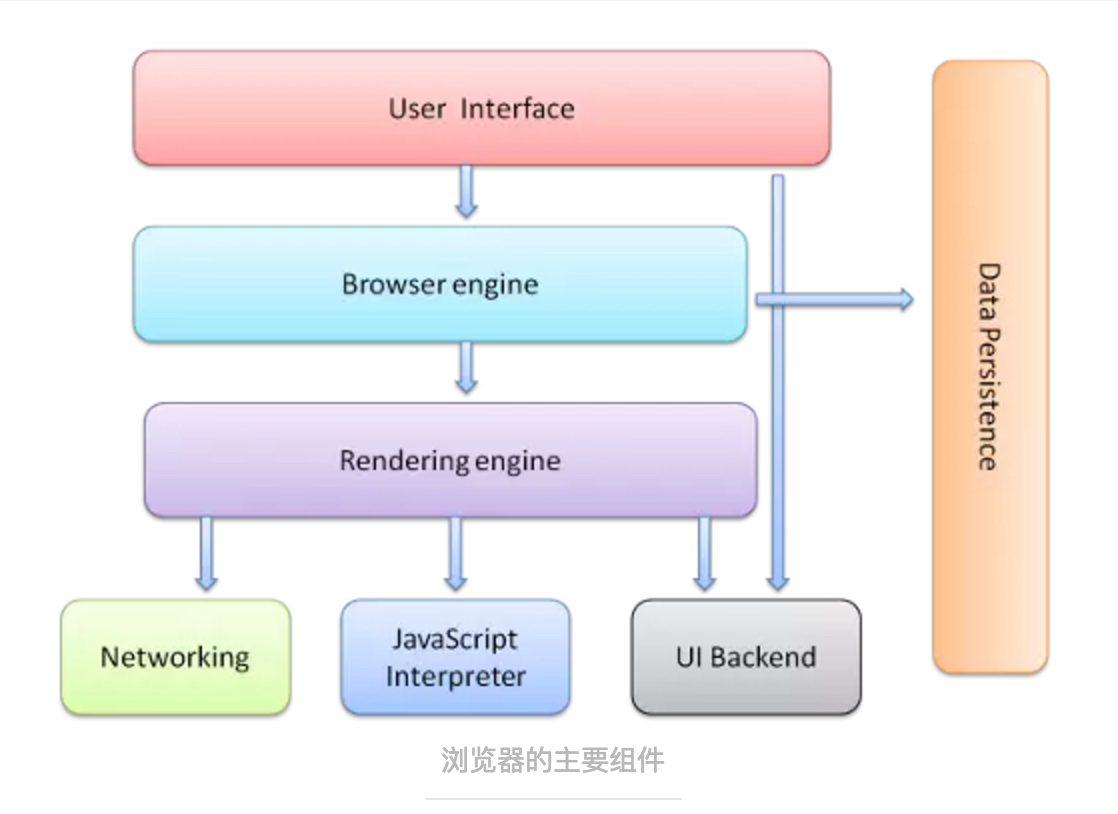
浏览器组件
用户操作界面:包括地址栏、前进/后退按钮、书签菜单等。
浏览器引擎:在用户界面和呈现引擎之间传输指令。
呈现引擎:展示所请求的内容,比如解析HTML文档和CSS内容,将页面展示给用户浏览。
网络:用于网络调用,比如发起HTTP请求。其底层实现跟平台无关。
用户界面后端:用于绘制基本的窗口小部件,比如弹窗等。其底层使用操作系统的用户界面方法。
JavaScript解释器:用于解释和执行JS代码。
数据存储:用于浏览器在硬盘上存储数据,比如cookie,local storage等。HTML5的网络数据库就是浏览器内的完整的轻量的数据库。
chrome浏览器的每个标签页分别对应一个呈现引擎实例,每个标签页都是一个独立的进程。
呈现引擎主流程
firefox使用的呈现引擎是 Mozilla 公司自制的 “Gecko” 引擎。Safari 和 chrome 使用的是 “Webkit” 引擎。 IE 使用的是 “trident” 引擎。webkit 是源代码开放的呈现引擎。
呈现引擎通过网络层获取到请求文档的内容后,进行如下流程的解析:
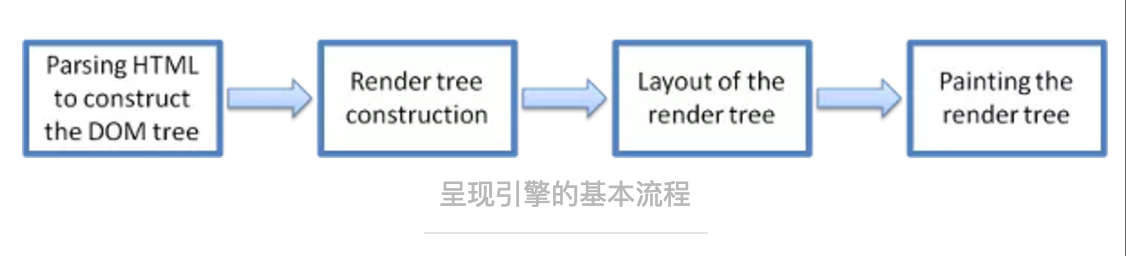
1. 解析HTML文档生成DOM构造树。在遍历DOM树的同时,会请求外链的样式文件和脚本文件等其他资源文件。CSS文件获取后同时解析该CSS文件,生成CSSOM树。
2. DOM树和CSSOM树结合后生成Render树。Render树是包含多个视觉属性(比如样式和尺寸)的矩形。矩形的排列顺序为节点在屏幕上显示的顺序。
3. Render树构建完成后,进入layout布局阶段。也就是对每个节点在屏幕上展示的位置分配具体的坐标。此时节点的位置是有层级覆盖的。
4. Render树的绘制。呈现引擎遍历Render树,由用户界面后端层将每个节点绘制出来。呈现引擎在绘制时不会等到整个HTML文件解析完毕,而是一边接收内容,一边绘制。
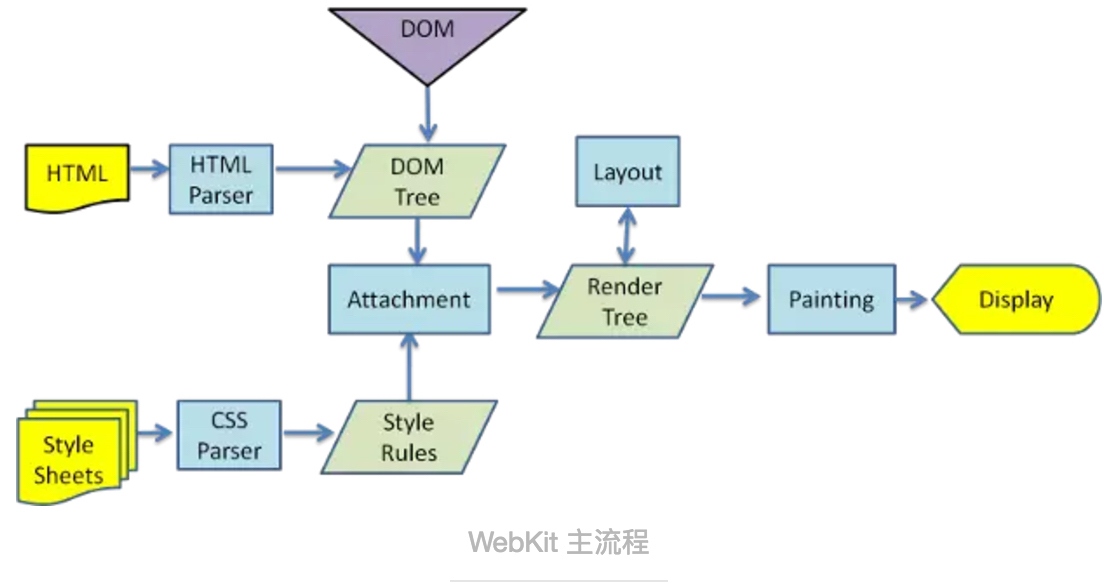
浏览器如何解析HTML文档
因为HTML语言的包容性,HTML解析器无法使用常规的自上而下或自下而上的解析器进行解析,所以使用自定义的解析器来解析。解析过程包括两个阶段:标记化和树构建。
标记化:是词法分析过程,将输入内容分析成多个标记。HTML标记包括起始标记,结束标记,属性名称和属性值。
树构建:标记生成器识别标记后,传递给树构建器,由树构造器进行处理,然后再接受下一个字符继续识别,继续传递给树构建器,如此循环直到输入的结束。

例如:下面HTML标记化过程
<html> <body> Hello world </body> </html>
初始状态是数据状态。遇到< 字符时,状态更改为“标记打开状态”。接收一个 a-z 字符会创建“起始标记”,状态更改为“标记名称状态”。这个状态会一直保持到接收 > 字符。在此期间接收的每个字符都会附加到新的标记名称上。在本例中,我们创建的标记是 html 标记。
遇到 > 标记时,会发送当前的标记,状态改回“数据状态”。 标记也会进行同样的处理。目前 html 和 body 标记均已发出。现在我们回到“数据状态”。接收到 Hello world 中的 H 字符时,将创建并发送字符标记,直到接收 中的 <。我们将为 Hello world 中的每个字符都发送一个字符标记。
现在我们回到“标记打开状态”。接收下一个输入字符 / 时,会创建 end tag token 并改为“标记名称状态”。我们会再次保持这个状态,直到接收 >。然后将发送新的标记,并回到“数据状态”。 输入也会进行同样的处理。
例如:下面HTML的树构建过程
<html> <body> Hello world </body> </html>
树构建阶段的输入是一个来自标记化阶段的标记序列。第一个模式是“initial mode”。接收 HTML 标记后转为“before html”模式,并在这个模式下重新处理此标记。这样会创建一个 HTMLHtmlElement 元素,并将其附加到 Document 根对象上。
然后状态将改为“before head”。此时我们接收“body”标记。即使我们的示例中没有“head”标记,系统也会隐式创建一个HTMLHeadElement,并将其添加到树中。
现在我们进入了“in head”模式,然后转入“after head”模式。系统对 body 标记进行重新处理,创建并插入 HTMLBodyElement,同时模式转变为“in body”。
现在,接收由“Hello world”字符串生成的一系列字符标记。接收第一个字符时会创建并插入“Text”节点,而其他字符也将附加到该节点。
接收 body 结束标记会触发“after body”模式。现在我们将接收 HTML 结束标记,然后进入“after after body”模式。接收到文件结束标记后,解析过程就此结束。
浏览器解析完成的操作
浏览器解析完成后,将文档标注为交互状态,并处理那些在文档解析完成后才执行的脚本。然后将文档状态设置为“完成”,并触发load加载事件。
参考文章:https://www.html5rocks.com/zh/tutorials/internals/howbrowserswork/
以上是关于浏览器的主要内容,如果未能解决你的问题,请参考以下文章